 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Roadmap for Big Model
Apr 02, 2022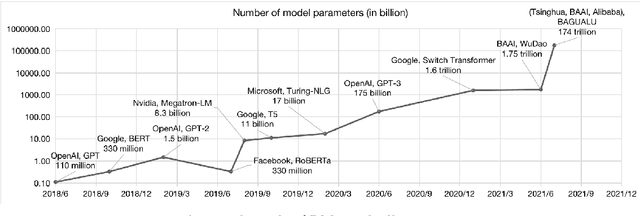
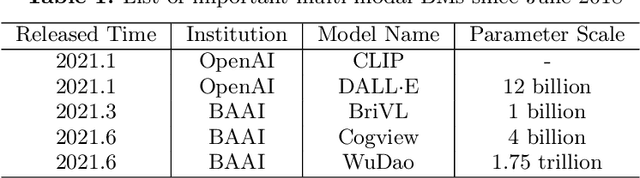
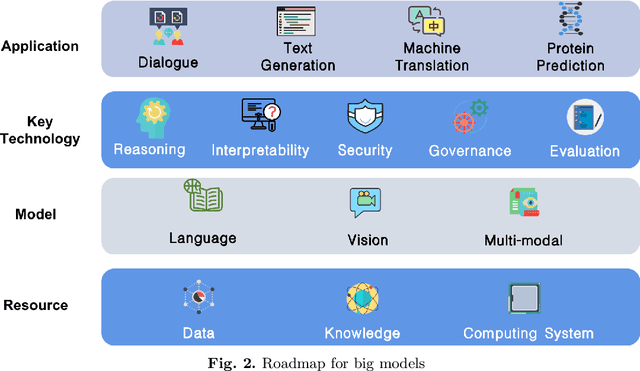
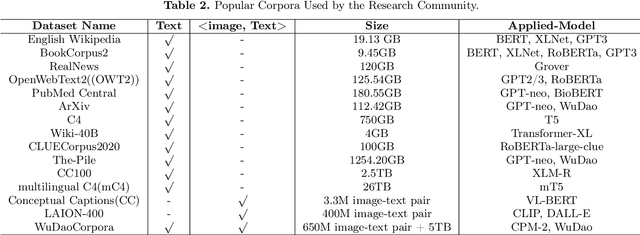
With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
WuDaoMM: A large-scale Multi-Modal Dataset for Pre-training models
Mar 30, 2022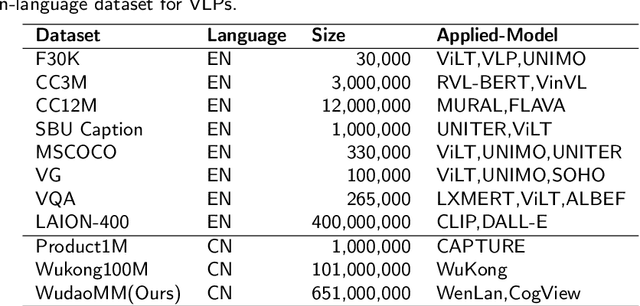


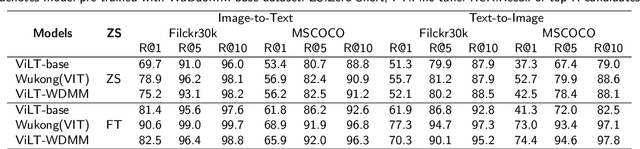
Compared with the domain-specific model, the vision-language pre-training models (VLPMs) have shown superior performance on downstream tasks with fast fine-tuning process. For example, ERNIE-ViL, Oscar and UNIMO trained VLPMs with a uniform transformers stack architecture and large amounts of image-text paired data, achieving remarkable results on downstream tasks such as image-text reference(IR and TR), vision question answering (VQA) and image captioning (IC) etc. During the training phase, VLPMs are always fed with a combination of multiple public datasets to meet the demand of large-scare training data. However, due to the unevenness of data distribution including size, task type and quality, using the mixture of multiple datasets for model training can be problematic. In this work, we introduce a large-scale multi-modal corpora named WuDaoMM, totally containing more than 650M image-text pairs. Specifically, about 600 million pairs of data are collected from multiple webpages in which image and caption present weak correlation, and the other 50 million strong-related image-text pairs are collected from some high-quality graphic websites. We also release a base version of WuDaoMM with 5 million strong-correlated image-text pairs, which is sufficient to support the common cross-modal model pre-training. Besides, we trained both an understanding and a generation vision-language (VL) model to test the dataset effectiveness. The results show that WuDaoMM can be applied as an efficient dataset for VLPMs, especially for the model in text-to-image generation task. The data is released at https://data.wudaoai.cn
Calculating Question Similarity is Enough:A New Method for KBQA Tasks
Nov 15, 2021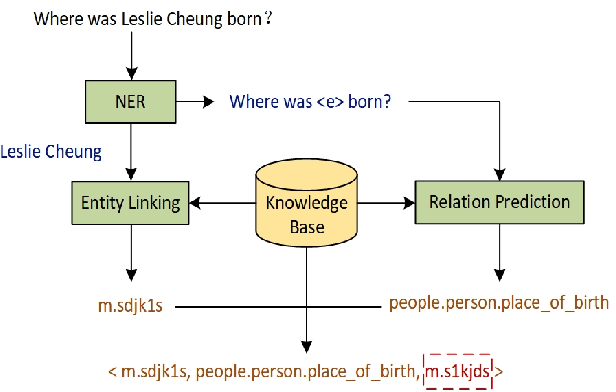
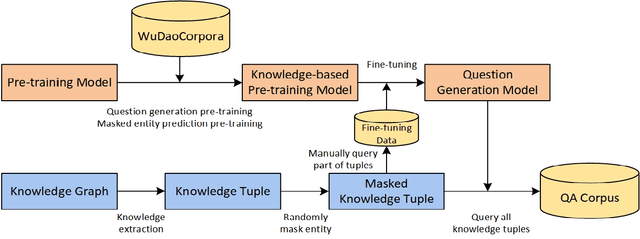

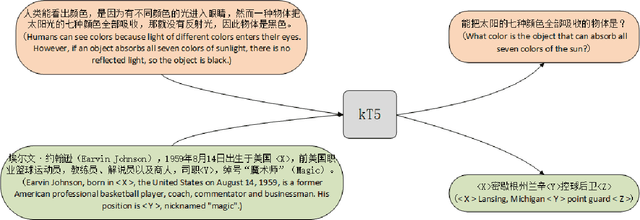
Knowledge Base Question Answering (KBQA) aims to answer natural language questions with the help of an external knowledge base. The core idea is to find the link between the internal knowledge behind questions and known triples of the knowledge base. The KBQA task pipeline contains several steps, including entity recognition, relationship extraction, and entity linking. This kind of pipeline method means that errors in any procedure will inevitably propagate to the final prediction. In order to solve the above problem, this paper proposes a Corpus Generation - Retrieve Method (CGRM) with Pre-training Language Model (PLM) and Knowledge Graph (KG). Firstly, based on the mT5 model, we designed two new pre-training tasks: knowledge masked language modeling and question generation based on the paragraph to obtain the knowledge enhanced T5 (kT5) model. Secondly, after preprocessing triples of knowledge graph with a series of heuristic rules, the kT5 model generates natural language QA pairs based on processed triples. Finally, we directly solve the QA by retrieving the synthetic dataset. We test our method on NLPCC-ICCPOL 2016 KBQA dataset, and the results show that our framework improves the performance of KBQA and the out straight-forward method is competitive with the state-of-the-art.