 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Extractive Summarization with Heterogeneous Graph Embeddings for Chinese Document
Paper and Code
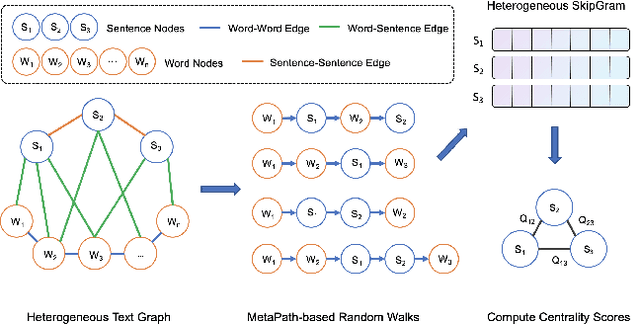
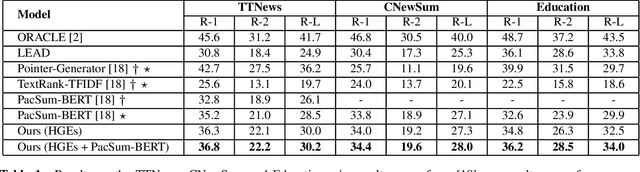
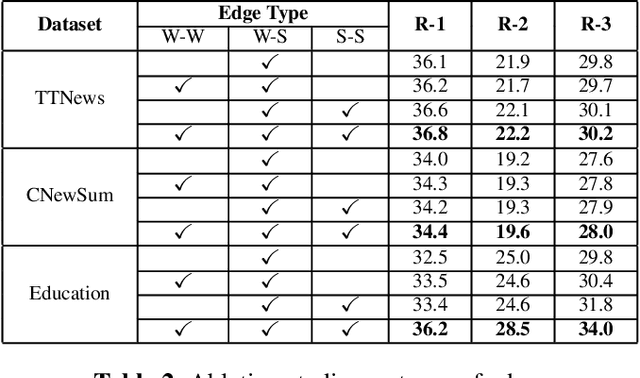
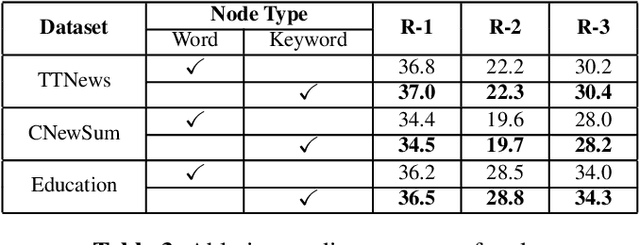
In the scenario of unsupervised extractive summarization, learning high-quality sentence representations is essential to select salient sentences from the input document. Previous studies focus more on employing statistical approaches or pre-trained language models (PLMs) to extract sentence embeddings, while ignoring the rich information inherent in the heterogeneous types of interaction between words and sentences. In this paper, we are the first to propose an unsupervised extractive summarizaiton method with heterogeneous graph embeddings (HGEs) for Chinese document. A heterogeneous text graph is constructed to capture different granularities of interactions by incorporating graph structural information. Moreover, our proposed graph is general and flexible where additional nodes such as keywords can be easily integrated. Experimental results demonstrate that our method consistently outperforms the strong baseline in three summarization datasets.