 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReversible Diffusion Decoding for Diffusion Language Models
Jan 29, 2026Diffusion language models enable parallel token generation through block-wise decoding, but their irreversible commitments can lead to stagnation, where the reverse diffusion process fails to make further progress under a suboptimal context.We propose Reversible Diffusion Decoding (RDD), a decoding framework that introduces reversibility into block-wise diffusion generation. RDD detects stagnation as a state-dependent failure of the reverse process and enables efficient backtracking to earlier blocks without recomputation via cached model states. To avoid repeated failure trajectories, RDD applies confidence-guided re-masking to selectively reinitialize uncertain tokens while preserving reliable context.This reversible formulation allows decoding to recover from early commitment errors while maintaining the parallel efficiency of diffusion-based generation. Experiments show that RDD improves generation robustness and quality over baselines with minimal computational overhead.
DS$^2$Net: Detail-Semantic Deep Supervision Network for Medical Image Segmentation
Aug 06, 2025Deep Supervision Networks exhibit significant efficacy for the medical imaging community. Nevertheless, existing work merely supervises either the coarse-grained semantic features or fine-grained detailed features in isolation, which compromises the fact that these two types of features hold vital relationships in medical image analysis. We advocate the powers of complementary feature supervision for medical image segmentation, by proposing a Detail-Semantic Deep Supervision Network (DS$^2$Net). DS$^2$Net navigates both low-level detailed and high-level semantic feature supervision through Detail Enhance Module (DEM) and Semantic Enhance Module (SEM). DEM and SEM respectively harness low-level and high-level feature maps to create detail and semantic masks for enhancing feature supervision. This is a novel shift from single-view deep supervision to multi-view deep supervision. DS$^2$Net is also equipped with a novel uncertainty-based supervision loss that adaptively assigns the supervision strength of features within distinct scales based on their uncertainty, thus circumventing the sub-optimal heuristic design that typifies previous works. Through extensive experiments on six benchmarks captured under either colonoscopy, ultrasound and microscope, we demonstrate that DS$^2$Net consistently outperforms state-of-the-art methods for medical image analysis.
Squeeze10-LLM: Squeezing LLMs' Weights by 10 Times via a Staged Mixed-Precision Quantization Method
Jul 24, 2025Deploying large language models (LLMs) is challenging due to their massive parameters and high computational costs. Ultra low-bit quantization can significantly reduce storage and accelerate inference, but extreme compression (i.e., mean bit-width <= 2) often leads to severe performance degradation. To address this, we propose Squeeze10-LLM, effectively "squeezing" 16-bit LLMs' weights by 10 times. Specifically, Squeeze10-LLM is a staged mixed-precision post-training quantization (PTQ) framework and achieves an average of 1.6 bits per weight by quantizing 80% of the weights to 1 bit and 20% to 4 bits. We introduce Squeeze10LLM with two key innovations: Post-Binarization Activation Robustness (PBAR) and Full Information Activation Supervision (FIAS). PBAR is a refined weight significance metric that accounts for the impact of quantization on activations, improving accuracy in low-bit settings. FIAS is a strategy that preserves full activation information during quantization to mitigate cumulative error propagation across layers. Experiments on LLaMA and LLaMA2 show that Squeeze10-LLM achieves state-of-the-art performance for sub-2bit weight-only quantization, improving average accuracy from 43% to 56% on six zero-shot classification tasks--a significant boost over existing PTQ methods. Our code will be released upon publication.
SynergyAmodal: Deocclude Anything with Text Control
Apr 28, 2025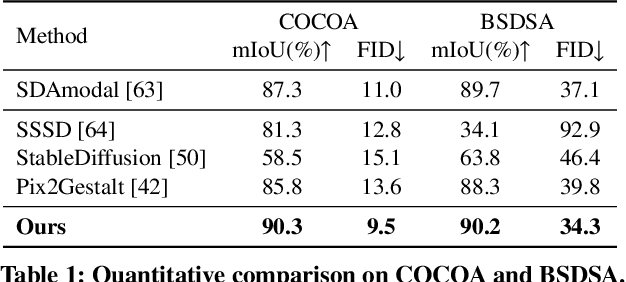

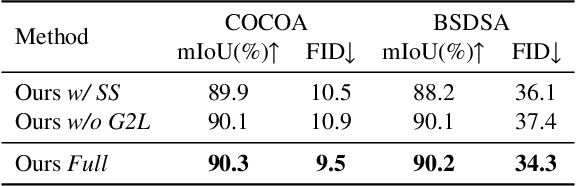
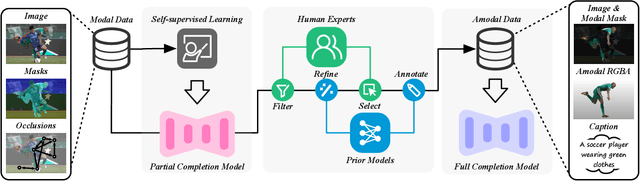
Image deocclusion (or amodal completion) aims to recover the invisible regions (\ie, shape and appearance) of occluded instances in images. Despite recent advances, the scarcity of high-quality data that balances diversity, plausibility, and fidelity remains a major obstacle. To address this challenge, we identify three critical elements: leveraging in-the-wild image data for diversity, incorporating human expertise for plausibility, and utilizing generative priors for fidelity. We propose SynergyAmodal, a novel framework for co-synthesizing in-the-wild amodal datasets with comprehensive shape and appearance annotations, which integrates these elements through a tripartite data-human-model collaboration. First, we design an occlusion-grounded self-supervised learning algorithm to harness the diversity of in-the-wild image data, fine-tuning an inpainting diffusion model into a partial completion diffusion model. Second, we establish a co-synthesis pipeline to iteratively filter, refine, select, and annotate the initial deocclusion results of the partial completion diffusion model, ensuring plausibility and fidelity through human expert guidance and prior model constraints. This pipeline generates a high-quality paired amodal dataset with extensive category and scale diversity, comprising approximately 16K pairs. Finally, we train a full completion diffusion model on the synthesized dataset, incorporating text prompts as conditioning signals. Extensive experiments demonstrate the effectiveness of our framework in achieving zero-shot generalization and textual controllability. Our code, dataset, and models will be made publicly available at https://github.com/imlixinyang/SynergyAmodal.
Head-Aware KV Cache Compression for Efficient Visual Autoregressive Modeling
Apr 12, 2025Visual Autoregressive (VAR) models have emerged as a powerful approach for multi-modal content creation, offering high efficiency and quality across diverse multimedia applications. However, they face significant memory bottlenecks due to extensive KV cache accumulation during inference. Existing KV cache compression techniques for large language models are suboptimal for VAR models due to, as we identify in this paper, two distinct categories of attention heads in VAR models: Structural Heads, which preserve spatial coherence through diagonal attention patterns, and Contextual Heads, which maintain semantic consistency through vertical attention patterns. These differences render single-strategy KV compression techniques ineffective for VAR models. To address this, we propose HACK, a training-free Head-Aware Compression method for KV cache. HACK allocates asymmetric cache budgets and employs pattern-specific compression strategies tailored to the essential characteristics of each head category. Experiments on Infinity-2B, Infinity-8B, and VAR-d30 demonstrate its effectiveness in text-to-image and class-conditional generation tasks. HACK can hack down up to 50\% and 70\% of cache with minimal performance degradation for VAR-d30 and Infinity-8B, respectively. Even with 70\% and 90\% KV cache compression in VAR-d30 and Infinity-8B, HACK still maintains high-quality generation while reducing memory usage by 44.2\% and 58.9\%, respectively.
CPPO: Accelerating the Training of Group Relative Policy Optimization-Based Reasoning Models
Mar 28, 2025This paper introduces Completion Pruning Policy Optimization (CPPO) to accelerate the training of reasoning models based on Group Relative Policy Optimization (GRPO). GRPO, while effective, incurs high training costs due to the need for sampling multiple completions for each question. Our experiment and theoretical analysis reveals that the number of completions impacts model accuracy yet increases training time multiplicatively, and not all completions contribute equally to policy training -- their contribution depends on their relative advantage. To address these issues, we propose CPPO, which prunes completions with low absolute advantages, significantly reducing the number needed for gradient calculation and updates. Additionally, we introduce a dynamic completion allocation strategy to maximize GPU utilization by incorporating additional questions, further enhancing training efficiency. Experimental results demonstrate that CPPO achieves up to $8.32\times$ speedup on GSM8K and $3.51\times$ on Math while preserving or even enhancing the accuracy compared to the original GRPO. We release our code at https://github.com/lzhxmu/CPPO.
WideRange4D: Enabling High-Quality 4D Reconstruction with Wide-Range Movements and Scenes
Mar 17, 2025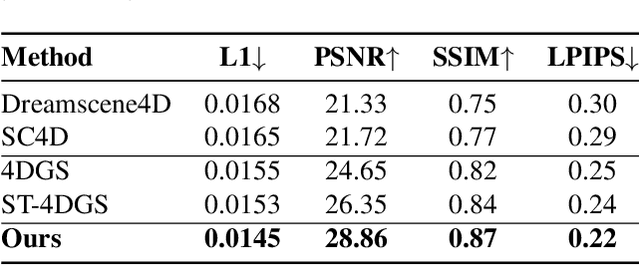



With the rapid development of 3D reconstruction technology, research in 4D reconstruction is also advancing, existing 4D reconstruction methods can generate high-quality 4D scenes. However, due to the challenges in acquiring multi-view video data, the current 4D reconstruction benchmarks mainly display actions performed in place, such as dancing, within limited scenarios. In practical scenarios, many scenes involve wide-range spatial movements, highlighting the limitations of existing 4D reconstruction datasets. Additionally, existing 4D reconstruction methods rely on deformation fields to estimate the dynamics of 3D objects, but deformation fields struggle with wide-range spatial movements, which limits the ability to achieve high-quality 4D scene reconstruction with wide-range spatial movements. In this paper, we focus on 4D scene reconstruction with significant object spatial movements and propose a novel 4D reconstruction benchmark, WideRange4D. This benchmark includes rich 4D scene data with large spatial variations, allowing for a more comprehensive evaluation of the generation capabilities of 4D generation methods. Furthermore, we introduce a new 4D reconstruction method, Progress4D, which generates stable and high-quality 4D results across various complex 4D scene reconstruction tasks. We conduct both quantitative and qualitative comparison experiments on WideRange4D, showing that our Progress4D outperforms existing state-of-the-art 4D reconstruction methods. Project: https://github.com/Gen-Verse/WideRange4D
CAKE: Cascading and Adaptive KV Cache Eviction with Layer Preferences
Mar 16, 2025



Large language models (LLMs) excel at processing long sequences, boosting demand for key-value (KV) caching. While recent efforts to evict KV cache have alleviated the inference burden, they often fail to allocate resources rationally across layers with different attention patterns. In this paper, we introduce Cascading and Adaptive KV cache Eviction (CAKE), a novel approach that frames KV cache eviction as a "cake-slicing problem." CAKE assesses layer-specific preferences by considering attention dynamics in both spatial and temporal dimensions, allocates rational cache size for layers accordingly, and manages memory constraints in a cascading manner. This approach enables a global view of cache allocation, adaptively distributing resources across diverse attention mechanisms while maintaining memory budgets. CAKE also employs a new eviction indicator that considers the shifting importance of tokens over time, addressing limitations in existing methods that overlook temporal dynamics. Comprehensive experiments on LongBench and NeedleBench show that CAKE maintains model performance with only 3.2% of the KV cache and consistently outperforms current baselines across various models and memory constraints, particularly in low-memory settings. Additionally, CAKE achieves over 10x speedup in decoding latency compared to full cache when processing contexts of 128K tokens with FlashAttention-2. Our code is available at https://github.com/antgroup/cakekv.
Audio-Reasoner: Improving Reasoning Capability in Large Audio Language Models
Mar 04, 2025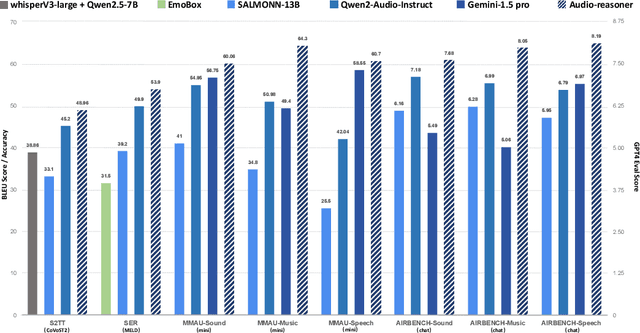
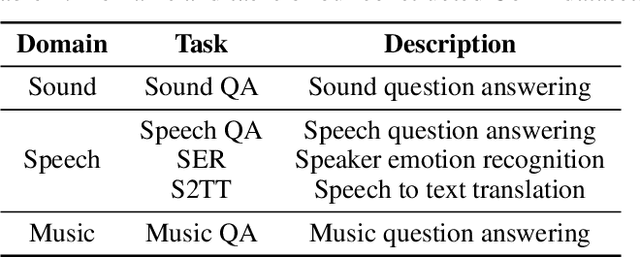
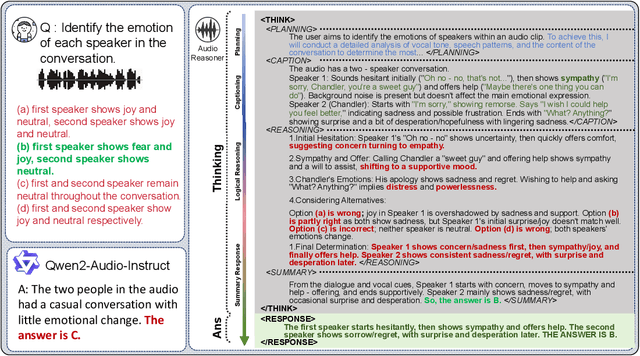

Recent advancements in multimodal reasoning have largely overlooked the audio modality. We introduce Audio-Reasoner, a large-scale audio language model for deep reasoning in audio tasks. We meticulously curated a large-scale and diverse multi-task audio dataset with simple annotations. Then, we leverage closed-source models to conduct secondary labeling, QA generation, along with structured COT process. These datasets together form a high-quality reasoning dataset with 1.2 million reasoning-rich samples, which we name CoTA. Following inference scaling principles, we train Audio-Reasoner on CoTA, enabling it to achieve great logical capabilities in audio reasoning. Experiments show state-of-the-art performance across key benchmarks, including MMAU-mini (+25.42%), AIR-Bench chat/foundation(+14.57%/+10.13%), and MELD (+8.01%). Our findings stress the core of structured CoT training in advancing audio reasoning.
Seeing World Dynamics in a Nutshell
Feb 05, 2025



We consider the problem of efficiently representing casually captured monocular videos in a spatially- and temporally-coherent manner. While existing approaches predominantly rely on 2D/2.5D techniques treating videos as collections of spatiotemporal pixels, they struggle with complex motions, occlusions, and geometric consistency due to absence of temporal coherence and explicit 3D structure. Drawing inspiration from monocular video as a projection of the dynamic 3D world, we explore representing videos in their intrinsic 3D form through continuous flows of Gaussian primitives in space-time. In this paper, we propose NutWorld, a novel framework that efficiently transforms monocular videos into dynamic 3D Gaussian representations in a single forward pass. At its core, NutWorld introduces a structured spatial-temporal aligned Gaussian (STAG) representation, enabling optimization-free scene modeling with effective depth and flow regularization. Through comprehensive experiments, we demonstrate that NutWorld achieves high-fidelity video reconstruction quality while enabling various downstream applications in real-time. Demos and code will be available at https://github.com/Nut-World/NutWorld.