 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathMistake Checker: A Comprehensive Demonstration for Step-by-Step Math Problem Mistake Finding by Prompt-Guided LLMs
Mar 06, 2025We propose a novel system, MathMistake Checker, designed to automate step-by-step mistake finding in mathematical problems with lengthy answers through a two-stage process. The system aims to simplify grading, increase efficiency, and enhance learning experiences from a pedagogical perspective. It integrates advanced technologies, including computer vision and the chain-of-thought capabilities of the latest large language models (LLMs). Our system supports open-ended grading without reference answers and promotes personalized learning by providing targeted feedback. We demonstrate its effectiveness across various types of math problems, such as calculation and word problems.
RAG4ITOps: A Supervised Fine-Tunable and Comprehensive RAG Framework for IT Operations and Maintenance
Oct 21, 2024With the ever-increasing demands on Question Answering (QA) systems for IT operations and maintenance, an efficient and supervised fine-tunable framework is necessary to ensure the data security, private deployment and continuous upgrading. Although Large Language Models (LLMs) have notably improved the open-domain QA's performance, how to efficiently handle enterprise-exclusive corpora and build domain-specific QA systems are still less-studied for industrial applications. In this paper, we propose a general and comprehensive framework based on Retrieval Augmented Generation (RAG) and facilitate the whole business process of establishing QA systems for IT operations and maintenance. In accordance with the prevailing RAG method, our proposed framework, named with RAG4ITOps, composes of two major stages: (1) Models Fine-tuning \& Data Vectorization, and (2) Online QA System Process. At the Stage 1, we leverage a contrastive learning method with two negative sampling strategies to fine-tune the embedding model, and design the instruction templates to fine-tune the LLM with a Retrieval Augmented Fine-Tuning method. At the Stage 2, an efficient process of QA system is built for serving. We collect enterprise-exclusive corpora from the domain of cloud computing, and the extensive experiments show that our method achieves superior results than counterparts on two kinds of QA tasks. Our experiment also provide a case for applying the RAG4ITOps to real-world enterprise-level applications.
LLMs can Find Mathematical Reasoning Mistakes by Pedagogical Chain-of-Thought
May 09, 2024Self-correction is emerging as a promising approach to mitigate the issue of hallucination in Large Language Models (LLMs). To facilitate effective self-correction, recent research has proposed mistake detection as its initial step. However, current literature suggests that LLMs often struggle with reliably identifying reasoning mistakes when using simplistic prompting strategies. To address this challenge, we introduce a unique prompting strategy, termed the Pedagogical Chain-of-Thought (PedCoT), which is specifically designed to guide the identification of reasoning mistakes, particularly mathematical reasoning mistakes. PedCoT consists of pedagogical principles for prompts (PPP) design, two-stage interaction process (TIP) and grounded PedCoT prompts, all inspired by the educational theory of the Bloom Cognitive Model (BCM). We evaluate our approach on two public datasets featuring math problems of varying difficulty levels. The experiments demonstrate that our zero-shot prompting strategy significantly outperforms strong baselines. The proposed method can achieve the goal of reliable mathematical mistake identification and provide a foundation for automatic math answer grading. The results underscore the significance of educational theory, serving as domain knowledge, in guiding prompting strategy design for addressing challenging tasks with LLMs effectively.
Gated Mechanism Enhanced Multi-Task Learning for Dialog Routing
Apr 07, 2023Currently, human-bot symbiosis dialog systems, e.g., pre- and after-sales in E-commerce, are ubiquitous, and the dialog routing component is essential to improve the overall efficiency, reduce human resource cost, and enhance user experience. Although most existing methods can fulfil this requirement, they can only model single-source dialog data and cannot effectively capture the underlying knowledge of relations among data and subtasks. In this paper, we investigate this important problem by thoroughly mining both the data-to-task and task-to-task knowledge among various kinds of dialog data. To achieve the above targets, we propose a Gated Mechanism enhanced Multi-task Model (G3M), specifically including a novel dialog encoder and two tailored gated mechanism modules. The proposed method can play the role of hierarchical information filtering and is non-invasive to existing dialog systems. Based on two datasets collected from real world applications, extensive experimental results demonstrate the effectiveness of our method, which achieves the state-of-the-art performance by improving 8.7\%/11.8\% on RMSE metric and 2.2\%/4.4\% on F1 metric.
Leveraging Key Information Modeling to Improve Less-Data Constrained News Headline Generation via Duality Fine-Tuning
Oct 10, 2022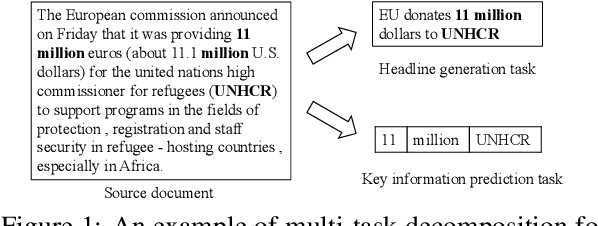
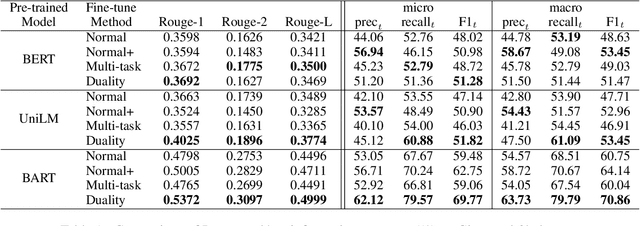
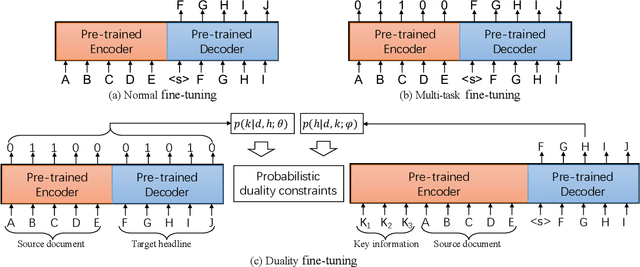
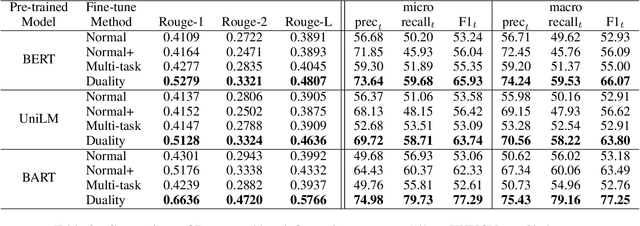
Recent language generative models are mostly trained on large-scale datasets, while in some real scenarios, the training datasets are often expensive to obtain and would be small-scale. In this paper we investigate the challenging task of less-data constrained generation, especially when the generated news headlines are short yet expected by readers to keep readable and informative simultaneously. We highlight the key information modeling task and propose a novel duality fine-tuning method by formally defining the probabilistic duality constraints between key information prediction and headline generation tasks. The proposed method can capture more information from limited data, build connections between separate tasks, and is suitable for less-data constrained generation tasks. Furthermore, the method can leverage various pre-trained generative regimes, e.g., autoregressive and encoder-decoder models. We conduct extensive experiments to demonstrate that our method is effective and efficient to achieve improved performance in terms of language modeling metric and informativeness correctness metric on two public datasets.
OS-MSL: One Stage Multimodal Sequential Link Framework for Scene Segmentation and Classification
Jul 04, 2022
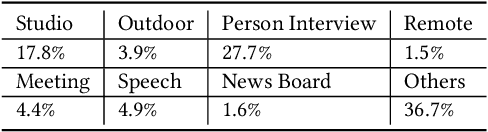
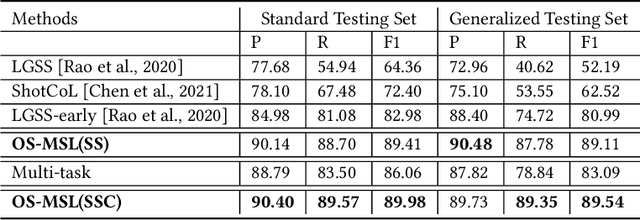
Scene segmentation and classification (SSC) serve as a critical step towards the field of video structuring analysis. Intuitively, jointly learning of these two tasks can promote each other by sharing common information. However, scene segmentation concerns more on the local difference between adjacent shots while classification needs the global representation of scene segments, which probably leads to the model dominated by one of the two tasks in the training phase. In this paper, from an alternate perspective to overcome the above challenges, we unite these two tasks into one task by a new form of predicting shots link: a link connects two adjacent shots, indicating that they belong to the same scene or category. To the end, we propose a general One Stage Multimodal Sequential Link Framework (OS-MSL) to both distinguish and leverage the two-fold semantics by reforming the two learning tasks into a unified one. Furthermore, we tailor a specific module called DiffCorrNet to explicitly extract the information of differences and correlations among shots. Extensive experiments on a brand-new large scale dataset collected from real-world applications, and MovieScenes are conducted. Both the results demonstrate the effectiveness of our proposed method against strong baselines.
RAAT: Relation-Augmented Attention Transformer for Relation Modeling in Document-Level Event Extraction
Jun 07, 2022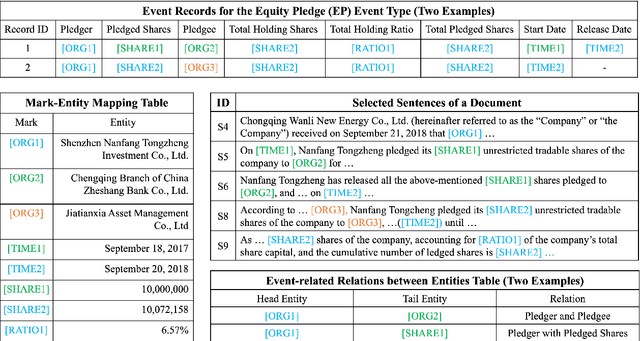
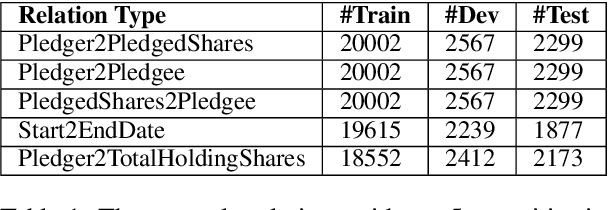
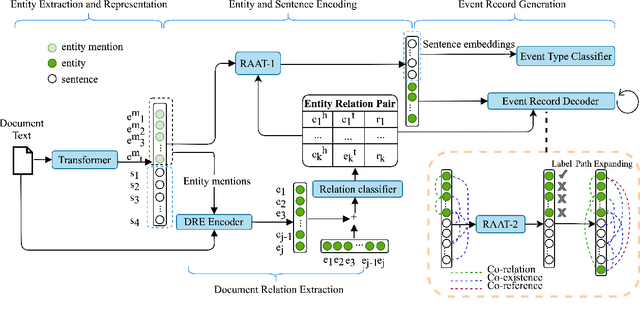
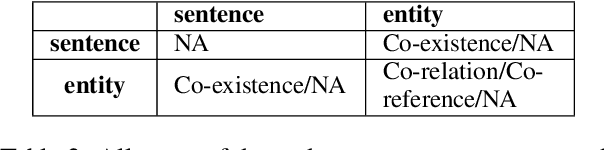
In document-level event extraction (DEE) task, event arguments always scatter across sentences (across-sentence issue) and multiple events may lie in one document (multi-event issue). In this paper, we argue that the relation information of event arguments is of great significance for addressing the above two issues, and propose a new DEE framework which can model the relation dependencies, called Relation-augmented Document-level Event Extraction (ReDEE). More specifically, this framework features a novel and tailored transformer, named as Relation-augmented Attention Transformer (RAAT). RAAT is scalable to capture multi-scale and multi-amount argument relations. To further leverage relation information, we introduce a separate event relation prediction task and adopt multi-task learning method to explicitly enhance event extraction performance. Extensive experiments demonstrate the effectiveness of the proposed method, which can achieve state-of-the-art performance on two public datasets. Our code is available at https://github. com/TencentYoutuResearch/RAAT.
Leveraging Tripartite Interaction Information from Live Stream E-Commerce for Improving Product Recommendation
Jun 07, 2021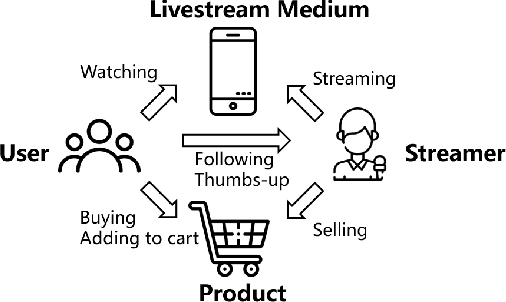

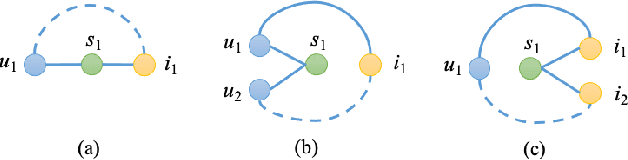
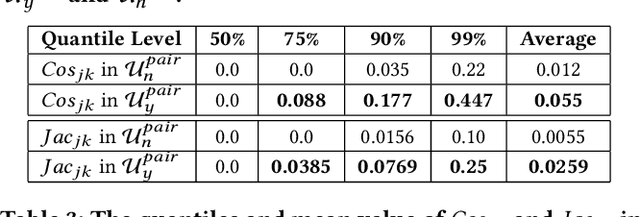
Recently, a new form of online shopping becomes more and more popular, which combines live streaming with E-Commerce activity. The streamers introduce products and interact with their audiences, and hence greatly improve the performance of selling products. Despite of the successful applications in industries, the live stream E-commerce has not been well studied in the data science community. To fill this gap, we investigate this brand-new scenario and collect a real-world Live Stream E-Commerce (LSEC) dataset. Different from conventional E-commerce activities, the streamers play a pivotal role in the LSEC events. Hence, the key is to make full use of rich interaction information among streamers, users, and products. We first conduct data analysis on the tripartite interaction data and quantify the streamer's influence on users' purchase behavior. Based on the analysis results, we model the tripartite information as a heterogeneous graph, which can be decomposed to multiple bipartite graphs in order to better capture the influence. We propose a novel Live Stream E-Commerce Graph Neural Network framework (LSEC-GNN) to learn the node representations of each bipartite graph, and further design a multi-task learning approach to improve product recommendation. Extensive experiments on two real-world datasets with different scales show that our method can significantly outperform various baseline approaches.
DialogAct2Vec: Towards End-to-End Dialogue Agent by Multi-Task Representation Learning
Nov 11, 2019

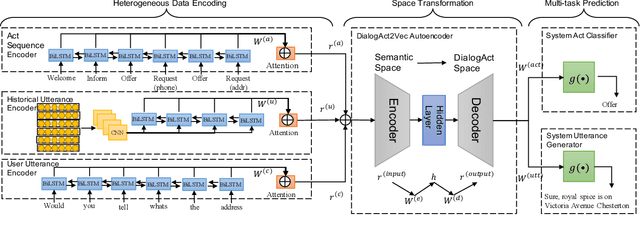
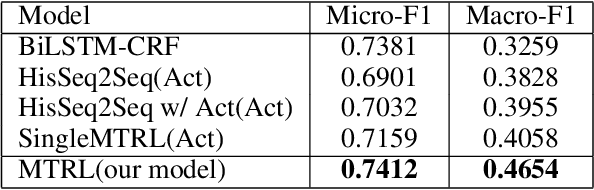
In end-to-end dialogue modeling and agent learning, it is important to (1) effectively learn knowledge from data, and (2) fully utilize heterogeneous information, e.g., dialogue act flow and utterances. However, the majority of existing methods cannot simultaneously satisfy the two conditions. For example, rule definition and data labeling during system design take too much manual work, and sequence-to-sequence methods only model one-side utterance information. In this paper, we propose a novel joint end-to-end model by multi-task representation learning, which can capture the knowledge from heterogeneous information through automatically learning knowledgeable low-dimensional embeddings from data, named with DialogAct2Vec. The model requires little manual work for intervention in system design and we find that the multi-task learning can greatly improve the effectiveness of representation learning. Extensive experiments on a public dataset for restaurant reservation show that the proposed method leads to significant improvements against the state-of-the-art baselines on both the act prediction task and utterance prediction task.
Towards End-to-End Learning for Efficient Dialogue Agent by Modeling Looking-ahead Ability
Aug 15, 2019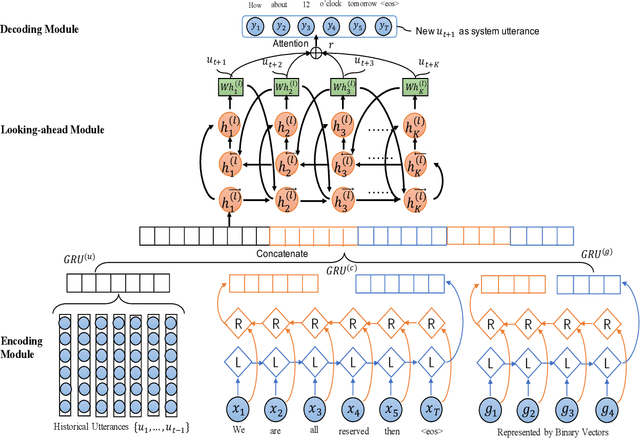
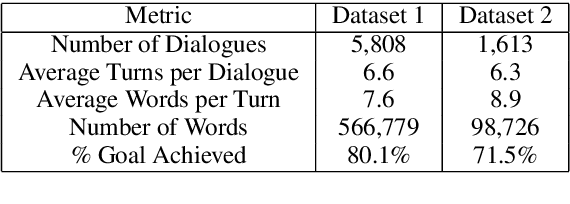
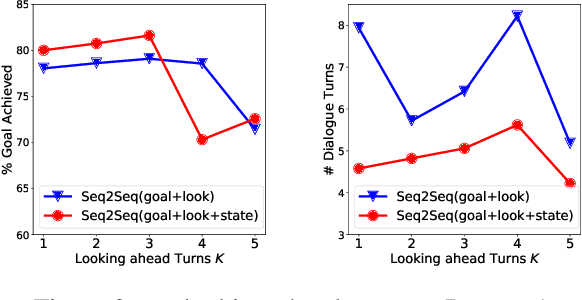
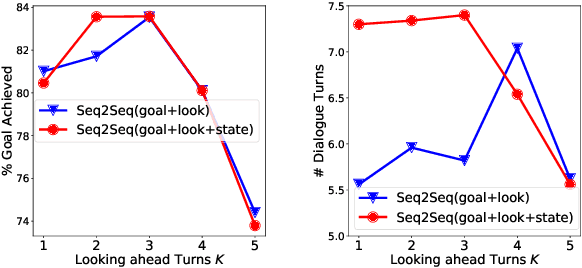
Learning an efficient manager of dialogue agent from data with little manual intervention is important, especially for goal-oriented dialogues. However, existing methods either take too many manual efforts (e.g. reinforcement learning methods) or cannot guarantee the dialogue efficiency (e.g. sequence-to-sequence methods). In this paper, we address this problem by proposing a novel end-to-end learning model to train a dialogue agent that can look ahead for several future turns and generate an optimal response to make the dialogue efficient. Our method is data-driven and does not require too much manual work for intervention during system design. We evaluate our method on two datasets of different scenarios and the experimental results demonstrate the efficiency of our model.