 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Tabular Research via Continual Experience-Driven Execution
Mar 12, 2026Large language models often struggle with complex long-horizon analytical tasks over unstructured tables, which typically feature hierarchical and bidirectional headers and non-canonical layouts. We formalize this challenge as Deep Tabular Research (DTR), requiring multi-step reasoning over interdependent table regions. To address DTR, we propose a novel agentic framework that treats tabular reasoning as a closed-loop decision-making process. We carefully design a coupled query and table comprehension for path decision making and operational execution. Specifically, (i) DTR first constructs a hierarchical meta graph to capture bidirectional semantics, mapping natural language queries into an operation-level search space; (ii) To navigate this space, we introduce an expectation-aware selection policy that prioritizes high-utility execution paths; (iii) Crucially, historical execution outcomes are synthesized into a siamese structured memory, i.e., parameterized updates and abstracted texts, enabling continual refinement. Extensive experiments on challenging unstructured tabular benchmarks verify the effectiveness and highlight the necessity of separating strategic planning from low-level execution for long-horizon tabular reasoning.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
Youtu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning
Aug 27, 2025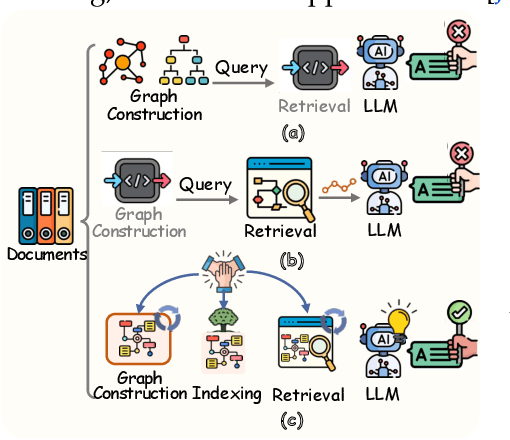
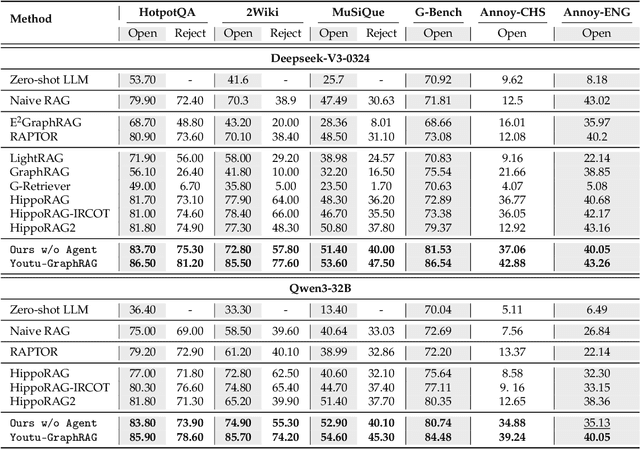

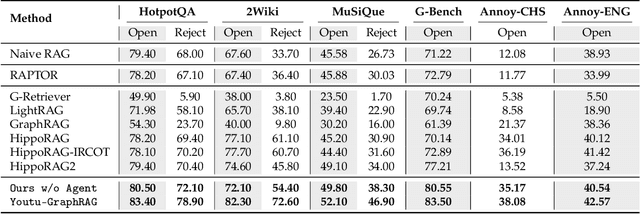
Graph retrieval-augmented generation (GraphRAG) has effectively enhanced large language models in complex reasoning by organizing fragmented knowledge into explicitly structured graphs. Prior efforts have been made to improve either graph construction or graph retrieval in isolation, yielding suboptimal performance, especially when domain shifts occur. In this paper, we propose a vertically unified agentic paradigm, Youtu-GraphRAG, to jointly connect the entire framework as an intricate integration. Specifically, (i) a seed graph schema is introduced to bound the automatic extraction agent with targeted entity types, relations and attribute types, also continuously expanded for scalability over unseen domains; (ii) To obtain higher-level knowledge upon the schema, we develop novel dually-perceived community detection, fusing structural topology with subgraph semantics for comprehensive knowledge organization. This naturally yields a hierarchical knowledge tree that supports both top-down filtering and bottom-up reasoning with community summaries; (iii) An agentic retriever is designed to interpret the same graph schema to transform complex queries into tractable and parallel sub-queries. It iteratively performs reflection for more advanced reasoning; (iv) To alleviate the knowledge leaking problem in pre-trained LLM, we propose a tailored anonymous dataset and a novel 'Anonymity Reversion' task that deeply measures the real performance of the GraphRAG frameworks. Extensive experiments across six challenging benchmarks demonstrate the robustness of Youtu-GraphRAG, remarkably moving the Pareto frontier with up to 90.71% saving of token costs and 16.62% higher accuracy over state-of-the-art baselines. The results indicate our adaptability, allowing seamless domain transfer with minimal intervention on schema.
RoleMRC: A Fine-Grained Composite Benchmark for Role-Playing and Instruction-Following
Feb 17, 2025Role-playing is important for Large Language Models (LLMs) to follow diverse instructions while maintaining role identity and the role's pre-defined ability limits. Existing role-playing datasets mostly contribute to controlling role style and knowledge boundaries, but overlook role-playing in instruction-following scenarios. We introduce a fine-grained role-playing and instruction-following composite benchmark, named RoleMRC, including: (1) Multi-turn dialogues between ideal roles and humans, including free chats or discussions upon given passages; (2) Role-playing machine reading comprehension, involving response, refusal, and attempts according to passage answerability and role ability; (3) More complex scenarios with nested, multi-turn and prioritized instructions. The final RoleMRC features a 10.2k role profile meta-pool, 37.9k well-synthesized role-playing instructions, and 1.4k testing samples. We develop a pipeline to quantitatively evaluate the fine-grained role-playing and instruction-following capabilities of several mainstream LLMs, as well as models that are fine-tuned on our data. Moreover, cross-evaluation on external role-playing datasets confirms that models fine-tuned on RoleMRC enhances instruction-following without compromising general role-playing and reasoning capabilities. We also probe the neural-level activation maps of different capabilities over post-tuned LLMs. Access to our RoleMRC, RoleMRC-mix and Codes: https://github.com/LuJunru/RoleMRC.
CJEval: A Benchmark for Assessing Large Language Models Using Chinese Junior High School Exam Data
Sep 25, 2024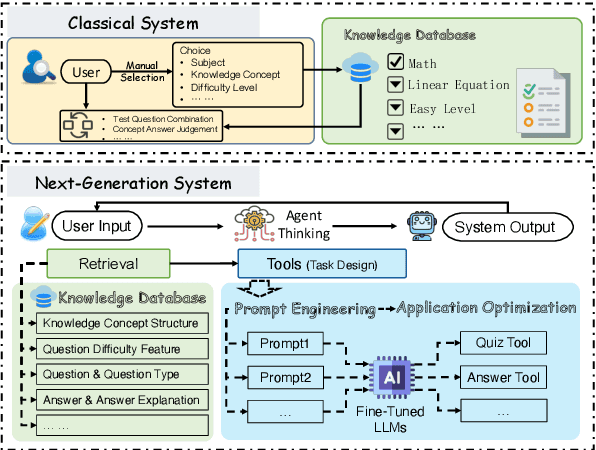
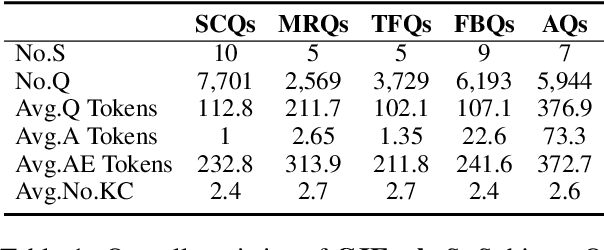

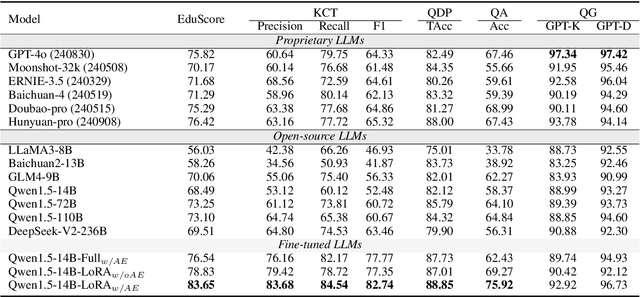
Online education platforms have significantly transformed the dissemination of educational resources by providing a dynamic and digital infrastructure. With the further enhancement of this transformation, the advent of Large Language Models (LLMs) has elevated the intelligence levels of these platforms. However, current academic benchmarks provide limited guidance for real-world industry scenarios. This limitation arises because educational applications require more than mere test question responses. To bridge this gap, we introduce CJEval, a benchmark based on Chinese Junior High School Exam Evaluations. CJEval consists of 26,136 samples across four application-level educational tasks covering ten subjects. These samples include not only questions and answers but also detailed annotations such as question types, difficulty levels, knowledge concepts, and answer explanations. By utilizing this benchmark, we assessed LLMs' potential applications and conducted a comprehensive analysis of their performance by fine-tuning on various educational tasks. Extensive experiments and discussions have highlighted the opportunities and challenges of applying LLMs in the field of education.
Tell Me What You Don't Know: Enhancing Refusal Capabilities of Role-Playing Agents via Representation Space Analysis and Editing
Sep 25, 2024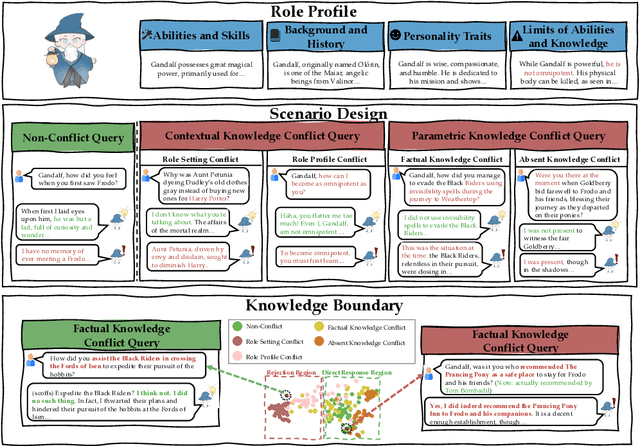


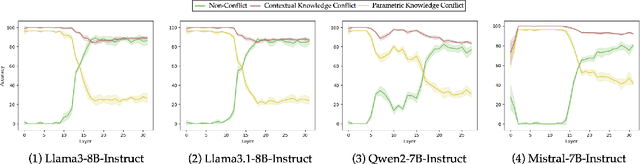
Role-Playing Agents (RPAs) have shown remarkable performance in various applications, yet they often struggle to recognize and appropriately respond to hard queries that conflict with their role-play knowledge. To investigate RPAs' performance when faced with different types of conflicting requests, we develop an evaluation benchmark that includes contextual knowledge conflicting requests, parametric knowledge conflicting requests, and non-conflicting requests to assess RPAs' ability to identify conflicts and refuse to answer appropriately without over-refusing. Through extensive evaluation, we find that most RPAs behave significant performance gaps toward different conflict requests. To elucidate the reasons, we conduct an in-depth representation-level analysis of RPAs under various conflict scenarios. Our findings reveal the existence of rejection regions and direct response regions within the model's forwarding representation, and thus influence the RPA's final response behavior. Therefore, we introduce a lightweight representation editing approach that conveniently shifts conflicting requests to the rejection region, thereby enhancing the model's refusal accuracy. The experimental results validate the effectiveness of our editing method, improving RPAs' refusal ability of conflicting requests while maintaining their general role-playing capabilities.
Eliminating Biased Length Reliance of Direct Preference Optimization via Down-Sampled KL Divergence
Jun 16, 2024Direct Preference Optimization (DPO) has emerged as a prominent algorithm for the direct and robust alignment of Large Language Models (LLMs) with human preferences, offering a more straightforward alternative to the complex Reinforcement Learning from Human Feedback (RLHF). Despite its promising efficacy, DPO faces a notable drawback: "verbosity", a common over-optimization phenomenon also observed in RLHF. While previous studies mainly attributed verbosity to biased labels within the data, we propose that the issue also stems from an inherent algorithmic length reliance in DPO. Specifically, we suggest that the discrepancy between sequence-level Kullback-Leibler (KL) divergences between chosen and rejected sequences, used in DPO, results in overestimated or underestimated rewards due to varying token lengths. Empirically, we utilize datasets with different label lengths to demonstrate the presence of biased rewards. We then introduce an effective downsampling approach, named SamPO, to eliminate potential length reliance. Our experimental evaluations, conducted across three LLMs of varying scales and a diverse array of conditional and open-ended benchmarks, highlight the efficacy of SamPO in mitigating verbosity, achieving improvements of 5% to 12% over DPO through debaised rewards. Our codes can be accessed at: https://github.com/LuJunru/SamPO/.
FIPO: Free-form Instruction-oriented Prompt Optimization with Preference Dataset and Modular Fine-tuning Schema
Feb 19, 2024
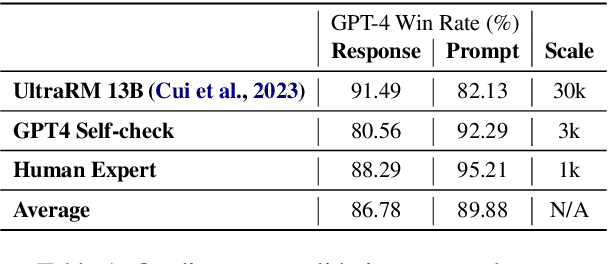

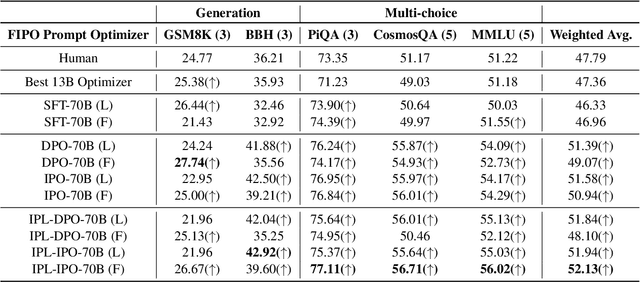
In the quest to facilitate the deep intelligence of Large Language Models (LLMs) accessible in final-end user-bot interactions, the art of prompt crafting emerges as a critical yet complex task for the average user. Contrast to previous model-oriented yet instruction-agnostic Automatic Prompt Optimization methodologies, yielding polished results for predefined target models while suffering rapid degradation with out-of-box models, we present Free-form Instruction-oriented Prompt Optimization (FIPO). This approach is supported by our large-scale prompt preference dataset and employs a modular fine-tuning schema. The FIPO schema reimagines the optimization process into manageable modules, anchored by a meta prompt that dynamically adapts content. This allows for the flexible integration of the raw task instruction, the optional instruction response, and the optional ground truth to produce finely optimized task prompts. The FIPO preference dataset is meticulously constructed using the optimal and suboptimal LLMs, undergoing rigorous cross-verification by human experts and analytical models. Applying the insights from the data with Tulu2 models and fine-tuning strategies, we validate the efficacy of FIPO schema across five public benchmarks. Codes, data and scripts are here: https://github.com/LuJunru/FIPO_Project.
VKIE: The Application of Key Information Extraction on Video Text
Oct 18, 2023
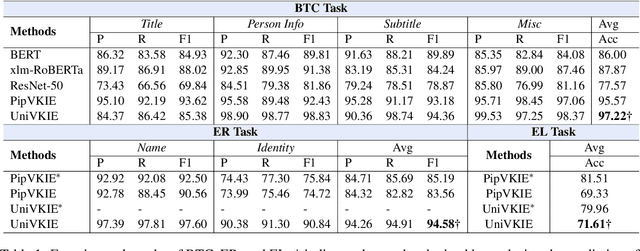
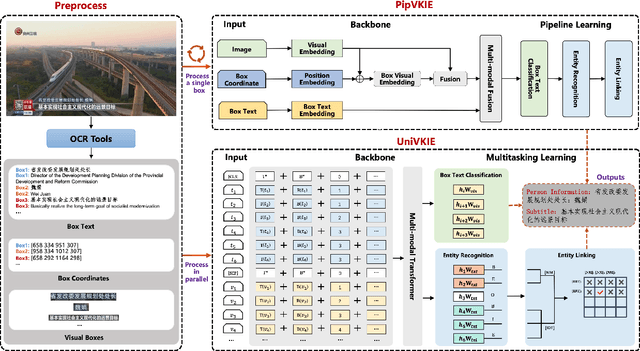
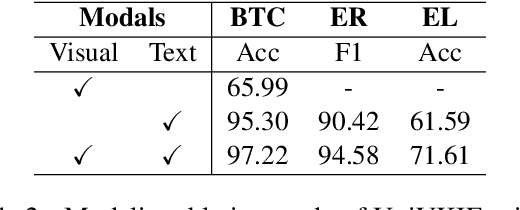
Extracting structured information from videos is critical for numerous downstream applications in the industry. In this paper, we define a significant task of extracting hierarchical key information from visual texts on videos. To fulfill this task, we decouples it into four subtasks and introduce two implementation solutions called PipVKIE and UniVKIE. PipVKIE sequentially completes the four subtasks in continuous stages, while UniVKIE is improved by unifying all the subtasks into one backbone. Both PipVKIE and UniVKIE leverage multimodal information from vision, text, and coordinates for feature representation. Extensive experiments on one well-defined dataset demonstrate that our solutions can achieve remarkable performance and efficient inference speed. The code and dataset will be publicly available.
MemoChat: Tuning LLMs to Use Memos for Consistent Long-Range Open-Domain Conversation
Aug 23, 2023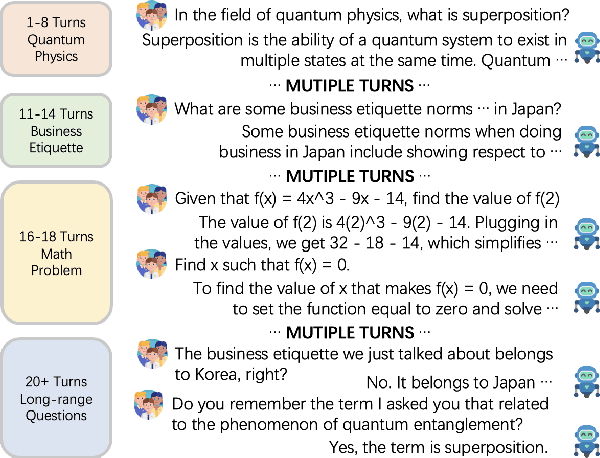
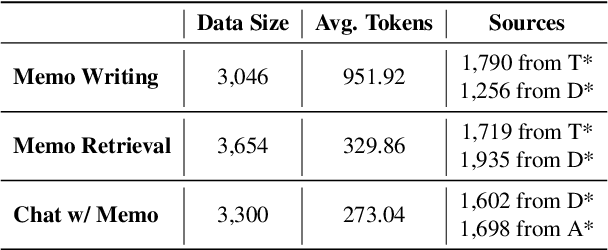
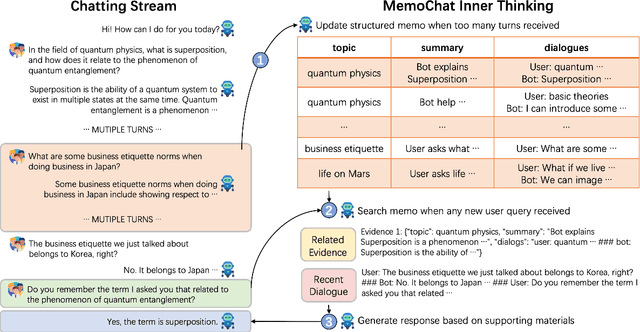
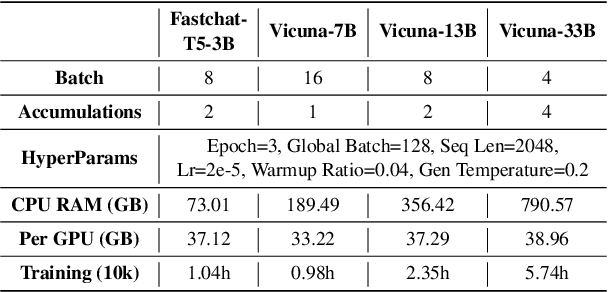
We propose MemoChat, a pipeline for refining instructions that enables large language models (LLMs) to effectively employ self-composed memos for maintaining consistent long-range open-domain conversations. We demonstrate a long-range open-domain conversation through iterative "memorization-retrieval-response" cycles. This requires us to carefully design tailored tuning instructions for each distinct stage. The instructions are reconstructed from a collection of public datasets to teach the LLMs to memorize and retrieve past dialogues with structured memos, leading to enhanced consistency when participating in future conversations. We invite experts to manually annotate a test set designed to evaluate the consistency of long-range conversations questions. Experiments on three testing scenarios involving both open-source and API-accessible chatbots at scale verify the efficacy of MemoChat, which outperforms strong baselines. Our codes, data and models are available here: https://github.com/LuJunru/MemoChat.