 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIPO: Free-form Instruction-oriented Prompt Optimization with Preference Dataset and Modular Fine-tuning Schema
Paper and Code

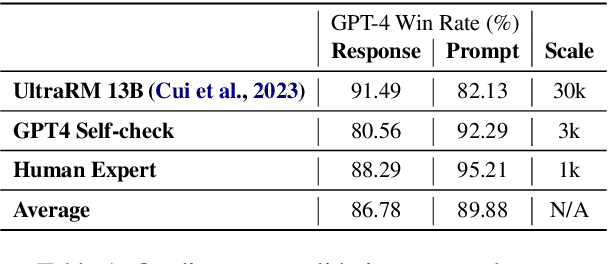

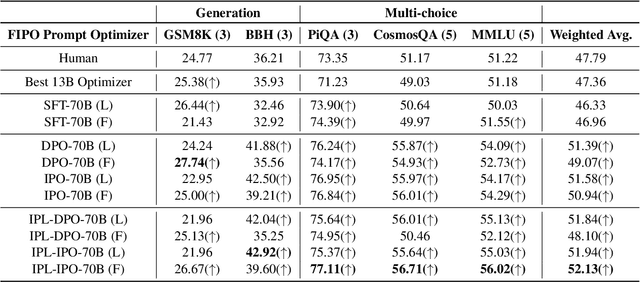
In the quest to facilitate the deep intelligence of Large Language Models (LLMs) accessible in final-end user-bot interactions, the art of prompt crafting emerges as a critical yet complex task for the average user. Contrast to previous model-oriented yet instruction-agnostic Automatic Prompt Optimization methodologies, yielding polished results for predefined target models while suffering rapid degradation with out-of-box models, we present Free-form Instruction-oriented Prompt Optimization (FIPO). This approach is supported by our large-scale prompt preference dataset and employs a modular fine-tuning schema. The FIPO schema reimagines the optimization process into manageable modules, anchored by a meta prompt that dynamically adapts content. This allows for the flexible integration of the raw task instruction, the optional instruction response, and the optional ground truth to produce finely optimized task prompts. The FIPO preference dataset is meticulously constructed using the optimal and suboptimal LLMs, undergoing rigorous cross-verification by human experts and analytical models. Applying the insights from the data with Tulu2 models and fine-tuning strategies, we validate the efficacy of FIPO schema across five public benchmarks. Codes, data and scripts are here: https://github.com/LuJunru/FIPO_Project.