 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model
May 06, 2025With the growing requirement for natural human-computer interaction, speech-based systems receive increasing attention as speech is one of the most common forms of daily communication. However, the existing speech models still experience high latency when generating the first audio token during streaming, which poses a significant bottleneck for deployment. To address this issue, we propose VITA-Audio, an end-to-end large speech model with fast audio-text token generation. Specifically, we introduce a lightweight Multiple Cross-modal Token Prediction (MCTP) module that efficiently generates multiple audio tokens within a single model forward pass, which not only accelerates the inference but also significantly reduces the latency for generating the first audio in streaming scenarios. In addition, a four-stage progressive training strategy is explored to achieve model acceleration with minimal loss of speech quality. To our knowledge, VITA-Audio is the first multi-modal large language model capable of generating audio output during the first forward pass, enabling real-time conversational capabilities with minimal latency. VITA-Audio is fully reproducible and is trained on open-source data only. Experimental results demonstrate that our model achieves an inference speedup of 3~5x at the 7B parameter scale, but also significantly outperforms open-source models of similar model size on multiple benchmarks for automatic speech recognition (ASR), text-to-speech (TTS), and spoken question answering (SQA) tasks.
GS-Marker: Generalizable and Robust Watermarking for 3D Gaussian Splatting
Mar 24, 2025



In the Generative AI era, safeguarding 3D models has become increasingly urgent. While invisible watermarking is well-established for 2D images with encoder-decoder frameworks, generalizable and robust solutions for 3D remain elusive. The main difficulty arises from the renderer between the 3D encoder and 2D decoder, which disrupts direct gradient flow and complicates training. Existing 3D methods typically rely on per-scene iterative optimization, resulting in time inefficiency and limited generalization. In this work, we propose a single-pass watermarking approach for 3D Gaussian Splatting (3DGS), a well-known yet underexplored representation for watermarking. We identify two major challenges: (1) ensuring effective training generalized across diverse 3D models, and (2) reliably extracting watermarks from free-view renderings, even under distortions. Our framework, named GS-Marker, incorporates a 3D encoder to embed messages, distortion layers to enhance resilience against various distortions, and a 2D decoder to extract watermarks from renderings. A key innovation is the Adaptive Marker Control mechanism that adaptively perturbs the initially optimized 3DGS, escaping local minima and improving both training stability and convergence. Extensive experiments show that GS-Marker outperforms per-scene training approaches in terms of decoding accuracy and model fidelity, while also significantly reducing computation time.
Diffusion Sampling Correction via Approximately 10 Parameters
Nov 14, 2024



Diffusion Probabilistic Models (DPMs) have demonstrated exceptional performance in generative tasks, but this comes at the expense of sampling efficiency. To enhance sampling speed without sacrificing quality, various distillation-based accelerated sampling algorithms have been recently proposed. However, they typically require significant additional training costs and model parameter storage, which limit their practical application. In this work, we propose PCA-based Adaptive Search (PAS), which optimizes existing solvers for DPMs with minimal learnable parameters and training costs. Specifically, we first employ PCA to obtain a few orthogonal unit basis vectors to span the high-dimensional sampling space, which enables us to learn just a set of coordinates to correct the sampling direction; furthermore, based on the observation that the cumulative truncation error exhibits an ``S''-shape, we design an adaptive search strategy that further enhances the sampling efficiency and reduces the number of stored parameters to approximately 10. Extensive experiments demonstrate that PAS can significantly enhance existing fast solvers in a plug-and-play manner with negligible costs. For instance, on CIFAR10, PAS requires only 12 parameters and less than 1 minute of training on a single NVIDIA A100 GPU to optimize the DDIM from 15.69 FID (NFE=10) to 4.37.
PFDiff: Training-free Acceleration of Diffusion Models through the Gradient Guidance of Past and Future
Aug 16, 2024Diffusion Probabilistic Models (DPMs) have shown remarkable potential in image generation, but their sampling efficiency is hindered by the need for numerous denoising steps. Most existing solutions accelerate the sampling process by proposing fast ODE solvers. However, the inevitable discretization errors of the ODE solvers are significantly magnified when the number of function evaluations (NFE) is fewer. In this work, we propose PFDiff, a novel training-free and orthogonal timestep-skipping strategy, which enables existing fast ODE solvers to operate with fewer NFE. Based on two key observations: a significant similarity in the model's outputs at time step size that is not excessively large during the denoising process of existing ODE solvers, and a high resemblance between the denoising process and SGD. PFDiff, by employing gradient replacement from past time steps and foresight updates inspired by Nesterov momentum, rapidly updates intermediate states, thereby reducing unnecessary NFE while correcting for discretization errors inherent in first-order ODE solvers. Experimental results demonstrate that PFDiff exhibits flexible applicability across various pre-trained DPMs, particularly excelling in conditional DPMs and surpassing previous state-of-the-art training-free methods. For instance, using DDIM as a baseline, we achieved 16.46 FID (4 NFE) compared to 138.81 FID with DDIM on ImageNet 64x64 with classifier guidance, and 13.06 FID (10 NFE) on Stable Diffusion with 7.5 guidance scale.
AutoDiffusion: Training-Free Optimization of Time Steps and Architectures for Automated Diffusion Model Acceleration
Sep 23, 2023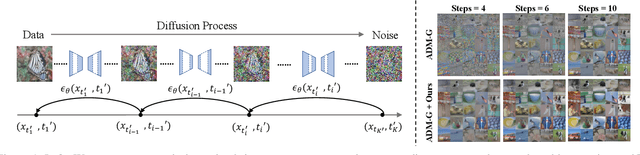

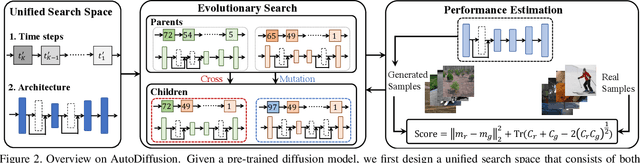
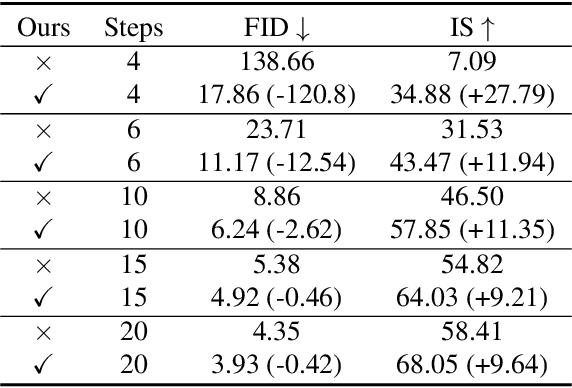
Diffusion models are emerging expressive generative models, in which a large number of time steps (inference steps) are required for a single image generation. To accelerate such tedious process, reducing steps uniformly is considered as an undisputed principle of diffusion models. We consider that such a uniform assumption is not the optimal solution in practice; i.e., we can find different optimal time steps for different models. Therefore, we propose to search the optimal time steps sequence and compressed model architecture in a unified framework to achieve effective image generation for diffusion models without any further training. Specifically, we first design a unified search space that consists of all possible time steps and various architectures. Then, a two stage evolutionary algorithm is introduced to find the optimal solution in the designed search space. To further accelerate the search process, we employ FID score between generated and real samples to estimate the performance of the sampled examples. As a result, the proposed method is (i).training-free, obtaining the optimal time steps and model architecture without any training process; (ii). orthogonal to most advanced diffusion samplers and can be integrated to gain better sample quality. (iii). generalized, where the searched time steps and architectures can be directly applied on different diffusion models with the same guidance scale. Experimental results show that our method achieves excellent performance by using only a few time steps, e.g. 17.86 FID score on ImageNet 64 $\times$ 64 with only four steps, compared to 138.66 with DDIM. The code is available at https://github.com/lilijiangg/AutoDiffusion.
A Unified Framework for 3D Point Cloud Visual Grounding
Aug 23, 2023



3D point cloud visual grounding plays a critical role in 3D scene comprehension, encompassing 3D referring expression comprehension (3DREC) and segmentation (3DRES). We argue that 3DREC and 3DRES should be unified in one framework, which is also a natural progression in the community. To explain, 3DREC can help 3DRES locate the referent, while 3DRES can also facilitate 3DREC via more finegrained language-visual alignment. To achieve this, this paper takes the initiative step to integrate 3DREC and 3DRES into a unified framework, termed 3D Referring Transformer (3DRefTR). Its key idea is to build upon a mature 3DREC model and leverage ready query embeddings and visual tokens from the 3DREC model to construct a dedicated mask branch. Specially, we propose Superpoint Mask Branch, which serves a dual purpose: i) By leveraging the heterogeneous CPU-GPU parallelism, while the GPU is occupied generating visual tokens, the CPU concurrently produces superpoints, equivalently accomplishing the upsampling computation; ii) By harnessing on the inherent association between the superpoints and point cloud, it eliminates the heavy computational overhead on the high-resolution visual features for upsampling. This elegant design enables 3DRefTR to achieve both well-performing 3DRES and 3DREC capacities with only a 6% additional latency compared to the original 3DREC model. Empirical evaluations affirm the superiority of 3DRefTR. Specifically, on the ScanRefer dataset, 3DRefTR surpasses the state-of-the-art 3DRES method by 12.43% in mIoU and improves upon the SOTA 3DREC method by 0.6% Acc@0.25IoU.
Meta Architecure for Point Cloud Analysis
Nov 26, 2022



Recent advances in 3D point cloud analysis bring a diverse set of network architectures to the field. However, the lack of a unified framework to interpret those networks makes any systematic comparison, contrast, or analysis challenging, and practically limits healthy development of the field. In this paper, we take the initiative to explore and propose a unified framework called PointMeta, to which the popular 3D point cloud analysis approaches could fit. This brings three benefits. First, it allows us to compare different approaches in a fair manner, and use quick experiments to verify any empirical observations or assumptions summarized from the comparison. Second, the big picture brought by PointMeta enables us to think across different components, and revisit common beliefs and key design decisions made by the popular approaches. Third, based on the learnings from the previous two analyses, by doing simple tweaks on the existing approaches, we are able to derive a basic building block, termed PointMetaBase. It shows very strong performance in efficiency and effectiveness through extensive experiments on challenging benchmarks, and thus verifies the necessity and benefits of high-level interpretation, contrast, and comparison like PointMeta. In particular, PointMetaBase surpasses the previous state-of-the-art method by 0.7%/1.4/%2.1% mIoU with only 2%/11%/13% of the computation cost on the S3DIS datasets.
What Hinders Perceptual Quality of PSNR-oriented Methods?
Jan 04, 2022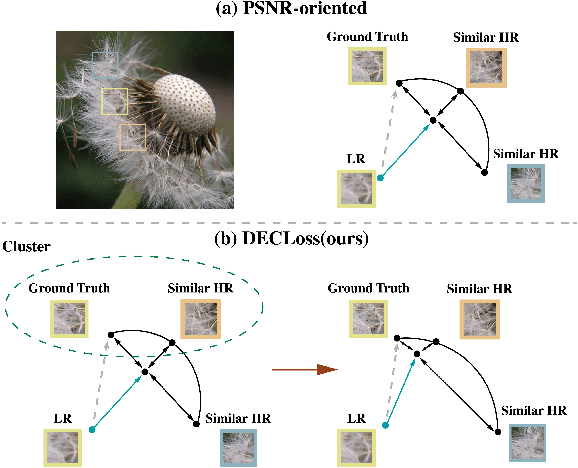
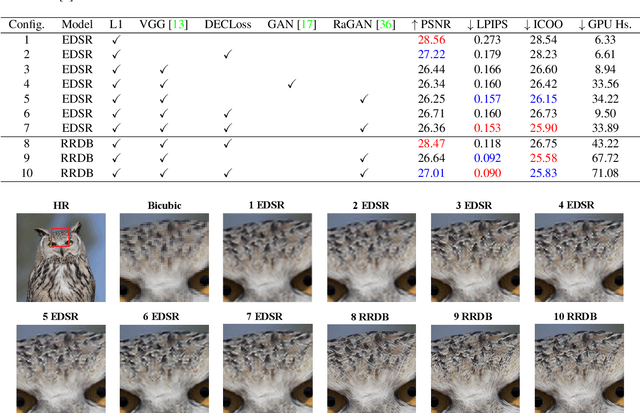
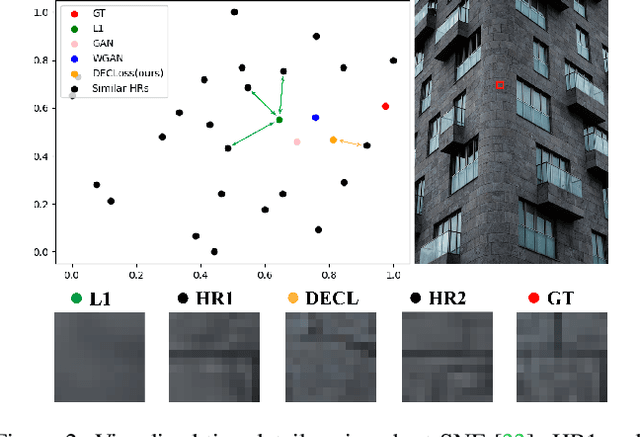
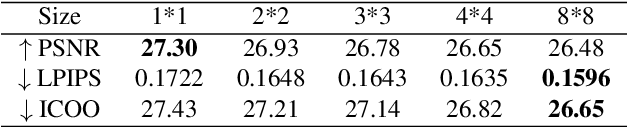
In this paper, we discover two factors that inhibit POMs from achieving high perceptual quality: 1) center-oriented optimization (COO) problem and 2) model's low-frequency tendency. First, POMs tend to generate an SR image whose position in the feature space is closest to the distribution center of all potential high-resolution (HR) images, resulting in such POMs losing high-frequency details. Second, $90\%$ area of an image consists of low-frequency signals; in contrast, human perception relies on an image's high-frequency details. However, POMs apply the same calculation to process different-frequency areas, so that POMs tend to restore the low-frequency regions. Based on these two factors, we propose a Detail Enhanced Contrastive Loss (DECLoss), by combining a high-frequency enhancement module and spatial contrastive learning module, to reduce the influence of the COO problem and low-Frequency tendency. Experimental results show the efficiency and effectiveness when applying DECLoss on several regular SR models. E.g, in EDSR, our proposed method achieves 3.60$\times$ faster learning speed compared to a GAN-based method with a subtle degradation in visual quality. In addition, our final results show that an SR network equipped with our DECLoss generates more realistic and visually pleasing textures compared to state-of-the-art methods. %The source code of the proposed method is included in the supplementary material and will be made publicly available in the future.