 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Video Object Segmentation with Adaptive Object Calibration
Paper and Code
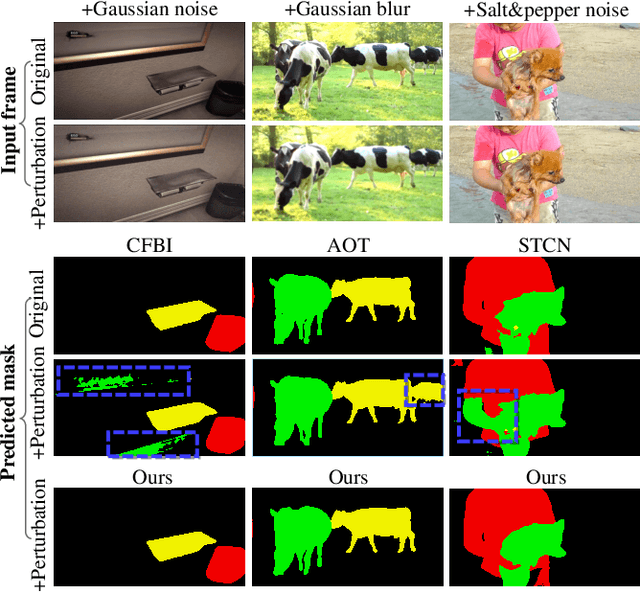

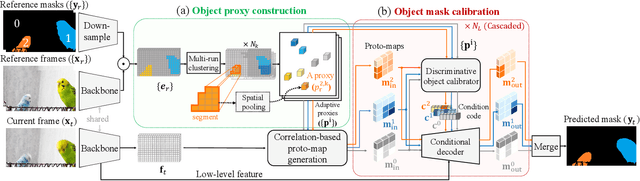
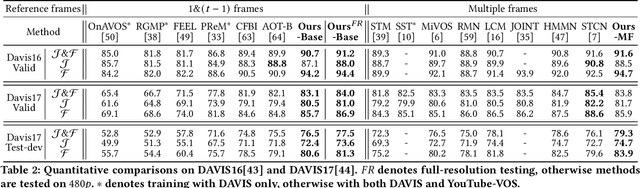
In the booming video era, video segmentation attracts increasing research attention in the multimedia community. Semi-supervised video object segmentation (VOS) aims at segmenting objects in all target frames of a video, given annotated object masks of reference frames. Most existing methods build pixel-wise reference-target correlations and then perform pixel-wise tracking to obtain target masks. Due to neglecting object-level cues, pixel-level approaches make the tracking vulnerable to perturbations, and even indiscriminate among similar objects. Towards robust VOS, the key insight is to calibrate the representation and mask of each specific object to be expressive and discriminative. Accordingly, we propose a new deep network, which can adaptively construct object representations and calibrate object masks to achieve stronger robustness. First, we construct the object representations by applying an adaptive object proxy (AOP) aggregation method, where the proxies represent arbitrary-shaped segments at multi-levels for reference. Then, prototype masks are initially generated from the reference-target correlations based on AOP. Afterwards, such proto-masks are further calibrated through network modulation, conditioning on the object proxy representations. We consolidate this conditional mask calibration process in a progressive manner, where the object representations and proto-masks evolve to be discriminative iteratively. Extensive experiments are conducted on the standard VOS benchmarks, YouTube-VOS-18/19 and DAVIS-17. Our model achieves the state-of-the-art performance among existing published works, and also exhibits superior robustness against perturbations. Our project repo is at https://github.com/JerryX1110/Robust-Video-Object-Segmentation