 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomalyNCD: Towards Novel Anomaly Class Discovery in Industrial Scenarios
Oct 18, 2024



In the industrial scenario, anomaly detection could locate but cannot classify anomalies. To complete their capability, we study to automatically discover and recognize visual classes of industrial anomalies. In terms of multi-class anomaly classification, previous methods cluster anomalies represented by frozen pre-trained models but often fail due to poor discrimination. Novel class discovery (NCD) has the potential to tackle this. However, it struggles with non-prominent and semantically weak anomalies that challenge network learning focus. To address these, we introduce AnomalyNCD, a multi-class anomaly classification framework compatible with existing anomaly detection methods. This framework learns anomaly-specific features and classifies anomalies in a self-supervised manner. Initially, a technique called Main Element Binarization (MEBin) is first designed, which segments primary anomaly regions into masks to alleviate the impact of incorrect detections on learning. Subsequently, we employ mask-guided contrastive representation learning to improve feature discrimination, which focuses network attention on isolated anomalous regions and reduces the confusion of erroneous inputs through re-corrected pseudo labels. Finally, to enable flexible classification at both region and image levels during inference, we develop a region merging strategy that determines the overall image category based on the classified anomaly regions. Our method outperforms the state-of-the-art works on the MVTec AD and MTD datasets. Compared with the current methods, AnomalyNCD combined with zero-shot anomaly detection method achieves a 10.8% $F_1$ gain, 8.8% NMI gain, and 9.5% ARI gain on MVTec AD, 12.8% $F_1$ gain, 5.7% NMI gain, and 10.8% ARI gain on MTD. The source code is available at https://github.com/HUST-SLOW/AnomalyNCD.
Llumnix: Dynamic Scheduling for Large Language Model Serving
Jun 05, 2024


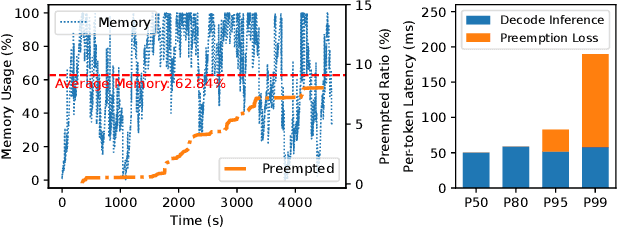
Inference serving for large language models (LLMs) is the key to unleashing their potential in people's daily lives. However, efficient LLM serving remains challenging today because the requests are inherently heterogeneous and unpredictable in terms of resource and latency requirements, as a result of the diverse applications and the dynamic execution nature of LLMs. Existing systems are fundamentally limited in handling these characteristics and cause problems such as severe queuing delays, poor tail latencies, and SLO violations. We introduce Llumnix, an LLM serving system that reacts to such heterogeneous and unpredictable requests by runtime rescheduling across multiple model instances. Similar to context switching across CPU cores in modern operating systems, Llumnix reschedules requests to improve load balancing and isolation, mitigate resource fragmentation, and differentiate request priorities and SLOs. Llumnix implements the rescheduling with an efficient and scalable live migration mechanism for requests and their in-memory states, and exploits it in a dynamic scheduling policy that unifies the multiple rescheduling scenarios elegantly. Our evaluations show that Llumnix improves tail latencies by an order of magnitude, accelerates high-priority requests by up to 1.5x, and delivers up to 36% cost savings while achieving similar tail latencies, compared against state-of-the-art LLM serving systems. Llumnix is publicly available at https://github.com/AlibabaPAI/llumnix.
MuSc: Zero-Shot Industrial Anomaly Classification and Segmentation with Mutual Scoring of the Unlabeled Images
Jan 30, 2024



This paper studies zero-shot anomaly classification (AC) and segmentation (AS) in industrial vision. We reveal that the abundant normal and abnormal cues implicit in unlabeled test images can be exploited for anomaly determination, which is ignored by prior methods. Our key observation is that for the industrial product images, the normal image patches could find a relatively large number of similar patches in other unlabeled images, while the abnormal ones only have a few similar patches. We leverage such a discriminative characteristic to design a novel zero-shot AC/AS method by Mutual Scoring (MuSc) of the unlabeled images, which does not need any training or prompts. Specifically, we perform Local Neighborhood Aggregation with Multiple Degrees (LNAMD) to obtain the patch features that are capable of representing anomalies in varying sizes. Then we propose the Mutual Scoring Mechanism (MSM) to leverage the unlabeled test images to assign the anomaly score to each other. Furthermore, we present an optimization approach named Re-scoring with Constrained Image-level Neighborhood (RsCIN) for image-level anomaly classification to suppress the false positives caused by noises in normal images. The superior performance on the challenging MVTec AD and VisA datasets demonstrates the effectiveness of our approach. Compared with the state-of-the-art zero-shot approaches, MuSc achieves a $\textbf{21.1%}$ PRO absolute gain (from 72.7% to 93.8%) on MVTec AD, a $\textbf{19.4%}$ pixel-AP gain and a $\textbf{14.7%}$ pixel-AUROC gain on VisA. In addition, our zero-shot approach outperforms most of the few-shot approaches and is comparable to some one-class methods. Code is available at https://github.com/xrli-U/MuSc.
Gated Mechanism Enhanced Multi-Task Learning for Dialog Routing
Apr 07, 2023Currently, human-bot symbiosis dialog systems, e.g., pre- and after-sales in E-commerce, are ubiquitous, and the dialog routing component is essential to improve the overall efficiency, reduce human resource cost, and enhance user experience. Although most existing methods can fulfil this requirement, they can only model single-source dialog data and cannot effectively capture the underlying knowledge of relations among data and subtasks. In this paper, we investigate this important problem by thoroughly mining both the data-to-task and task-to-task knowledge among various kinds of dialog data. To achieve the above targets, we propose a Gated Mechanism enhanced Multi-task Model (G3M), specifically including a novel dialog encoder and two tailored gated mechanism modules. The proposed method can play the role of hierarchical information filtering and is non-invasive to existing dialog systems. Based on two datasets collected from real world applications, extensive experimental results demonstrate the effectiveness of our method, which achieves the state-of-the-art performance by improving 8.7\%/11.8\% on RMSE metric and 2.2\%/4.4\% on F1 metric.
Multi-Domain Transformer-Based Counterfactual Augmentation for Earnings Call Analysis
Dec 03, 2021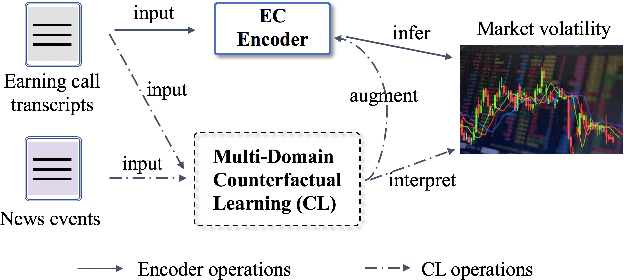

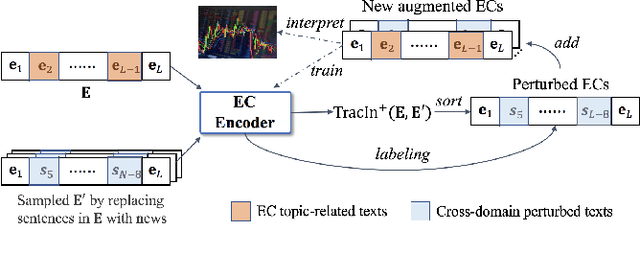
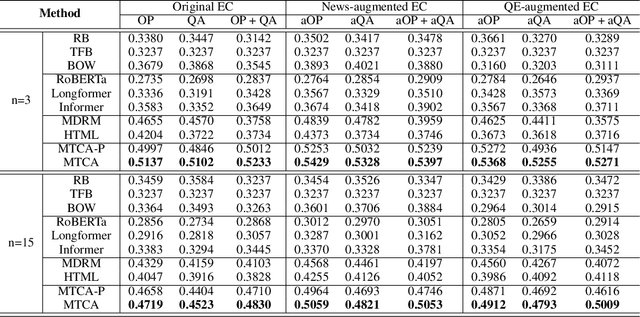
Earnings call (EC), as a periodic teleconference of a publicly-traded company, has been extensively studied as an essential market indicator because of its high analytical value in corporate fundamentals. The recent emergence of deep learning techniques has shown great promise in creating automated pipelines to benefit the EC-supported financial applications. However, these methods presume all included contents to be informative without refining valuable semantics from long-text transcript and suffer from EC scarcity issue. Meanwhile, these black-box methods possess inherent difficulties in providing human-understandable explanations. To this end, in this paper, we propose a Multi-Domain Transformer-Based Counterfactual Augmentation, named MTCA, to address the above problems. Specifically, we first propose a transformer-based EC encoder to attentively quantify the task-inspired significance of critical EC content for market inference. Then, a multi-domain counterfactual learning framework is developed to evaluate the gradient-based variations after we perturb limited EC informative texts with plentiful cross-domain documents, enabling MTCA to perform unsupervised data augmentation. As a bonus, we discover a way to use non-training data as instance-based explanations for which we show the result with case studies. Extensive experiments on the real-world financial datasets demonstrate the effectiveness of interpretable MTCA for improving the volatility evaluation ability of the state-of-the-art by 14.2\% in accuracy.
On Sample Based Explanation Methods for NLP:Efficiency, Faithfulness, and Semantic Evaluation
Jun 09, 2021
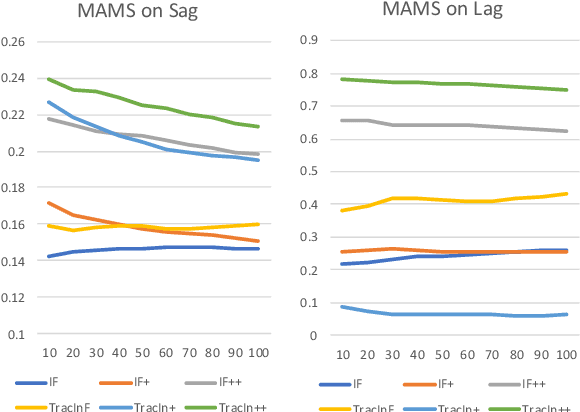

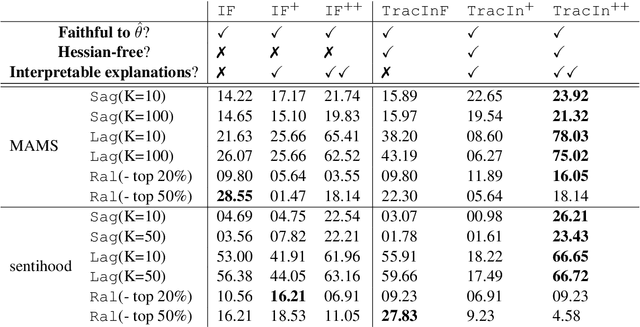
In the recent advances of natural language processing, the scale of the state-of-the-art models and datasets is usually extensive, which challenges the application of sample-based explanation methods in many aspects, such as explanation interpretability, efficiency, and faithfulness. In this work, for the first time, we can improve the interpretability of explanations by allowing arbitrary text sequences as the explanation unit. On top of this, we implement a hessian-free method with a model faithfulness guarantee. Finally, to compare our method with the others, we propose a semantic-based evaluation metric that can better align with humans' judgment of explanations than the widely adopted diagnostic or re-training measures. The empirical results on multiple real data sets demonstrate the proposed method's superior performance to popular explanation techniques such as Influence Function or TracIn on semantic evaluation.
DialogAct2Vec: Towards End-to-End Dialogue Agent by Multi-Task Representation Learning
Nov 11, 2019

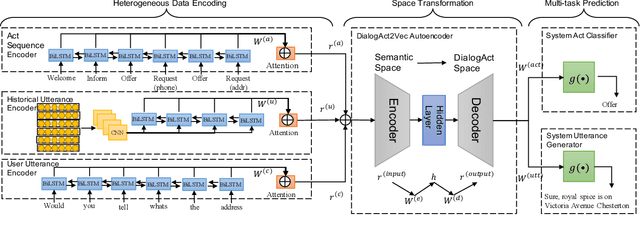
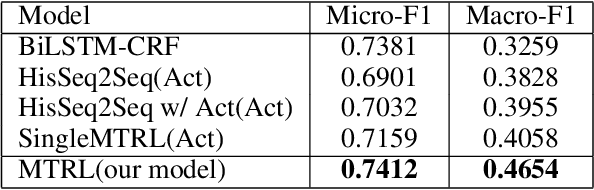
In end-to-end dialogue modeling and agent learning, it is important to (1) effectively learn knowledge from data, and (2) fully utilize heterogeneous information, e.g., dialogue act flow and utterances. However, the majority of existing methods cannot simultaneously satisfy the two conditions. For example, rule definition and data labeling during system design take too much manual work, and sequence-to-sequence methods only model one-side utterance information. In this paper, we propose a novel joint end-to-end model by multi-task representation learning, which can capture the knowledge from heterogeneous information through automatically learning knowledgeable low-dimensional embeddings from data, named with DialogAct2Vec. The model requires little manual work for intervention in system design and we find that the multi-task learning can greatly improve the effectiveness of representation learning. Extensive experiments on a public dataset for restaurant reservation show that the proposed method leads to significant improvements against the state-of-the-art baselines on both the act prediction task and utterance prediction task.
Towards End-to-End Learning for Efficient Dialogue Agent by Modeling Looking-ahead Ability
Aug 15, 2019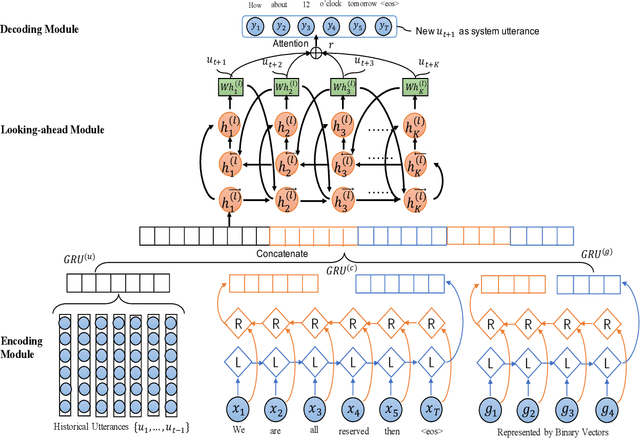
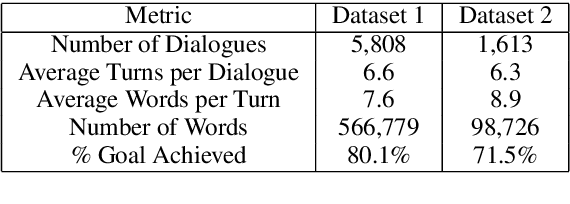
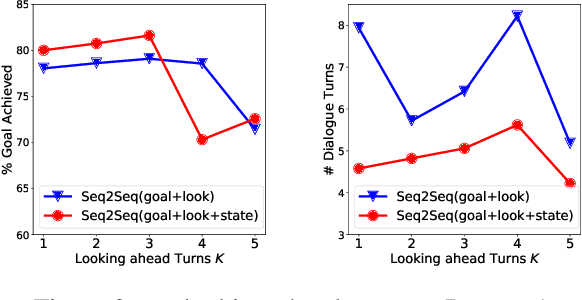
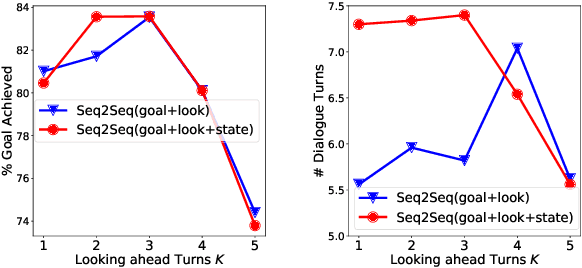
Learning an efficient manager of dialogue agent from data with little manual intervention is important, especially for goal-oriented dialogues. However, existing methods either take too many manual efforts (e.g. reinforcement learning methods) or cannot guarantee the dialogue efficiency (e.g. sequence-to-sequence methods). In this paper, we address this problem by proposing a novel end-to-end learning model to train a dialogue agent that can look ahead for several future turns and generate an optimal response to make the dialogue efficient. Our method is data-driven and does not require too much manual work for intervention during system design. We evaluate our method on two datasets of different scenarios and the experimental results demonstrate the efficiency of our model.