 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
Sequential-NIAH: A Needle-In-A-Haystack Benchmark for Extracting Sequential Needles from Long Contexts
Apr 09, 2025Evaluating the ability of large language models (LLMs) to handle extended contexts is critical, particularly for retrieving information relevant to specific queries embedded within lengthy inputs. We introduce Sequential-NIAH, a benchmark specifically designed to evaluate the capability of LLMs to extract sequential information items (known as needles) from long contexts. The benchmark comprises three types of needle generation pipelines: synthetic, real, and open-domain QA. It includes contexts ranging from 8K to 128K tokens in length, with a dataset of 14,000 samples (2,000 reserved for testing). To facilitate evaluation on this benchmark, we trained a synthetic data-driven evaluation model capable of evaluating answer correctness based on chronological or logical order, achieving an accuracy of 99.49% on synthetic test data. We conducted experiments on six well-known LLMs, revealing that even the best-performing model achieved a maximum accuracy of only 63.15%. Further analysis highlights the growing challenges posed by increasing context lengths and the number of needles, underscoring substantial room for improvement. Additionally, noise robustness experiments validate the reliability of the benchmark, making Sequential-NIAH an important reference for advancing research on long text extraction capabilities of LLMs.
FactGuard: Leveraging Multi-Agent Systems to Generate Answerable and Unanswerable Questions for Enhanced Long-Context LLM Extraction
Apr 08, 2025Extractive reading comprehension systems are designed to locate the correct answer to a question within a given text. However, a persistent challenge lies in ensuring these models maintain high accuracy in answering questions while reliably recognizing unanswerable queries. Despite significant advances in large language models (LLMs) for reading comprehension, this issue remains critical, particularly as the length of supported contexts continues to expand. To address this challenge, we propose an innovative data augmentation methodology grounded in a multi-agent collaborative framework. Unlike traditional methods, such as the costly human annotation process required for datasets like SQuAD 2.0, our method autonomously generates evidence-based question-answer pairs and systematically constructs unanswerable questions. Using this methodology, we developed the FactGuard-Bench dataset, which comprises 25,220 examples of both answerable and unanswerable question scenarios, with context lengths ranging from 8K to 128K. Experimental evaluations conducted on seven popular LLMs reveal that even the most advanced models achieve only 61.79% overall accuracy. Furthermore, we emphasize the importance of a model's ability to reason about unanswerable questions to avoid generating plausible but incorrect answers. By implementing efficient data selection and generation within the multi-agent collaborative framework, our method significantly reduces the traditionally high costs associated with manual annotation and provides valuable insights for the training and optimization of LLMs.
Let's Be Self-generated via Step by Step: A Curriculum Learning Approach to Automated Reasoning with Large Language Models
Oct 29, 2024



While Chain of Thought (CoT) prompting approaches have significantly consolidated the reasoning capabilities of large language models (LLMs), they still face limitations that require extensive human effort or have performance needs to be improved. Existing endeavors have focused on bridging these gaps; however, these approaches either hinge on external data and cannot completely eliminate manual effort, or they fall short in effectively directing LLMs to generate high-quality exemplary prompts. To address the said pitfalls, we propose a novel prompt approach for automatic reasoning named \textbf{LBS3}, inspired by curriculum learning which better reflects human learning habits. Specifically, LBS3 initially steers LLMs to recall easy-to-hard proxy queries that are pertinent to the target query. Following this, it invokes a progressive strategy that utilizes exemplary prompts stemmed from easy-proxy queries to direct LLMs in solving hard-proxy queries, enabling the high-quality of the proxy solutions. Finally, our extensive experiments in various reasoning-intensive tasks with varying open- and closed-source LLMs show that LBS3 achieves strongly competitive performance compared to the SOTA baselines.
CJEval: A Benchmark for Assessing Large Language Models Using Chinese Junior High School Exam Data
Sep 25, 2024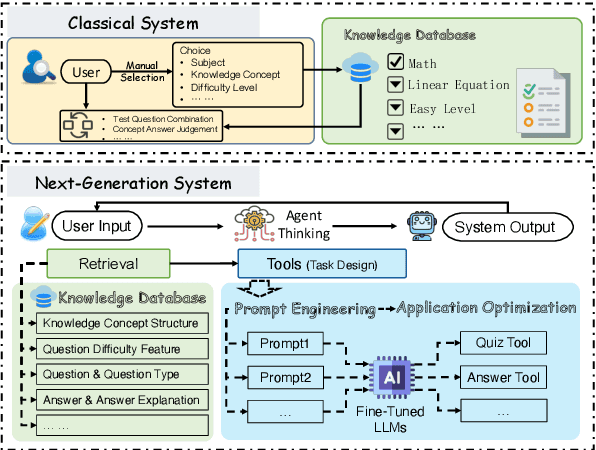
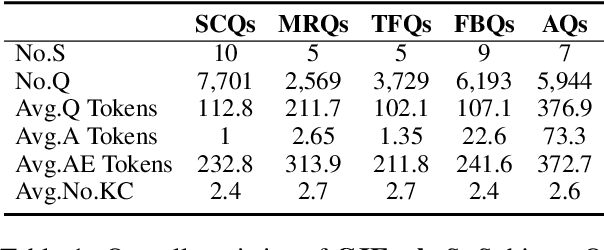

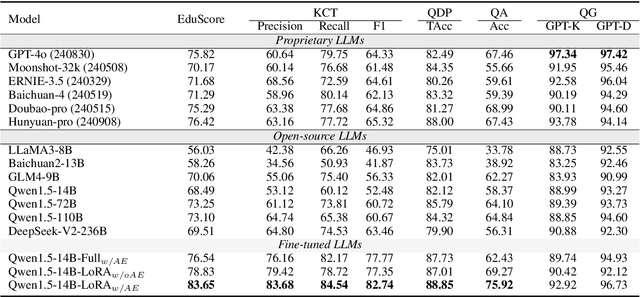
Online education platforms have significantly transformed the dissemination of educational resources by providing a dynamic and digital infrastructure. With the further enhancement of this transformation, the advent of Large Language Models (LLMs) has elevated the intelligence levels of these platforms. However, current academic benchmarks provide limited guidance for real-world industry scenarios. This limitation arises because educational applications require more than mere test question responses. To bridge this gap, we introduce CJEval, a benchmark based on Chinese Junior High School Exam Evaluations. CJEval consists of 26,136 samples across four application-level educational tasks covering ten subjects. These samples include not only questions and answers but also detailed annotations such as question types, difficulty levels, knowledge concepts, and answer explanations. By utilizing this benchmark, we assessed LLMs' potential applications and conducted a comprehensive analysis of their performance by fine-tuning on various educational tasks. Extensive experiments and discussions have highlighted the opportunities and challenges of applying LLMs in the field of education.
SNFinLLM: Systematic and Nuanced Financial Domain Adaptation of Chinese Large Language Models
Aug 05, 2024Large language models (LLMs) have become powerful tools for advancing natural language processing applications in the financial industry. However, existing financial LLMs often face challenges such as hallucinations or superficial parameter training, resulting in suboptimal performance, particularly in financial computing and machine reading comprehension (MRC). To address these issues, we propose a novel large language model specifically designed for the Chinese financial domain, named SNFinLLM. SNFinLLM excels in domain-specific tasks such as answering questions, summarizing financial research reports, analyzing sentiment, and executing financial calculations. We then perform the supervised fine-tuning (SFT) to enhance the model's proficiency across various financial domains. Specifically, we gather extensive financial data and create a high-quality instruction dataset composed of news articles, professional papers, and research reports of finance domain. Utilizing both domain-specific and general datasets, we proceed with continuous pre-training on an established open-source base model, resulting in SNFinLLM-base. Following this, we engage in supervised fine-tuning (SFT) to bolster the model's capability across multiple financial tasks. Crucially, we employ a straightforward Direct Preference Optimization (DPO) method to better align the model with human preferences. Extensive experiments conducted on finance benchmarks and our evaluation dataset demonstrate that SNFinLLM markedly outperforms other state-of-the-art financial language models. For more details, check out our demo video here: https://www.youtube.com/watch?v=GYT-65HZwus.
Grafting Pre-trained Models for Multimodal Headline Generation
Nov 14, 2022
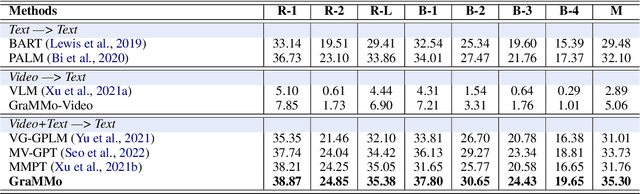

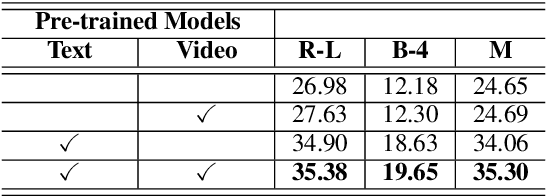
Multimodal headline utilizes both video frames and transcripts to generate the natural language title of the videos. Due to a lack of large-scale, manually annotated data, the task of annotating grounded headlines for video is labor intensive and impractical. Previous researches on pre-trained language models and video-language models have achieved significant progress in related downstream tasks. However, none of them can be directly applied to multimodal headline architecture where we need both multimodal encoder and sentence decoder. A major challenge in simply gluing language model and video-language model is the modality balance, which is aimed at combining visual-language complementary abilities. In this paper, we propose a novel approach to graft the video encoder from the pre-trained video-language model on the generative pre-trained language model. We also present a consensus fusion mechanism for the integration of different components, via inter/intra modality relation. Empirically, experiments show that the grafted model achieves strong results on a brand-new dataset collected from real-world applications.
Leveraging Key Information Modeling to Improve Less-Data Constrained News Headline Generation via Duality Fine-Tuning
Oct 10, 2022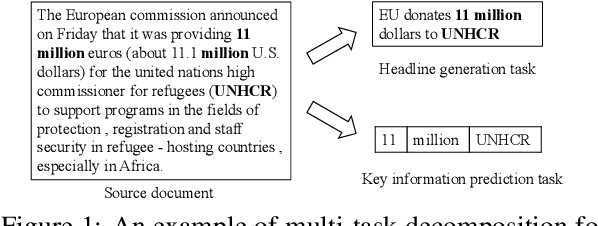
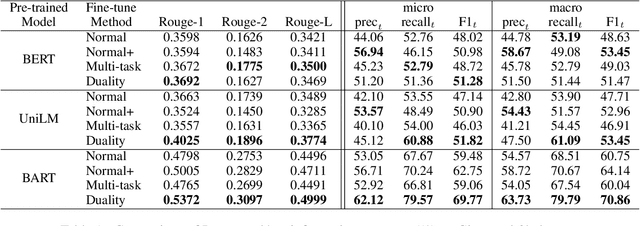
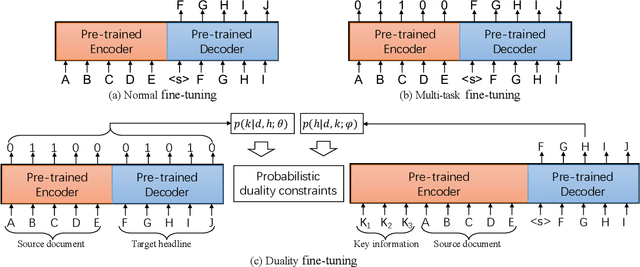
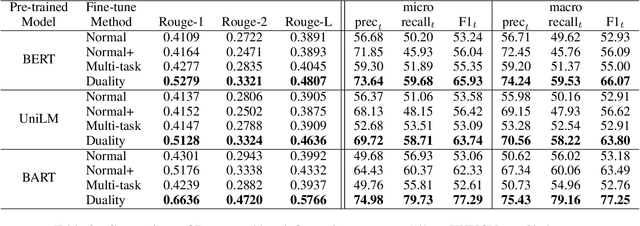
Recent language generative models are mostly trained on large-scale datasets, while in some real scenarios, the training datasets are often expensive to obtain and would be small-scale. In this paper we investigate the challenging task of less-data constrained generation, especially when the generated news headlines are short yet expected by readers to keep readable and informative simultaneously. We highlight the key information modeling task and propose a novel duality fine-tuning method by formally defining the probabilistic duality constraints between key information prediction and headline generation tasks. The proposed method can capture more information from limited data, build connections between separate tasks, and is suitable for less-data constrained generation tasks. Furthermore, the method can leverage various pre-trained generative regimes, e.g., autoregressive and encoder-decoder models. We conduct extensive experiments to demonstrate that our method is effective and efficient to achieve improved performance in terms of language modeling metric and informativeness correctness metric on two public datasets.
OS-MSL: One Stage Multimodal Sequential Link Framework for Scene Segmentation and Classification
Jul 04, 2022
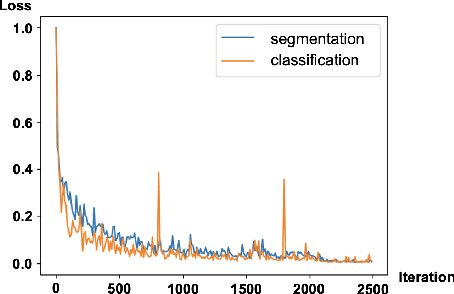
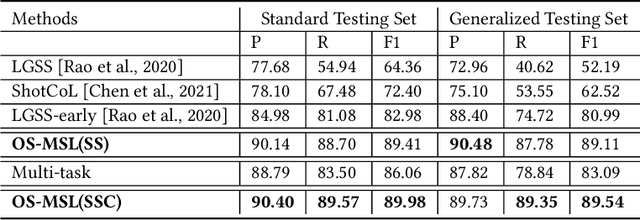
Scene segmentation and classification (SSC) serve as a critical step towards the field of video structuring analysis. Intuitively, jointly learning of these two tasks can promote each other by sharing common information. However, scene segmentation concerns more on the local difference between adjacent shots while classification needs the global representation of scene segments, which probably leads to the model dominated by one of the two tasks in the training phase. In this paper, from an alternate perspective to overcome the above challenges, we unite these two tasks into one task by a new form of predicting shots link: a link connects two adjacent shots, indicating that they belong to the same scene or category. To the end, we propose a general One Stage Multimodal Sequential Link Framework (OS-MSL) to both distinguish and leverage the two-fold semantics by reforming the two learning tasks into a unified one. Furthermore, we tailor a specific module called DiffCorrNet to explicitly extract the information of differences and correlations among shots. Extensive experiments on a brand-new large scale dataset collected from real-world applications, and MovieScenes are conducted. Both the results demonstrate the effectiveness of our proposed method against strong baselines.