 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-Marker: Generalizable and Robust Watermarking for 3D Gaussian Splatting
Mar 24, 2025



In the Generative AI era, safeguarding 3D models has become increasingly urgent. While invisible watermarking is well-established for 2D images with encoder-decoder frameworks, generalizable and robust solutions for 3D remain elusive. The main difficulty arises from the renderer between the 3D encoder and 2D decoder, which disrupts direct gradient flow and complicates training. Existing 3D methods typically rely on per-scene iterative optimization, resulting in time inefficiency and limited generalization. In this work, we propose a single-pass watermarking approach for 3D Gaussian Splatting (3DGS), a well-known yet underexplored representation for watermarking. We identify two major challenges: (1) ensuring effective training generalized across diverse 3D models, and (2) reliably extracting watermarks from free-view renderings, even under distortions. Our framework, named GS-Marker, incorporates a 3D encoder to embed messages, distortion layers to enhance resilience against various distortions, and a 2D decoder to extract watermarks from renderings. A key innovation is the Adaptive Marker Control mechanism that adaptively perturbs the initially optimized 3DGS, escaping local minima and improving both training stability and convergence. Extensive experiments show that GS-Marker outperforms per-scene training approaches in terms of decoding accuracy and model fidelity, while also significantly reducing computation time.
High-Fidelity and Freely Controllable Talking Head Video Generation
Apr 20, 2023
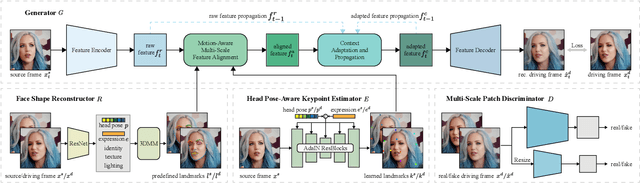
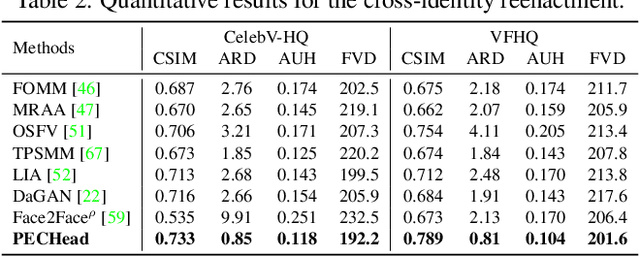
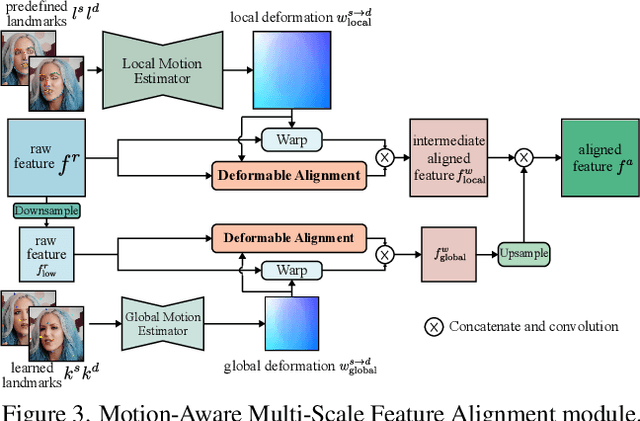
Talking head generation is to generate video based on a given source identity and target motion. However, current methods face several challenges that limit the quality and controllability of the generated videos. First, the generated face often has unexpected deformation and severe distortions. Second, the driving image does not explicitly disentangle movement-relevant information, such as poses and expressions, which restricts the manipulation of different attributes during generation. Third, the generated videos tend to have flickering artifacts due to the inconsistency of the extracted landmarks between adjacent frames. In this paper, we propose a novel model that produces high-fidelity talking head videos with free control over head pose and expression. Our method leverages both self-supervised learned landmarks and 3D face model-based landmarks to model the motion. We also introduce a novel motion-aware multi-scale feature alignment module to effectively transfer the motion without face distortion. Furthermore, we enhance the smoothness of the synthesized talking head videos with a feature context adaptation and propagation module. We evaluate our model on challenging datasets and demonstrate its state-of-the-art performance. More information is available at https://yuegao.me/PECHead.
Towards Robust Video Object Segmentation with Adaptive Object Calibration
Jul 02, 2022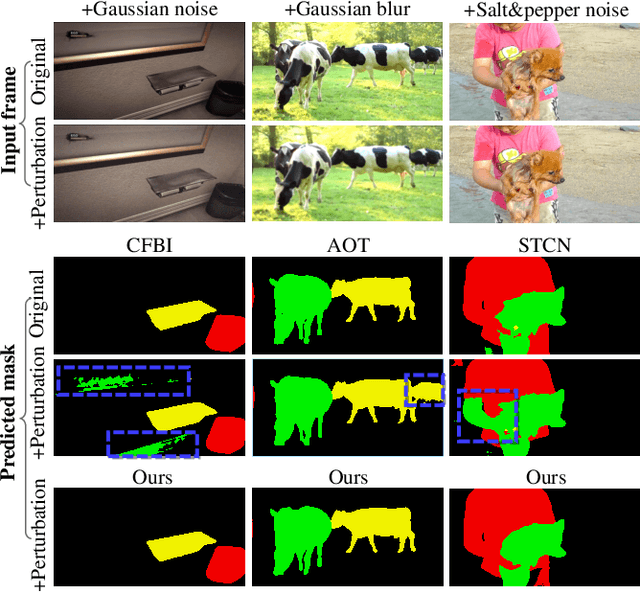

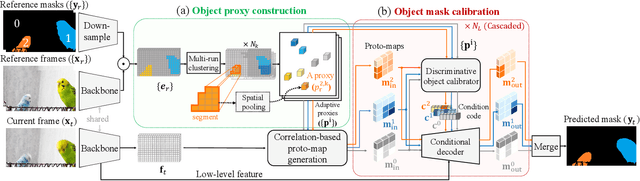
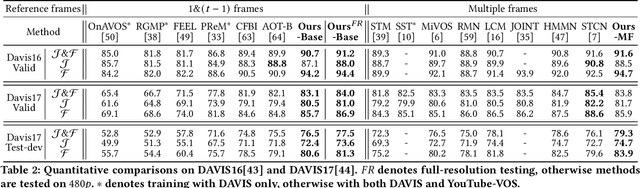
In the booming video era, video segmentation attracts increasing research attention in the multimedia community. Semi-supervised video object segmentation (VOS) aims at segmenting objects in all target frames of a video, given annotated object masks of reference frames. Most existing methods build pixel-wise reference-target correlations and then perform pixel-wise tracking to obtain target masks. Due to neglecting object-level cues, pixel-level approaches make the tracking vulnerable to perturbations, and even indiscriminate among similar objects. Towards robust VOS, the key insight is to calibrate the representation and mask of each specific object to be expressive and discriminative. Accordingly, we propose a new deep network, which can adaptively construct object representations and calibrate object masks to achieve stronger robustness. First, we construct the object representations by applying an adaptive object proxy (AOP) aggregation method, where the proxies represent arbitrary-shaped segments at multi-levels for reference. Then, prototype masks are initially generated from the reference-target correlations based on AOP. Afterwards, such proto-masks are further calibrated through network modulation, conditioning on the object proxy representations. We consolidate this conditional mask calibration process in a progressive manner, where the object representations and proto-masks evolve to be discriminative iteratively. Extensive experiments are conducted on the standard VOS benchmarks, YouTube-VOS-18/19 and DAVIS-17. Our model achieves the state-of-the-art performance among existing published works, and also exhibits superior robustness against perturbations. Our project repo is at https://github.com/JerryX1110/Robust-Video-Object-Segmentation
Design and Interpretation of Universal Adversarial Patches in Face Detection
Nov 30, 2019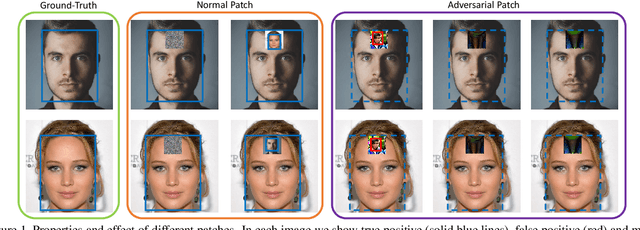


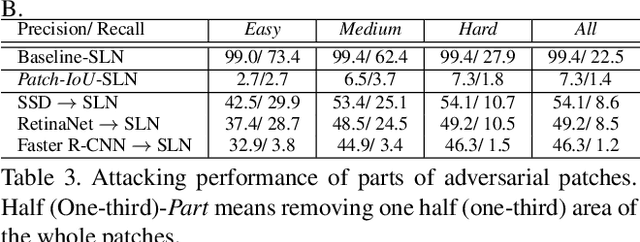
We consider universal adversarial patches for faces - small visual elements whose addition to a face image reliably destroys the performance of face detectors. Unlike previous work that mostly focused on the algorithmic design of adversarial examples in terms of improving the success rate as an attacker, in this work we show an interpretation of such patches that can prevent the state-of-the-art face detectors from detecting the real faces. We investigate a phenomenon: patches designed to suppress real face detection appear face-like. This phenomenon holds generally across different initialization, locations, scales of patches, backbones, and state-of-the-art face detection frameworks. We propose new optimization-based approaches to automatic design of universal adversarial patches for varying goals of the attack, including scenarios in which true positives are suppressed without introducing false positives. Our proposed algorithms perform well on real-world datasets, deceiving state-of-the-art face detectors in terms of multiple precision/recall metrics and transferring between different detection frameworks.
WIDER Face and Pedestrian Challenge 2018: Methods and Results
Feb 19, 2019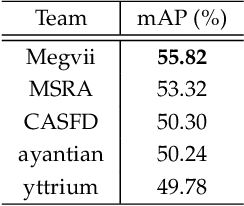

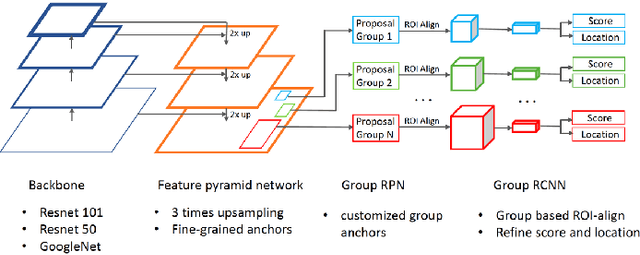
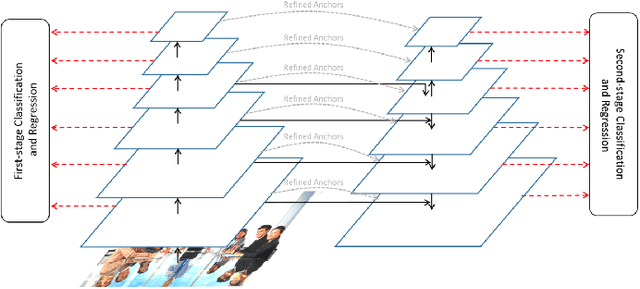
This paper presents a review of the 2018 WIDER Challenge on Face and Pedestrian. The challenge focuses on the problem of precise localization of human faces and bodies, and accurate association of identities. It comprises of three tracks: (i) WIDER Face which aims at soliciting new approaches to advance the state-of-the-art in face detection, (ii) WIDER Pedestrian which aims to find effective and efficient approaches to address the problem of pedestrian detection in unconstrained environments, and (iii) WIDER Person Search which presents an exciting challenge of searching persons across 192 movies. In total, 73 teams made valid submissions to the challenge tracks. We summarize the winning solutions for all three tracks. and present discussions on open problems and potential research directions in these topics.
Efficient and Accurate Approximations of Nonlinear Convolutional Networks
Nov 16, 2014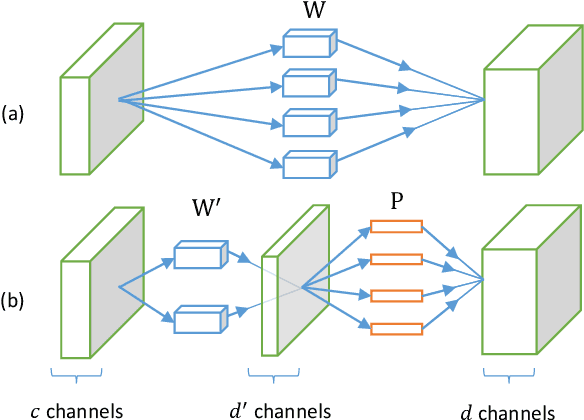
This paper aims to accelerate the test-time computation of deep convolutional neural networks (CNNs). Unlike existing methods that are designed for approximating linear filters or linear responses, our method takes the nonlinear units into account. We minimize the reconstruction error of the nonlinear responses, subject to a low-rank constraint which helps to reduce the complexity of filters. We develop an effective solution to this constrained nonlinear optimization problem. An algorithm is also presented for reducing the accumulated error when multiple layers are approximated. A whole-model speedup ratio of 4x is demonstrated on a large network trained for ImageNet, while the top-5 error rate is only increased by 0.9%. Our accelerated model has a comparably fast speed as the "AlexNet", but is 4.7% more accurate.