 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogAct2Vec: Towards End-to-End Dialogue Agent by Multi-Task Representation Learning
Nov 11, 2019

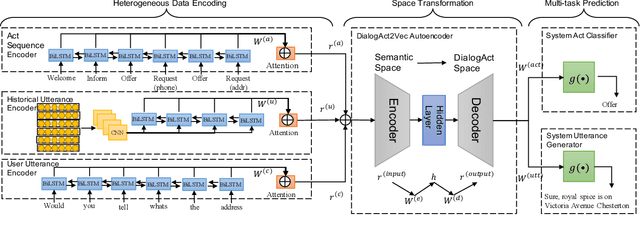
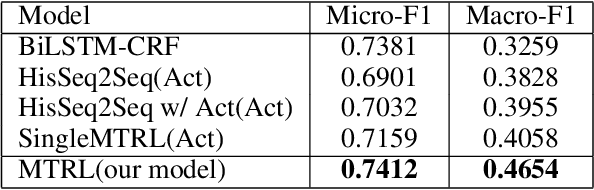
In end-to-end dialogue modeling and agent learning, it is important to (1) effectively learn knowledge from data, and (2) fully utilize heterogeneous information, e.g., dialogue act flow and utterances. However, the majority of existing methods cannot simultaneously satisfy the two conditions. For example, rule definition and data labeling during system design take too much manual work, and sequence-to-sequence methods only model one-side utterance information. In this paper, we propose a novel joint end-to-end model by multi-task representation learning, which can capture the knowledge from heterogeneous information through automatically learning knowledgeable low-dimensional embeddings from data, named with DialogAct2Vec. The model requires little manual work for intervention in system design and we find that the multi-task learning can greatly improve the effectiveness of representation learning. Extensive experiments on a public dataset for restaurant reservation show that the proposed method leads to significant improvements against the state-of-the-art baselines on both the act prediction task and utterance prediction task.