 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Towards the Information Boundary of Instruction Set: InfinityInstruct-Subject Technical Report
Jul 09, 2025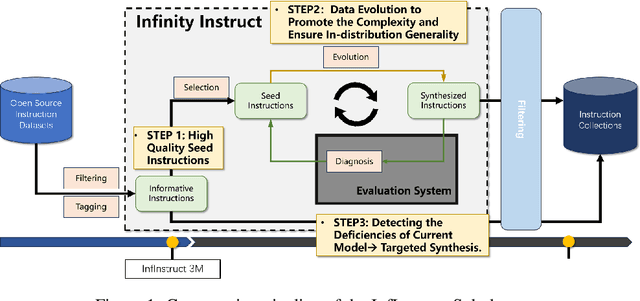
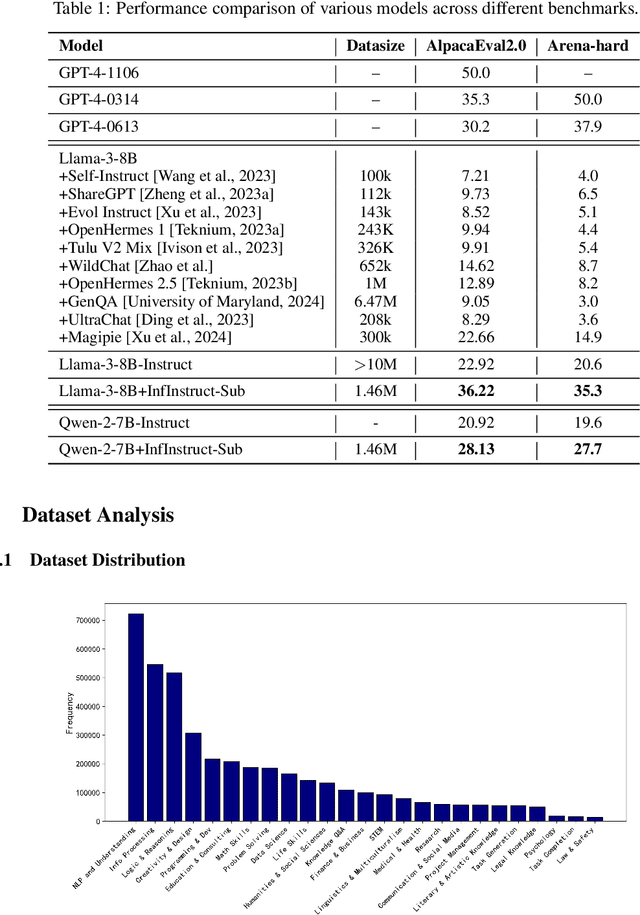

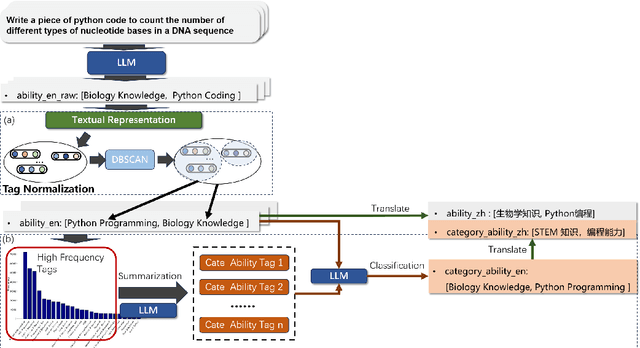
Instruction tuning has become a foundation for unlocking the capabilities of large-scale pretrained models and improving their performance on complex tasks. Thus, the construction of high-quality instruction datasets is crucial for enhancing model performance and generalizability. Although current instruction datasets have reached tens of millions of samples, models finetuned on them may still struggle with complex instruction following and tasks in rare domains. This is primarily due to limited expansion in both ``coverage'' (coverage of task types and knowledge areas) and ``depth'' (instruction complexity) of the instruction set. To address this issue, we propose a systematic instruction data construction framework, which integrates a hierarchical labeling system, an informative seed selection algorithm, an evolutionary data synthesis process, and a model deficiency diagnosis with targeted data generation. These components form an iterative closed-loop to continuously enhance the coverage and depth of instruction data. Based on this framework, we construct InfinityInstruct-Subject, a high-quality dataset containing ~1.5 million instructions. Experiments on multiple foundation models and benchmark tasks demonstrate its effectiveness in improving instruction-following capabilities. Further analyses suggest that InfinityInstruct-Subject shows enlarged coverage and depth compared to comparable synthesized instruction datasets. Our work lays a theoretical and practical foundation for the efficient, continuous evolution of instruction datasets, moving from data quantity expansion to qualitative improvement.
PerfTracker: Online Performance Troubleshooting for Large-scale Model Training in Production
Jun 12, 2025



Troubleshooting performance problems of large model training (LMT) is immensely challenging, due to unprecedented scales of modern GPU clusters, the complexity of software-hardware interactions, and the data intensity of the training process. Existing troubleshooting approaches designed for traditional distributed systems or datacenter networks fall short and can hardly apply to real-world training systems. In this paper, we present PerfTracker, the first online troubleshooting system utilizing fine-grained profiling, to diagnose performance issues of large-scale model training in production. PerfTracker can diagnose performance issues rooted in both hardware (e.g., GPUs and their interconnects) and software (e.g., Python functions and GPU operations). It scales to LMT on modern GPU clusters. PerfTracker effectively summarizes runtime behavior patterns of fine-grained LMT functions via online profiling, and leverages differential observability to localize the root cause with minimal production impact. PerfTracker has been deployed as a production service for large-scale GPU clusters of O(10, 000) GPUs (product homepage https://help.aliyun.com/zh/pai/user-guide/perftracker-online-performance-analysis-diagnostic-tool). It has been used to diagnose a variety of difficult performance issues.
Conformal Uncertainty Indicator for Continual Test-Time Adaptation
Feb 05, 2025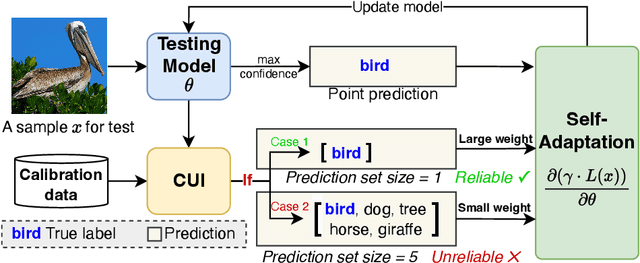
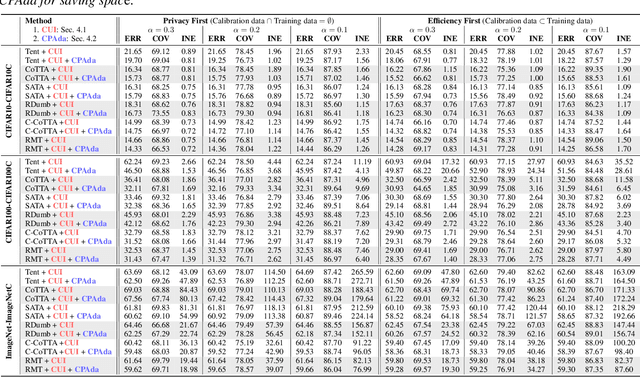
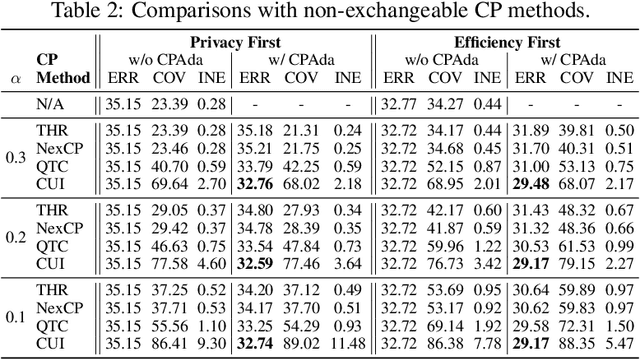
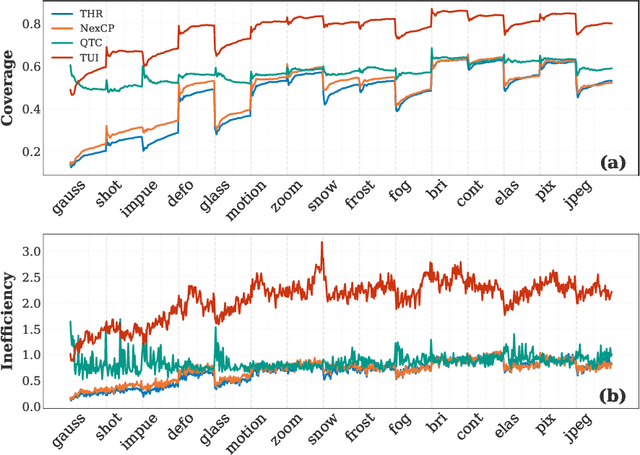
Continual Test-Time Adaptation (CTTA) aims to adapt models to sequentially changing domains during testing, relying on pseudo-labels for self-adaptation. However, incorrect pseudo-labels can accumulate, leading to performance degradation. To address this, we propose a Conformal Uncertainty Indicator (CUI) for CTTA, leveraging Conformal Prediction (CP) to generate prediction sets that include the true label with a specified coverage probability. Since domain shifts can lower the coverage than expected, making CP unreliable, we dynamically compensate for the coverage by measuring both domain and data differences. Reliable pseudo-labels from CP are then selectively utilized to enhance adaptation. Experiments confirm that CUI effectively estimates uncertainty and improves adaptation performance across various existing CTTA methods.
CCI3.0-HQ: a large-scale Chinese dataset of high quality designed for pre-training large language models
Oct 24, 2024We present CCI3.0-HQ (https://huggingface.co/datasets/BAAI/CCI3-HQ), a high-quality 500GB subset of the Chinese Corpora Internet 3.0 (CCI3.0)(https://huggingface.co/datasets/BAAI/CCI3-Data), developed using a novel two-stage hybrid filtering pipeline that significantly enhances data quality. To evaluate its effectiveness, we trained a 0.5B parameter model from scratch on 100B tokens across various datasets, achieving superior performance on 10 benchmarks in a zero-shot setting compared to CCI3.0, SkyPile, and WanjuanV1. The high-quality filtering process effectively distills the capabilities of the Qwen2-72B-instruct model into a compact 0.5B model, attaining optimal F1 scores for Chinese web data classification. We believe this open-access dataset will facilitate broader access to high-quality language models.
Beyond IID: Optimizing Instruction Learning from the Perspective of Instruction Interaction and Dependency
Sep 11, 2024With the availability of various instruction datasets, a pivotal challenge is how to effectively select and integrate these instructions to fine-tune large language models (LLMs). Previous research mainly focuses on selecting individual high-quality instructions. However, these works overlooked the joint interactions and dependencies between different categories of instructions, leading to suboptimal selection strategies. Moreover, the nature of these interaction patterns remains largely unexplored, let alone optimize the instruction set with regard to them. To fill these gaps, in this paper, we: (1) systemically investigate interaction and dependency patterns between different categories of instructions, (2) manage to optimize the instruction set concerning the interaction patterns using a linear programming-based method, and optimize the learning schema of SFT using an instruction dependency taxonomy guided curriculum learning. Experimental results across different LLMs demonstrate improved performance over strong baselines on widely adopted benchmarks.
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
Aug 13, 2024In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 8*16B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 8*16B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.
Boosting Large-scale Parallel Training Efficiency with C4: A Communication-Driven Approach
Jun 07, 2024

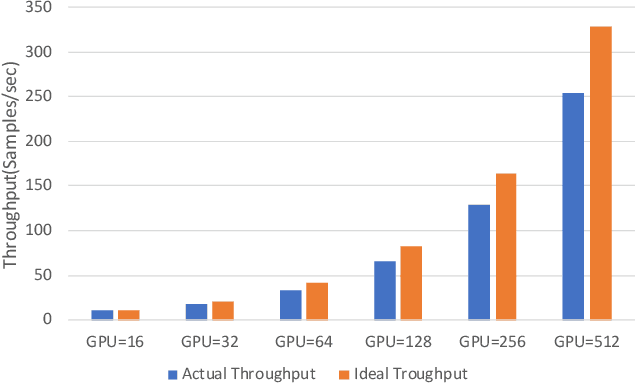

The emergence of Large Language Models (LLMs) has necessitated the adoption of parallel training techniques, involving the deployment of thousands of GPUs to train a single model. Unfortunately, we have found that the efficiency of current parallel training is often suboptimal, largely due to the following two main issues. Firstly, hardware failures are inevitable, leading to interruptions in the training tasks. The inability to quickly identify the faulty components results in a substantial waste of GPU resources. Secondly, since GPUs must wait for parameter synchronization to complete before proceeding to the next round of computation, network congestions can greatly increase the waiting time for GPUs. To address these challenges, this paper introduces a communication-driven solution, namely the C4. The key insights of C4 are two folds. First, in parallel training, collective communication exhibits periodic and homogeneous characteristics, so any anomalies are certainly due to some form of hardware malfunction. By leveraging this feature, C4 can rapidly identify the faulty components, swiftly isolate the anomaly, and restart the task, thereby avoiding resource wastage caused by delays in anomaly detection. Second, the predictable communication model of collective communication, involving few large flows, allows C4 to efficiently execute traffic planning, substantially reducing network congestion. C4 has been extensively implemented across our production systems, cutting error-induced overhead by roughly 30% and enhancing runtime performance by about 15% for certain applications with moderate communication costs.
Llumnix: Dynamic Scheduling for Large Language Model Serving
Jun 05, 2024


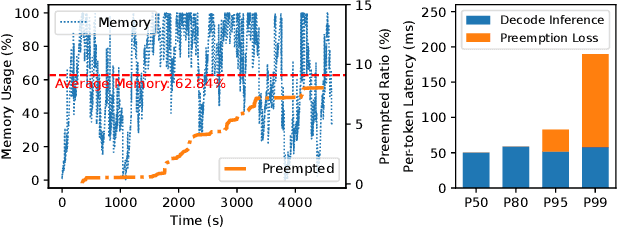
Inference serving for large language models (LLMs) is the key to unleashing their potential in people's daily lives. However, efficient LLM serving remains challenging today because the requests are inherently heterogeneous and unpredictable in terms of resource and latency requirements, as a result of the diverse applications and the dynamic execution nature of LLMs. Existing systems are fundamentally limited in handling these characteristics and cause problems such as severe queuing delays, poor tail latencies, and SLO violations. We introduce Llumnix, an LLM serving system that reacts to such heterogeneous and unpredictable requests by runtime rescheduling across multiple model instances. Similar to context switching across CPU cores in modern operating systems, Llumnix reschedules requests to improve load balancing and isolation, mitigate resource fragmentation, and differentiate request priorities and SLOs. Llumnix implements the rescheduling with an efficient and scalable live migration mechanism for requests and their in-memory states, and exploits it in a dynamic scheduling policy that unifies the multiple rescheduling scenarios elegantly. Our evaluations show that Llumnix improves tail latencies by an order of magnitude, accelerates high-priority requests by up to 1.5x, and delivers up to 36% cost savings while achieving similar tail latencies, compared against state-of-the-art LLM serving systems. Llumnix is publicly available at https://github.com/AlibabaPAI/llumnix.
Variational Continual Test-Time Adaptation
Feb 13, 2024



The prior drift is crucial in Continual Test-Time Adaptation (CTTA) methods that only use unlabeled test data, as it can cause significant error propagation. In this paper, we introduce VCoTTA, a variational Bayesian approach to measure uncertainties in CTTA. At the source stage, we transform a pre-trained deterministic model into a Bayesian Neural Network (BNN) via a variational warm-up strategy, injecting uncertainties into the model. During the testing time, we employ a mean-teacher update strategy using variational inference for the student model and exponential moving average for the teacher model. Our novel approach updates the student model by combining priors from both the source and teacher models. The evidence lower bound is formulated as the cross-entropy between the student and teacher models, along with the Kullback-Leibler (KL) divergence of the prior mixture. Experimental results on three datasets demonstrate the method's effectiveness in mitigating prior drift within the CTTA framework.
ROAM: memory-efficient large DNN training via optimized operator ordering and memory layout
Oct 30, 2023As deep learning models continue to increase in size, the memory requirements for training have surged. While high-level techniques like offloading, recomputation, and compression can alleviate memory pressure, they also introduce overheads. However, a memory-efficient execution plan that includes a reasonable operator execution order and tensor memory layout can significantly increase the models' memory efficiency and reduce overheads from high-level techniques. In this paper, we propose ROAM which operates on computation graph level to derive memory-efficient execution plan with optimized operator order and tensor memory layout for models. We first propose sophisticated theories that carefully consider model structure and training memory load to support optimization for large complex graphs that have not been well supported in the past. An efficient tree-based algorithm is further proposed to search task divisions automatically, along with delivering high performance and effectiveness to solve the problem. Experiments show that ROAM achieves a substantial memory reduction of 35.7%, 13.3%, and 27.2% compared to Pytorch and two state-of-the-art methods and offers a remarkable 53.7x speedup. The evaluation conducted on the expansive GPT2-XL further validates ROAM's scalability.