 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWideRange4D: Enabling High-Quality 4D Reconstruction with Wide-Range Movements and Scenes
Mar 17, 2025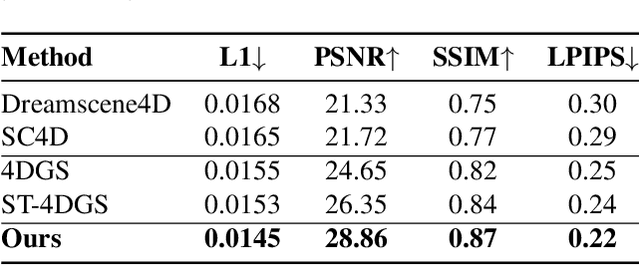



With the rapid development of 3D reconstruction technology, research in 4D reconstruction is also advancing, existing 4D reconstruction methods can generate high-quality 4D scenes. However, due to the challenges in acquiring multi-view video data, the current 4D reconstruction benchmarks mainly display actions performed in place, such as dancing, within limited scenarios. In practical scenarios, many scenes involve wide-range spatial movements, highlighting the limitations of existing 4D reconstruction datasets. Additionally, existing 4D reconstruction methods rely on deformation fields to estimate the dynamics of 3D objects, but deformation fields struggle with wide-range spatial movements, which limits the ability to achieve high-quality 4D scene reconstruction with wide-range spatial movements. In this paper, we focus on 4D scene reconstruction with significant object spatial movements and propose a novel 4D reconstruction benchmark, WideRange4D. This benchmark includes rich 4D scene data with large spatial variations, allowing for a more comprehensive evaluation of the generation capabilities of 4D generation methods. Furthermore, we introduce a new 4D reconstruction method, Progress4D, which generates stable and high-quality 4D results across various complex 4D scene reconstruction tasks. We conduct both quantitative and qualitative comparison experiments on WideRange4D, showing that our Progress4D outperforms existing state-of-the-art 4D reconstruction methods. Project: https://github.com/Gen-Verse/WideRange4D
DAMamba: Vision State Space Model with Dynamic Adaptive Scan
Feb 18, 2025State space models (SSMs) have recently garnered significant attention in computer vision. However, due to the unique characteristics of image data, adapting SSMs from natural language processing to computer vision has not outperformed the state-of-the-art convolutional neural networks (CNNs) and Vision Transformers (ViTs). Existing vision SSMs primarily leverage manually designed scans to flatten image patches into sequences locally or globally. This approach disrupts the original semantic spatial adjacency of the image and lacks flexibility, making it difficult to capture complex image structures. To address this limitation, we propose Dynamic Adaptive Scan (DAS), a data-driven method that adaptively allocates scanning orders and regions. This enables more flexible modeling capabilities while maintaining linear computational complexity and global modeling capacity. Based on DAS, we further propose the vision backbone DAMamba, which significantly outperforms current state-of-the-art vision Mamba models in vision tasks such as image classification, object detection, instance segmentation, and semantic segmentation. Notably, it surpasses some of the latest state-of-the-art CNNs and ViTs. Code will be available at https://github.com/ltzovo/DAMamba.