 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOracleAgent: A Multimodal Reasoning Agent for Oracle Bone Script Research
Oct 30, 2025As one of the earliest writing systems, Oracle Bone Script (OBS) preserves the cultural and intellectual heritage of ancient civilizations. However, current OBS research faces two major challenges: (1) the interpretation of OBS involves a complex workflow comprising multiple serial and parallel sub-tasks, and (2) the efficiency of OBS information organization and retrieval remains a critical bottleneck, as scholars often spend substantial effort searching for, compiling, and managing relevant resources. To address these challenges, we present OracleAgent, the first agent system designed for the structured management and retrieval of OBS-related information. OracleAgent seamlessly integrates multiple OBS analysis tools, empowered by large language models (LLMs), and can flexibly orchestrate these components. Additionally, we construct a comprehensive domain-specific multimodal knowledge base for OBS, which is built through a rigorous multi-year process of data collection, cleaning, and expert annotation. The knowledge base comprises over 1.4M single-character rubbing images and 80K interpretation texts. OracleAgent leverages this resource through its multimodal tools to assist experts in retrieval tasks of character, document, interpretation text, and rubbing image. Extensive experiments demonstrate that OracleAgent achieves superior performance across a range of multimodal reasoning and generation tasks, surpassing leading mainstream multimodal large language models (MLLMs) (e.g., GPT-4o). Furthermore, our case study illustrates that OracleAgent can effectively assist domain experts, significantly reducing the time cost of OBS research. These results highlight OracleAgent as a significant step toward the practical deployment of OBS-assisted research and automated interpretation systems.
DVHGNN: Multi-Scale Dilated Vision HGNN for Efficient Vision Recognition
Mar 19, 2025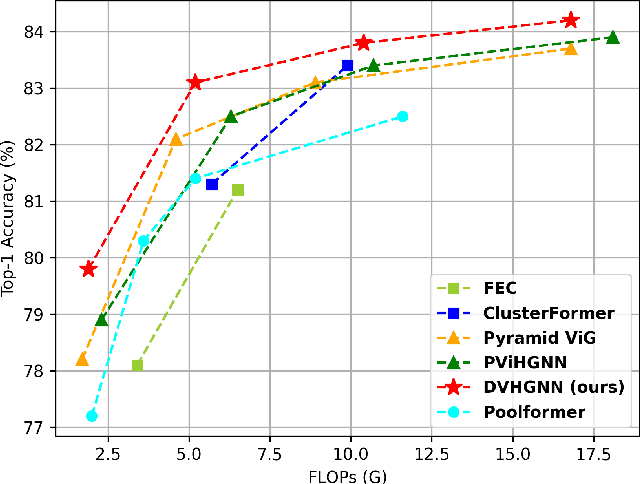

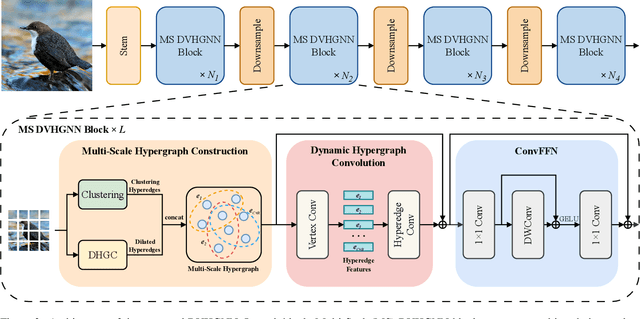
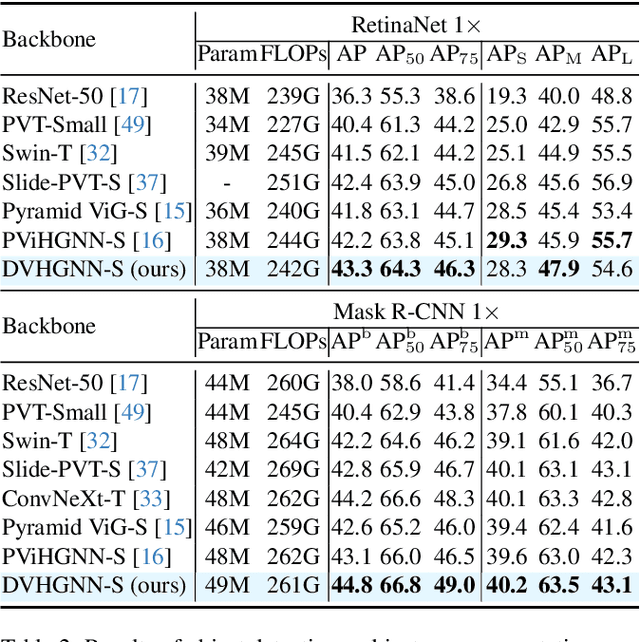
Recently, Vision Graph Neural Network (ViG) has gained considerable attention in computer vision. Despite its groundbreaking innovation, Vision Graph Neural Network encounters key issues including the quadratic computational complexity caused by its K-Nearest Neighbor (KNN) graph construction and the limitation of pairwise relations of normal graphs. To address the aforementioned challenges, we propose a novel vision architecture, termed Dilated Vision HyperGraph Neural Network (DVHGNN), which is designed to leverage multi-scale hypergraph to efficiently capture high-order correlations among objects. Specifically, the proposed method tailors Clustering and Dilated HyperGraph Construction (DHGC) to adaptively capture multi-scale dependencies among the data samples. Furthermore, a dynamic hypergraph convolution mechanism is proposed to facilitate adaptive feature exchange and fusion at the hypergraph level. Extensive qualitative and quantitative evaluations of the benchmark image datasets demonstrate that the proposed DVHGNN significantly outperforms the state-of-the-art vision backbones. For instance, our DVHGNN-S achieves an impressive top-1 accuracy of 83.1% on ImageNet-1K, surpassing ViG-S by +1.0% and ViHGNN-S by +0.6%.
CrossVTON: Mimicking the Logic Reasoning on Cross-category Virtual Try-on guided by Tri-zone Priors
Feb 20, 2025



Despite remarkable progress in image-based virtual try-on systems, generating realistic and robust fitting images for cross-category virtual try-on remains a challenging task. The primary difficulty arises from the absence of human-like reasoning, which involves addressing size mismatches between garments and models while recognizing and leveraging the distinct functionalities of various regions within the model images. To address this issue, we draw inspiration from human cognitive processes and disentangle the complex reasoning required for cross-category try-on into a structured framework. This framework systematically decomposes the model image into three distinct regions: try-on, reconstruction, and imagination zones. Each zone plays a specific role in accommodating the garment and facilitating realistic synthesis. To endow the model with robust reasoning capabilities for cross-category scenarios, we propose an iterative data constructor. This constructor encompasses diverse scenarios, including intra-category try-on, any-to-dress transformations (replacing any garment category with a dress), and dress-to-any transformations (replacing a dress with another garment category). Utilizing the generated dataset, we introduce a tri-zone priors generator that intelligently predicts the try-on, reconstruction, and imagination zones by analyzing how the input garment is expected to align with the model image. Guided by these tri-zone priors, our proposed method, CrossVTON, achieves state-of-the-art performance, surpassing existing baselines in both qualitative and quantitative evaluations. Notably, it demonstrates superior capability in handling cross-category virtual try-on, meeting the complex demands of real-world applications.
DAMamba: Vision State Space Model with Dynamic Adaptive Scan
Feb 18, 2025



State space models (SSMs) have recently garnered significant attention in computer vision. However, due to the unique characteristics of image data, adapting SSMs from natural language processing to computer vision has not outperformed the state-of-the-art convolutional neural networks (CNNs) and Vision Transformers (ViTs). Existing vision SSMs primarily leverage manually designed scans to flatten image patches into sequences locally or globally. This approach disrupts the original semantic spatial adjacency of the image and lacks flexibility, making it difficult to capture complex image structures. To address this limitation, we propose Dynamic Adaptive Scan (DAS), a data-driven method that adaptively allocates scanning orders and regions. This enables more flexible modeling capabilities while maintaining linear computational complexity and global modeling capacity. Based on DAS, we further propose the vision backbone DAMamba, which significantly outperforms current state-of-the-art vision Mamba models in vision tasks such as image classification, object detection, instance segmentation, and semantic segmentation. Notably, it surpasses some of the latest state-of-the-art CNNs and ViTs. Code will be available at https://github.com/ltzovo/DAMamba.
VTON-HandFit: Virtual Try-on for Arbitrary Hand Pose Guided by Hand Priors Embedding
Aug 27, 2024
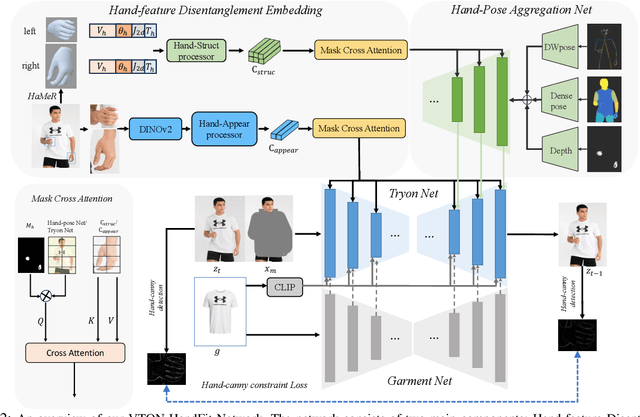


Although diffusion-based image virtual try-on has made considerable progress, emerging approaches still struggle to effectively address the issue of hand occlusion (i.e., clothing regions occluded by the hand part), leading to a notable degradation of the try-on performance. To tackle this issue widely existing in real-world scenarios, we propose VTON-HandFit, leveraging the power of hand priors to reconstruct the appearance and structure for hand occlusion cases. Firstly, we tailor a Handpose Aggregation Net using the ControlNet-based structure explicitly and adaptively encoding the global hand and pose priors. Besides, to fully exploit the hand-related structure and appearance information, we propose Hand-feature Disentanglement Embedding module to disentangle the hand priors into the hand structure-parametric and visual-appearance features, and customize a masked cross attention for further decoupled feature embedding. Lastly, we customize a hand-canny constraint loss to better learn the structure edge knowledge from the hand template of model image. VTON-HandFit outperforms the baselines in qualitative and quantitative evaluations on the public dataset and our self-collected hand-occlusion Handfit-3K dataset particularly for the arbitrary hand pose occlusion cases in real-world scenarios. The Code and dataset will be available at \url{https://github.com/VTON-HandFit/VTON-HandFit}.
Oracle Bone Inscriptions Multi-modal Dataset
Jul 04, 2024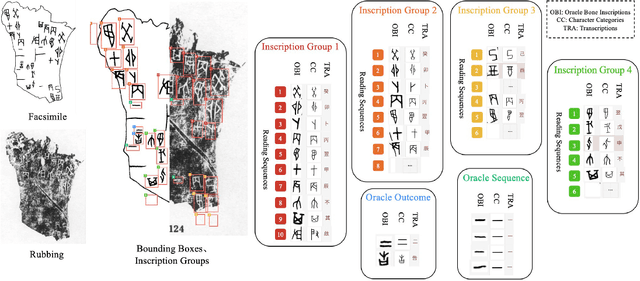
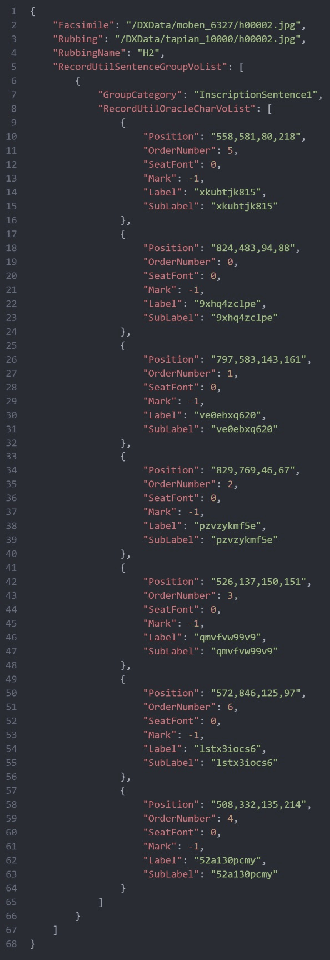
Oracle bone inscriptions(OBI) is the earliest developed writing system in China, bearing invaluable written exemplifications of early Shang history and paleography. However, the task of deciphering OBI, in the current climate of the scholarship, can prove extremely challenging. Out of the 4,500 oracle bone characters excavated, only a third have been successfully identified. Therefore, leveraging the advantages of advanced AI technology to assist in the decipherment of OBI is a highly essential research topic. However, fully utilizing AI's capabilities in these matters is reliant on having a comprehensive and high-quality annotated OBI dataset at hand whereas most existing datasets are only annotated in just a single or a few dimensions, limiting the value of their potential application. For instance, the Oracle-MNIST dataset only offers 30k images classified into 10 categories. Therefore, this paper proposes an Oracle Bone Inscriptions Multi-modal Dataset(OBIMD), which includes annotation information for 10,077 pieces of oracle bones. Each piece has two modalities: pixel-level aligned rubbings and facsimiles. The dataset annotates the detection boxes, character categories, transcriptions, corresponding inscription groups, and reading sequences in the groups of each oracle bone character, providing a comprehensive and high-quality level of annotations. This dataset can be used for a variety of AI-related research tasks relevant to the field of OBI, such as OBI Character Detection and Recognition, Rubbing Denoising, Character Matching, Character Generation, Reading Sequence Prediction, Missing Characters Completion task and so on. We believe that the creation and publication of a dataset like this will help significantly advance the application of AI algorithms in the field of OBI research.
DiffuMatting: Synthesizing Arbitrary Objects with Matting-level Annotation
Mar 10, 2024Due to the difficulty and labor-consuming nature of getting highly accurate or matting annotations, there only exists a limited amount of highly accurate labels available to the public. To tackle this challenge, we propose a DiffuMatting which inherits the strong Everything generation ability of diffusion and endows the power of "matting anything". Our DiffuMatting can 1). act as an anything matting factory with high accurate annotations 2). be well-compatible with community LoRAs or various conditional control approaches to achieve the community-friendly art design and controllable generation. Specifically, inspired by green-screen-matting, we aim to teach the diffusion model to paint on a fixed green screen canvas. To this end, a large-scale greenscreen dataset (Green100K) is collected as a training dataset for DiffuMatting. Secondly, a green background control loss is proposed to keep the drawing board as a pure green color to distinguish the foreground and background. To ensure the synthesized object has more edge details, a detailed-enhancement of transition boundary loss is proposed as a guideline to generate objects with more complicated edge structures. Aiming to simultaneously generate the object and its matting annotation, we build a matting head to make a green color removal in the latent space of the VAE decoder. Our DiffuMatting shows several potential applications (e.g., matting-data generator, community-friendly art design and controllable generation). As a matting-data generator, DiffuMatting synthesizes general object and portrait matting sets, effectively reducing the relative MSE error by 15.4% in General Object Matting and 11.4% in Portrait Matting tasks.
PortraitBooth: A Versatile Portrait Model for Fast Identity-preserved Personalization
Dec 11, 2023



Recent advancements in personalized image generation using diffusion models have been noteworthy. However, existing methods suffer from inefficiencies due to the requirement for subject-specific fine-tuning. This computationally intensive process hinders efficient deployment, limiting practical usability. Moreover, these methods often grapple with identity distortion and limited expression diversity. In light of these challenges, we propose PortraitBooth, an innovative approach designed for high efficiency, robust identity preservation, and expression-editable text-to-image generation, without the need for fine-tuning. PortraitBooth leverages subject embeddings from a face recognition model for personalized image generation without fine-tuning. It eliminates computational overhead and mitigates identity distortion. The introduced dynamic identity preservation strategy further ensures close resemblance to the original image identity. Moreover, PortraitBooth incorporates emotion-aware cross-attention control for diverse facial expressions in generated images, supporting text-driven expression editing. Its scalability enables efficient and high-quality image creation, including multi-subject generation. Extensive results demonstrate superior performance over other state-of-the-art methods in both single and multiple image generation scenarios.
A Unified Framework for 3D Point Cloud Visual Grounding
Aug 23, 2023



3D point cloud visual grounding plays a critical role in 3D scene comprehension, encompassing 3D referring expression comprehension (3DREC) and segmentation (3DRES). We argue that 3DREC and 3DRES should be unified in one framework, which is also a natural progression in the community. To explain, 3DREC can help 3DRES locate the referent, while 3DRES can also facilitate 3DREC via more finegrained language-visual alignment. To achieve this, this paper takes the initiative step to integrate 3DREC and 3DRES into a unified framework, termed 3D Referring Transformer (3DRefTR). Its key idea is to build upon a mature 3DREC model and leverage ready query embeddings and visual tokens from the 3DREC model to construct a dedicated mask branch. Specially, we propose Superpoint Mask Branch, which serves a dual purpose: i) By leveraging the heterogeneous CPU-GPU parallelism, while the GPU is occupied generating visual tokens, the CPU concurrently produces superpoints, equivalently accomplishing the upsampling computation; ii) By harnessing on the inherent association between the superpoints and point cloud, it eliminates the heavy computational overhead on the high-resolution visual features for upsampling. This elegant design enables 3DRefTR to achieve both well-performing 3DRES and 3DREC capacities with only a 6% additional latency compared to the original 3DREC model. Empirical evaluations affirm the superiority of 3DRefTR. Specifically, on the ScanRefer dataset, 3DRefTR surpasses the state-of-the-art 3DRES method by 12.43% in mIoU and improves upon the SOTA 3DREC method by 0.6% Acc@0.25IoU.
CSMPQ:Class Separability Based Mixed-Precision Quantization
Dec 20, 2022Mixed-precision quantization has received increasing attention for its capability of reducing the computational burden and speeding up the inference time. Existing methods usually focus on the sensitivity of different network layers, which requires a time-consuming search or training process. To this end, a novel mixed-precision quantization method, termed CSMPQ, is proposed. Specifically, the TF-IDF metric that is widely used in natural language processing (NLP) is introduced to measure the class separability of layer-wise feature maps. Furthermore, a linear programming problem is designed to derive the optimal bit configuration for each layer. Without any iterative process, the proposed CSMPQ achieves better compression trade-offs than the state-of-the-art quantization methods. Specifically, CSMPQ achieves 73.03$\%$ Top-1 acc on ResNet-18 with only 59G BOPs for QAT, and 71.30$\%$ top-1 acc with only 1.5Mb on MobileNetV2 for PTQ.