 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural auto-designer for enhanced quantum kernels
Jan 20, 2024



Quantum kernels hold great promise for offering computational advantages over classical learners, with the effectiveness of these kernels closely tied to the design of the quantum feature map. However, the challenge of designing effective quantum feature maps for real-world datasets, particularly in the absence of sufficient prior information, remains a significant obstacle. In this study, we present a data-driven approach that automates the design of problem-specific quantum feature maps. Our approach leverages feature-selection techniques to handle high-dimensional data on near-term quantum machines with limited qubits, and incorporates a deep neural predictor to efficiently evaluate the performance of various candidate quantum kernels. Through extensive numerical simulations on different datasets, we demonstrate the superiority of our proposal over prior methods, especially for the capability of eliminating the kernel concentration issue and identifying the feature map with prediction advantages. Our work not only unlocks the potential of quantum kernels for enhancing real-world tasks but also highlights the substantial role of deep learning in advancing quantum machine learning.
Systematic Investigation of Sparse Perturbed Sharpness-Aware Minimization Optimizer
Jun 30, 2023



Deep neural networks often suffer from poor generalization due to complex and non-convex loss landscapes. Sharpness-Aware Minimization (SAM) is a popular solution that smooths the loss landscape by minimizing the maximized change of training loss when adding a perturbation to the weight. However, indiscriminate perturbation of SAM on all parameters is suboptimal and results in excessive computation, double the overhead of common optimizers like Stochastic Gradient Descent (SGD). In this paper, we propose Sparse SAM (SSAM), an efficient and effective training scheme that achieves sparse perturbation by a binary mask. To obtain the sparse mask, we provide two solutions based on Fisher information and dynamic sparse training, respectively. We investigate the impact of different masks, including unstructured, structured, and $N$:$M$ structured patterns, as well as explicit and implicit forms of implementing sparse perturbation. We theoretically prove that SSAM can converge at the same rate as SAM, i.e., $O(\log T/\sqrt{T})$. Sparse SAM has the potential to accelerate training and smooth the loss landscape effectively. Extensive experimental results on CIFAR and ImageNet-1K confirm that our method is superior to SAM in terms of efficiency, and the performance is preserved or even improved with a perturbation of merely 50\% sparsity. Code is available at https://github.com/Mi-Peng/Systematic-Investigation-of-Sparse-Perturbed-Sharpness-Aware-Minimization-Optimizer.
Why can neural language models solve next-word prediction? A mathematical perspective
Jun 20, 2023Recently, deep learning has revolutionized the field of natural language processing, with neural language models proving to be very effective for next-word prediction. However, a rigorous theoretical explanation for their success in the context of formal language theory has not yet been developed, as it is unclear why neural language models can learn the combinatorial rules that govern the next-word prediction task. In this paper, we study a class of formal languages that can be used to model real-world examples of English sentences. We construct neural language models can solve the next-word prediction task in this context with zero error. Our proof highlights the different roles of the embedding layer and the fully connected component within the neural language model.
Active Teacher for Semi-Supervised Object Detection
Mar 15, 2023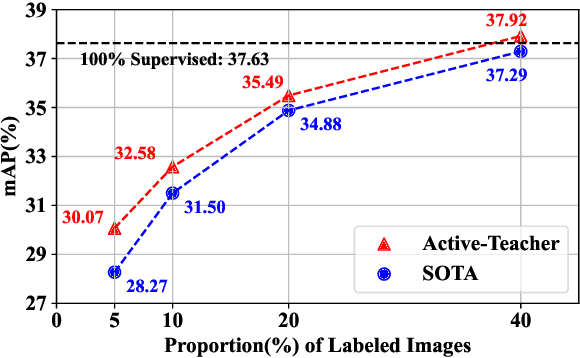



In this paper, we study teacher-student learning from the perspective of data initialization and propose a novel algorithm called Active Teacher(Source code are available at: \url{https://github.com/HunterJ-Lin/ActiveTeacher}) for semi-supervised object detection (SSOD). Active Teacher extends the teacher-student framework to an iterative version, where the label set is partially initialized and gradually augmented by evaluating three key factors of unlabeled examples, including difficulty, information and diversity. With this design, Active Teacher can maximize the effect of limited label information while improving the quality of pseudo-labels. To validate our approach, we conduct extensive experiments on the MS-COCO benchmark and compare Active Teacher with a set of recently proposed SSOD methods. The experimental results not only validate the superior performance gain of Active Teacher over the compared methods, but also show that it enables the baseline network, ie, Faster-RCNN, to achieve 100% supervised performance with much less label expenditure, ie 40% labeled examples on MS-COCO. More importantly, we believe that the experimental analyses in this paper can provide useful empirical knowledge for data annotation in practical applications.
Improving Sharpness-Aware Minimization with Fisher Mask for Better Generalization on Language Models
Oct 11, 2022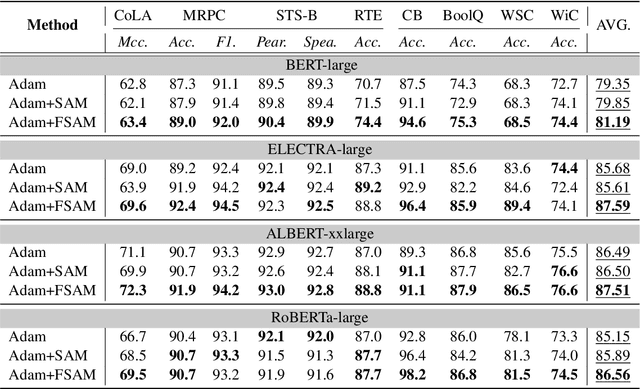
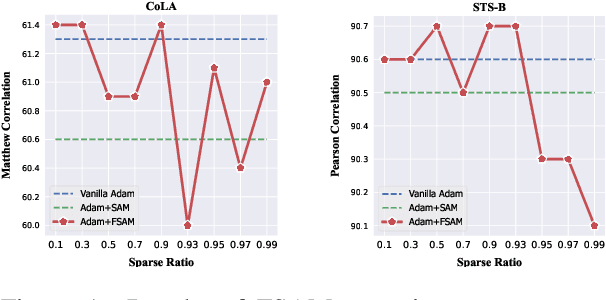
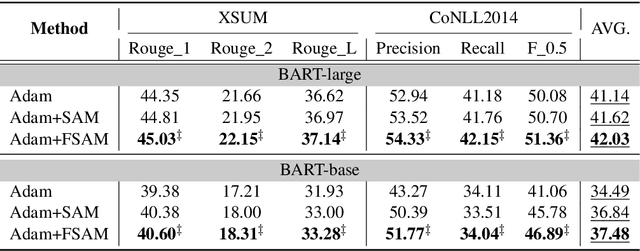
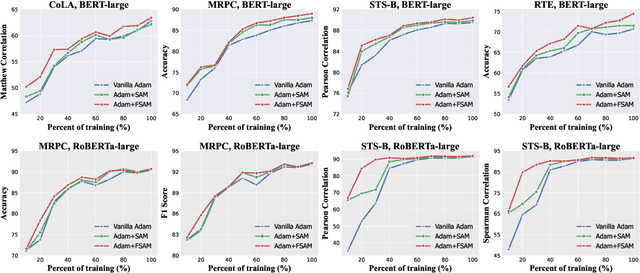
Fine-tuning large pretrained language models on a limited training corpus usually suffers from poor generalization. Prior works show that the recently-proposed sharpness-aware minimization (SAM) optimization method can improve the model generalization. However, SAM adds a perturbation to each model parameter equally (but not all parameters contribute equally to the optimization of training), which we argue is sub-optimal and will lead to excessive computation. In this paper, we propose a novel optimization procedure, namely FSAM, which introduces a Fisher mask to improve the efficiency and performance of SAM. In short, instead of adding perturbation to all parameters, FSAM uses the Fisher information to identity the important parameters and formulates a Fisher mask to obtain the sparse perturbation, i.e., making the optimizer focus on these important parameters. Experiments on various tasks in GLUE and SuperGLUE benchmarks show that FSAM consistently outperforms the vanilla SAM by 0.67~1.98 average score among four different pretrained models. We also empirically show that FSAM works well in other complex scenarios, e.g., fine-tuning on generation tasks or limited training data. Encouragingly, when training data is limited, FSAM improves the SAM by a large margin, i.e., up to 15.1.
Make Sharpness-Aware Minimization Stronger: A Sparsified Perturbation Approach
Oct 11, 2022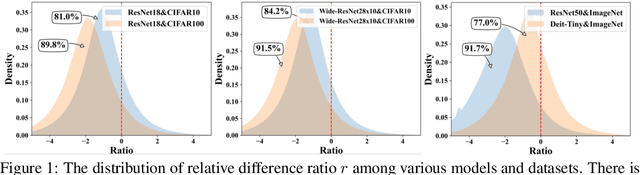
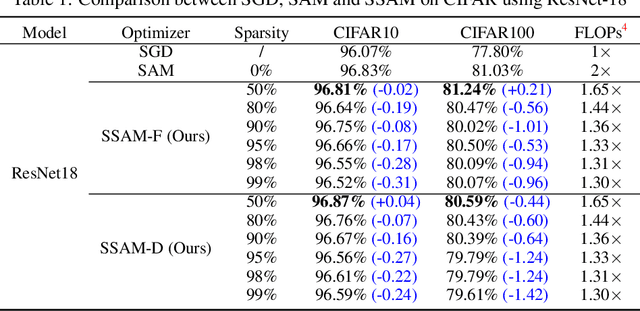
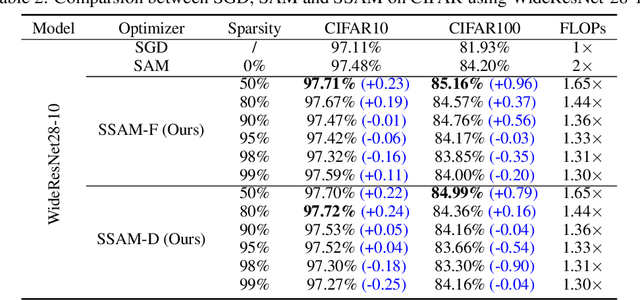
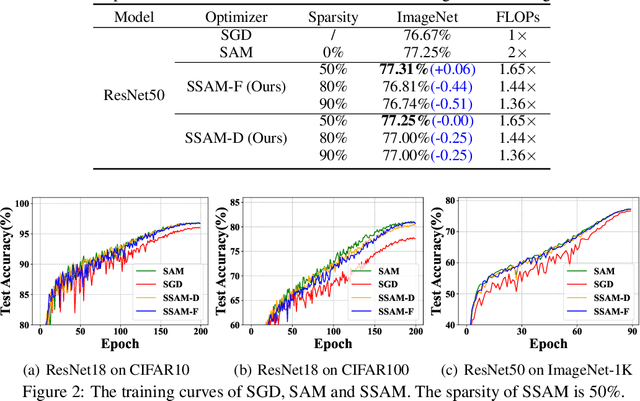
Deep neural networks often suffer from poor generalization caused by complex and non-convex loss landscapes. One of the popular solutions is Sharpness-Aware Minimization (SAM), which smooths the loss landscape via minimizing the maximized change of training loss when adding a perturbation to the weight. However, we find the indiscriminate perturbation of SAM on all parameters is suboptimal, which also results in excessive computation, i.e., double the overhead of common optimizers like Stochastic Gradient Descent (SGD). In this paper, we propose an efficient and effective training scheme coined as Sparse SAM (SSAM), which achieves sparse perturbation by a binary mask. To obtain the sparse mask, we provide two solutions which are based onFisher information and dynamic sparse training, respectively. In addition, we theoretically prove that SSAM can converge at the same rate as SAM, i.e., $O(\log T/\sqrt{T})$. Sparse SAM not only has the potential for training acceleration but also smooths the loss landscape effectively. Extensive experimental results on CIFAR10, CIFAR100, and ImageNet-1K confirm the superior efficiency of our method to SAM, and the performance is preserved or even better with a perturbation of merely 50% sparsity. Code is availiable at \url{https://github.com/Mi-Peng/Sparse-Sharpness-Aware-Minimization}.
What Hinders Perceptual Quality of PSNR-oriented Methods?
Jan 04, 2022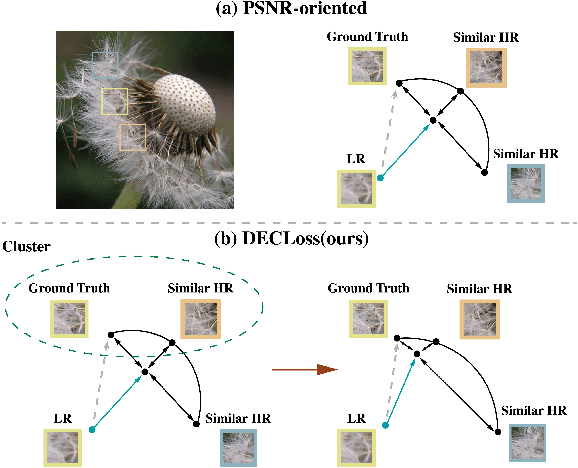
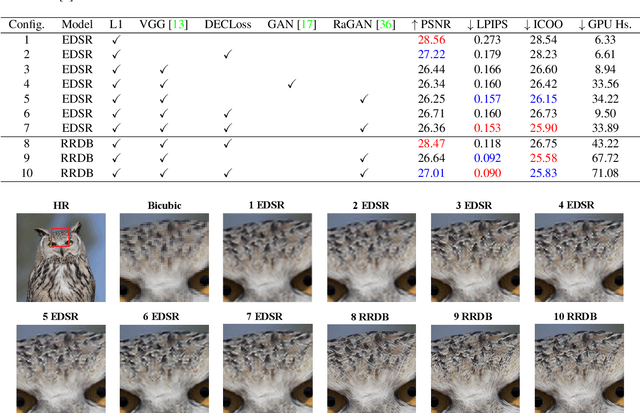
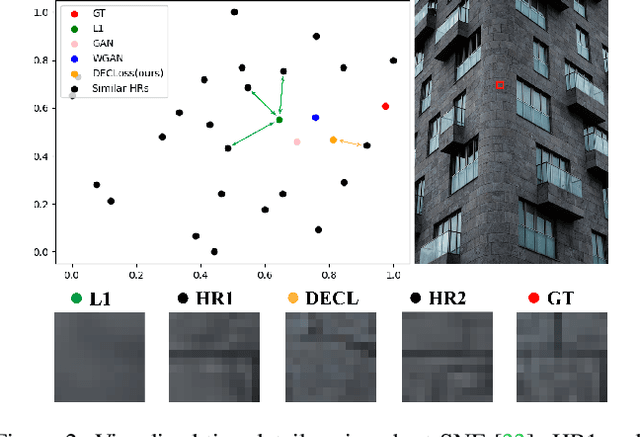
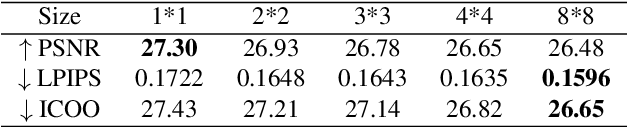
In this paper, we discover two factors that inhibit POMs from achieving high perceptual quality: 1) center-oriented optimization (COO) problem and 2) model's low-frequency tendency. First, POMs tend to generate an SR image whose position in the feature space is closest to the distribution center of all potential high-resolution (HR) images, resulting in such POMs losing high-frequency details. Second, $90\%$ area of an image consists of low-frequency signals; in contrast, human perception relies on an image's high-frequency details. However, POMs apply the same calculation to process different-frequency areas, so that POMs tend to restore the low-frequency regions. Based on these two factors, we propose a Detail Enhanced Contrastive Loss (DECLoss), by combining a high-frequency enhancement module and spatial contrastive learning module, to reduce the influence of the COO problem and low-Frequency tendency. Experimental results show the efficiency and effectiveness when applying DECLoss on several regular SR models. E.g, in EDSR, our proposed method achieves 3.60$\times$ faster learning speed compared to a GAN-based method with a subtle degradation in visual quality. In addition, our final results show that an SR network equipped with our DECLoss generates more realistic and visually pleasing textures compared to state-of-the-art methods. %The source code of the proposed method is included in the supplementary material and will be made publicly available in the future.