 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuoTA: Query-oriented Token Assignment via CoT Query Decouple for Long Video Comprehension
Mar 11, 2025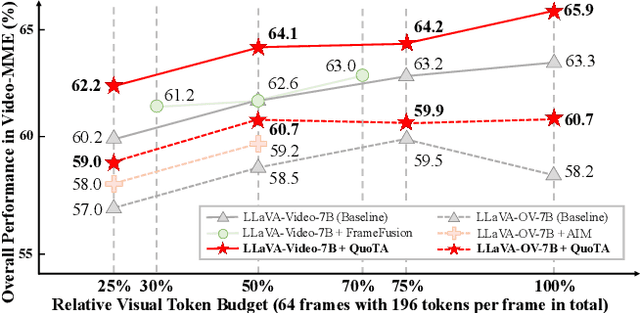
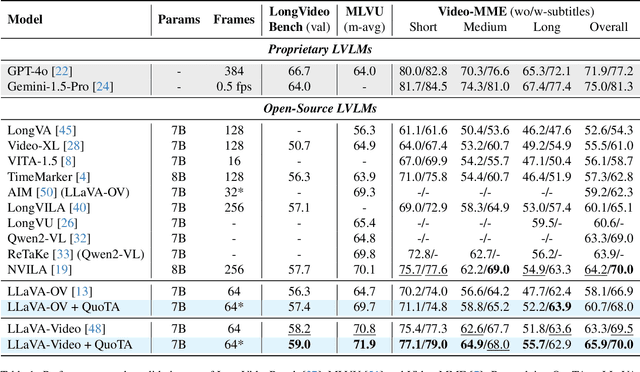
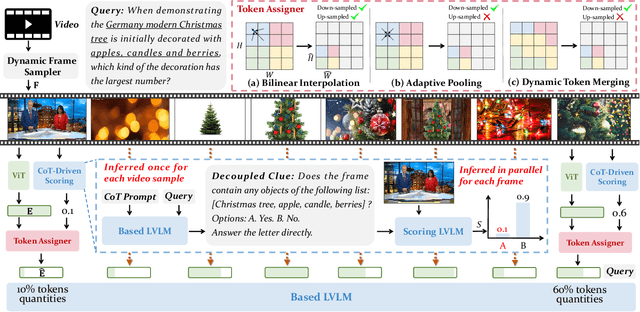
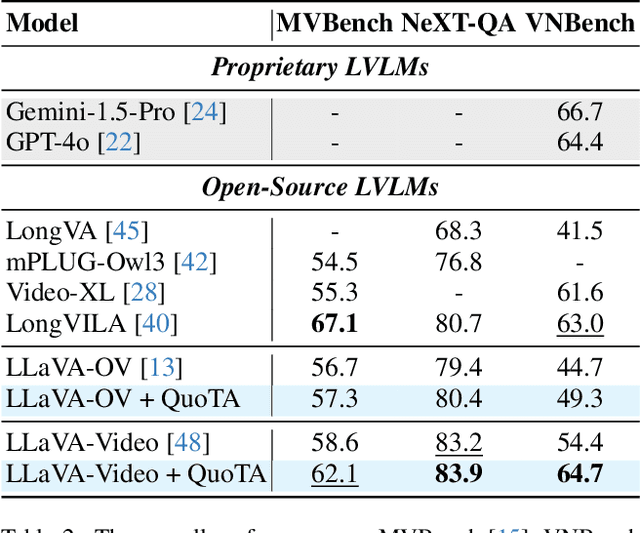
Recent advances in long video understanding typically mitigate visual redundancy through visual token pruning based on attention distribution. However, while existing methods employ post-hoc low-response token pruning in decoder layers, they overlook the input-level semantic correlation between visual tokens and instructions (query). In this paper, we propose QuoTA, an ante-hoc training-free modular that extends existing large video-language models (LVLMs) for visual token assignment based on query-oriented frame-level importance assessment. The query-oriented token selection is crucial as it aligns visual processing with task-specific requirements, optimizing token budget utilization while preserving semantically relevant content. Specifically, (i) QuoTA strategically allocates frame-level importance scores based on query relevance, enabling one-time visual token assignment before cross-modal interactions in decoder layers, (ii) we decouple the query through Chain-of-Thoughts reasoning to facilitate more precise LVLM-based frame importance scoring, and (iii) QuoTA offers a plug-and-play functionality that extends to existing LVLMs. Extensive experimental results demonstrate that implementing QuoTA with LLaVA-Video-7B yields an average performance improvement of 3.2% across six benchmarks (including Video-MME and MLVU) while operating within an identical visual token budget as the baseline. Codes are open-sourced at https://github.com/MAC-AutoML/QuoTA.
Video-RAG: Visually-aligned Retrieval-Augmented Long Video Comprehension
Nov 20, 2024


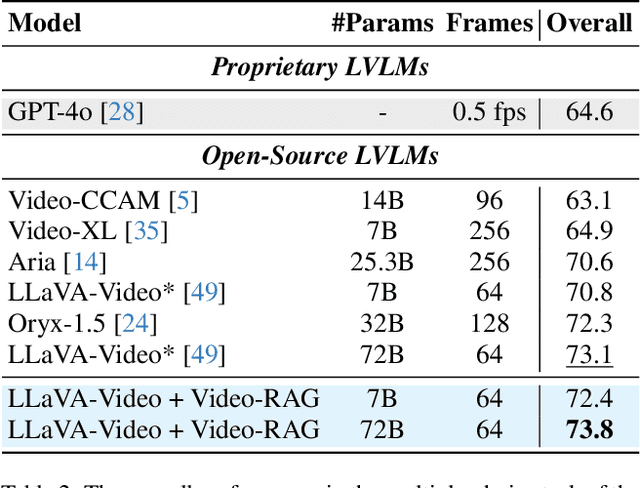
Existing large video-language models (LVLMs) struggle to comprehend long videos correctly due to limited context. To address this problem, fine-tuning long-context LVLMs and employing GPT-based agents have emerged as promising solutions. However, fine-tuning LVLMs would require extensive high-quality data and substantial GPU resources, while GPT-based agents would rely on proprietary models (e.g., GPT-4o). In this paper, we propose Video Retrieval-Augmented Generation (Video-RAG), a training-free and cost-effective pipeline that employs visually-aligned auxiliary texts to help facilitate cross-modality alignment while providing additional information beyond the visual content. Specifically, we leverage open-source external tools to extract visually-aligned information from pure video data (e.g., audio, optical character, and object detection), and incorporate the extracted information into an existing LVLM as auxiliary texts, alongside video frames and queries, in a plug-and-play manner. Our Video-RAG offers several key advantages: (i) lightweight with low computing overhead due to single-turn retrieval; (ii) easy implementation and compatibility with any LVLM; and (iii) significant, consistent performance gains across long video understanding benchmarks, including Video-MME, MLVU, and LongVideoBench. Notably, our model demonstrates superior performance over proprietary models like Gemini-1.5-Pro and GPT-4o when utilized with a 72B model.
Rethinking 3D Dense Caption and Visual Grounding in A Unified Framework through Prompt-based Localization
Apr 17, 20243D Visual Grounding (3DVG) and 3D Dense Captioning (3DDC) are two crucial tasks in various 3D applications, which require both shared and complementary information in localization and visual-language relationships. Therefore, existing approaches adopt the two-stage "detect-then-describe/discriminate" pipeline, which relies heavily on the performance of the detector, resulting in suboptimal performance. Inspired by DETR, we propose a unified framework, 3DGCTR, to jointly solve these two distinct but closely related tasks in an end-to-end fashion. The key idea is to reconsider the prompt-based localization ability of the 3DVG model. In this way, the 3DVG model with a well-designed prompt as input can assist the 3DDC task by extracting localization information from the prompt. In terms of implementation, we integrate a Lightweight Caption Head into the existing 3DVG network with a Caption Text Prompt as a connection, effectively harnessing the existing 3DVG model's inherent localization capacity, thereby boosting 3DDC capability. This integration facilitates simultaneous multi-task training on both tasks, mutually enhancing their performance. Extensive experimental results demonstrate the effectiveness of this approach. Specifically, on the ScanRefer dataset, 3DGCTR surpasses the state-of-the-art 3DDC method by 4.3% in CIDEr@0.5IoU in MLE training and improves upon the SOTA 3DVG method by 3.16% in Acc@0.25IoU.
A Unified Framework for 3D Point Cloud Visual Grounding
Aug 23, 2023



3D point cloud visual grounding plays a critical role in 3D scene comprehension, encompassing 3D referring expression comprehension (3DREC) and segmentation (3DRES). We argue that 3DREC and 3DRES should be unified in one framework, which is also a natural progression in the community. To explain, 3DREC can help 3DRES locate the referent, while 3DRES can also facilitate 3DREC via more finegrained language-visual alignment. To achieve this, this paper takes the initiative step to integrate 3DREC and 3DRES into a unified framework, termed 3D Referring Transformer (3DRefTR). Its key idea is to build upon a mature 3DREC model and leverage ready query embeddings and visual tokens from the 3DREC model to construct a dedicated mask branch. Specially, we propose Superpoint Mask Branch, which serves a dual purpose: i) By leveraging the heterogeneous CPU-GPU parallelism, while the GPU is occupied generating visual tokens, the CPU concurrently produces superpoints, equivalently accomplishing the upsampling computation; ii) By harnessing on the inherent association between the superpoints and point cloud, it eliminates the heavy computational overhead on the high-resolution visual features for upsampling. This elegant design enables 3DRefTR to achieve both well-performing 3DRES and 3DREC capacities with only a 6% additional latency compared to the original 3DREC model. Empirical evaluations affirm the superiority of 3DRefTR. Specifically, on the ScanRefer dataset, 3DRefTR surpasses the state-of-the-art 3DRES method by 12.43% in mIoU and improves upon the SOTA 3DREC method by 0.6% Acc@0.25IoU.