 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOS-MSL: One Stage Multimodal Sequential Link Framework for Scene Segmentation and Classification
Paper and Code
Jul 04, 2022
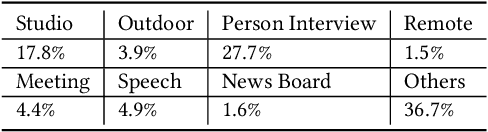
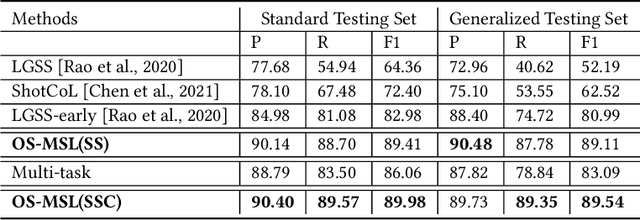
Scene segmentation and classification (SSC) serve as a critical step towards the field of video structuring analysis. Intuitively, jointly learning of these two tasks can promote each other by sharing common information. However, scene segmentation concerns more on the local difference between adjacent shots while classification needs the global representation of scene segments, which probably leads to the model dominated by one of the two tasks in the training phase. In this paper, from an alternate perspective to overcome the above challenges, we unite these two tasks into one task by a new form of predicting shots link: a link connects two adjacent shots, indicating that they belong to the same scene or category. To the end, we propose a general One Stage Multimodal Sequential Link Framework (OS-MSL) to both distinguish and leverage the two-fold semantics by reforming the two learning tasks into a unified one. Furthermore, we tailor a specific module called DiffCorrNet to explicitly extract the information of differences and correlations among shots. Extensive experiments on a brand-new large scale dataset collected from real-world applications, and MovieScenes are conducted. Both the results demonstrate the effectiveness of our proposed method against strong baselines.