 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASBench: Image Anomalies Synthesis Benchmark for Anomaly Detection
Oct 09, 2025Anomaly detection plays a pivotal role in manufacturing quality control, yet its application is constrained by limited abnormal samples and high manual annotation costs. While anomaly synthesis offers a promising solution, existing studies predominantly treat anomaly synthesis as an auxiliary component within anomaly detection frameworks, lacking systematic evaluation of anomaly synthesis algorithms. Current research also overlook crucial factors specific to anomaly synthesis, such as decoupling its impact from detection, quantitative analysis of synthetic data and adaptability across different scenarios. To address these limitations, we propose ASBench, the first comprehensive benchmarking framework dedicated to evaluating anomaly synthesis methods. Our framework introduces four critical evaluation dimensions: (i) the generalization performance across different datasets and pipelines (ii) the ratio of synthetic to real data (iii) the correlation between intrinsic metrics of synthesis images and anomaly detection performance metrics , and (iv) strategies for hybrid anomaly synthesis methods. Through extensive experiments, ASBench not only reveals limitations in current anomaly synthesis methods but also provides actionable insights for future research directions in anomaly synthesis
ROAD: Responsibility-Oriented Reward Design for Reinforcement Learning in Autonomous Driving
May 30, 2025Reinforcement learning (RL) in autonomous driving employs a trial-and-error mechanism, enhancing robustness in unpredictable environments. However, crafting effective reward functions remains challenging, as conventional approaches rely heavily on manual design and demonstrate limited efficacy in complex scenarios. To address this issue, this study introduces a responsibility-oriented reward function that explicitly incorporates traffic regulations into the RL framework. Specifically, we introduced a Traffic Regulation Knowledge Graph and leveraged Vision-Language Models alongside Retrieval-Augmented Generation techniques to automate reward assignment. This integration guides agents to adhere strictly to traffic laws, thus minimizing rule violations and optimizing decision-making performance in diverse driving conditions. Experimental validations demonstrate that the proposed methodology significantly improves the accuracy of assigning accident responsibilities and effectively reduces the agent's liability in traffic incidents.
Learning-based 3D Reconstruction in Autonomous Driving: A Comprehensive Survey
Mar 17, 2025Learning-based 3D reconstruction has emerged as a transformative technique in autonomous driving, enabling precise modeling of both dynamic and static environments through advanced neural representations. Despite augmenting perception, 3D reconstruction inspires pioneering solution for vital tasks in the field of autonomous driving, such as scene understanding and closed-loop simulation. Commencing with an examination of input modalities, we investigates the details of 3D reconstruction and conducts a multi-perspective, in-depth analysis of recent advancements. Specifically, we first provide a systematic introduction of preliminaries, including data formats, benchmarks and technical preliminaries of learning-based 3D reconstruction, facilitating instant identification of suitable methods based on hardware configurations and sensor suites. Then, we systematically review learning-based 3D reconstruction methods in autonomous driving, categorizing approaches by subtasks and conducting multi-dimensional analysis and summary to establish a comprehensive technical reference. The development trends and existing challenges is summarized in the context of learning-based 3D reconstruction in autonomous driving. We hope that our review will inspire future researches.
Leverage Knowledge Graph and Large Language Model for Law Article Recommendation: A Case Study of Chinese Criminal Law
Oct 07, 2024


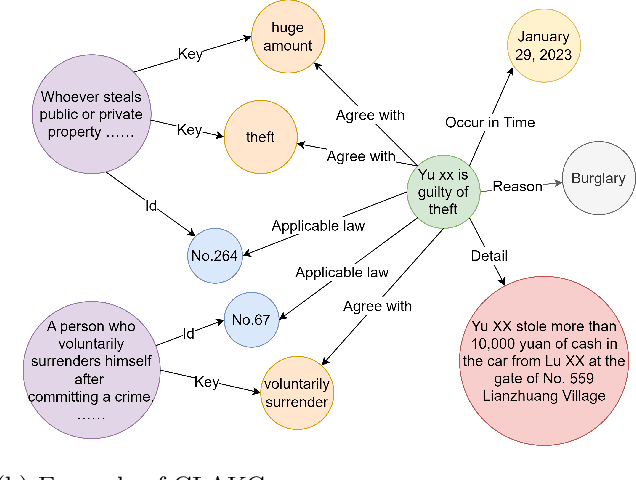
Court efficiency is vital for social stability. However, in most countries around the world, the grassroots courts face case backlogs, with decisions relying heavily on judicial personnel's cognitive labor, lacking intelligent tools to improve efficiency. To address this issue, we propose an efficient law article recommendation approach utilizing a Knowledge Graph (KG) and a Large Language Model (LLM). Firstly, we propose a Case-Enhanced Law Article Knowledge Graph (CLAKG) as a database to store current law statutes, historical case information, and correspondence between law articles and historical cases. Additionally, we introduce an automated CLAKG construction method based on LLM. On this basis, we propose a closed-loop law article recommendation method. Finally, through a series of experiments using judgment documents from the website "China Judgements Online", we have improved the accuracy of law article recommendation in cases from 0.549 to 0.694, demonstrating that our proposed method significantly outperforms baseline approaches.
End-to-end Driving in High-Interaction Traffic Scenarios with Reinforcement Learning
Oct 03, 2024Dynamic and interactive traffic scenarios pose significant challenges for autonomous driving systems. Reinforcement learning (RL) offers a promising approach by enabling the exploration of driving policies beyond the constraints of pre-collected datasets and predefined conditions, particularly in complex environments. However, a critical challenge lies in effectively extracting spatial and temporal features from sequences of high-dimensional, multi-modal observations while minimizing the accumulation of errors over time. Additionally, efficiently guiding large-scale RL models to converge on optimal driving policies without frequent failures during the training process remains tricky. We propose an end-to-end model-based RL algorithm named Ramble to address these issues. Ramble processes multi-view RGB images and LiDAR point clouds into low-dimensional latent features to capture the context of traffic scenarios at each time step. A transformer-based architecture is then employed to model temporal dependencies and predict future states. By learning a dynamics model of the environment, Ramble can foresee upcoming traffic events and make more informed, strategic decisions. Our implementation demonstrates that prior experience in feature extraction and decision-making plays a pivotal role in accelerating the convergence of RL models toward optimal driving policies. Ramble achieves state-of-the-art performance regarding route completion rate and driving score on the CARLA Leaderboard 2.0, showcasing its effectiveness in managing complex and dynamic traffic situations.
CamoTeacher: Dual-Rotation Consistency Learning for Semi-Supervised Camouflaged Object Detection
Aug 15, 2024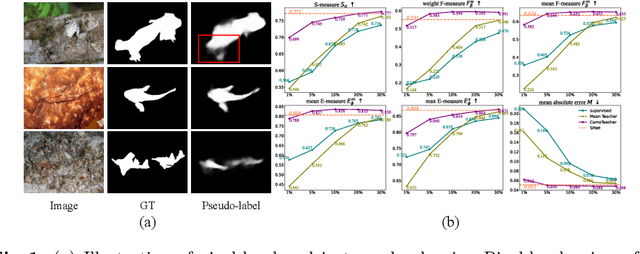
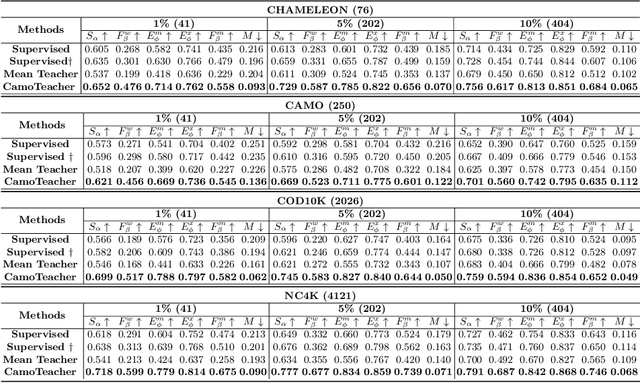
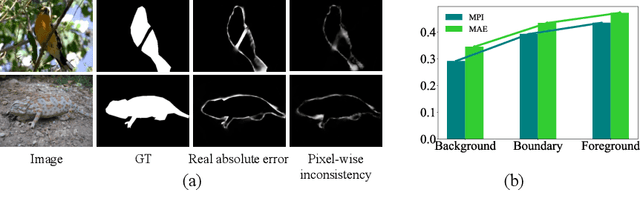
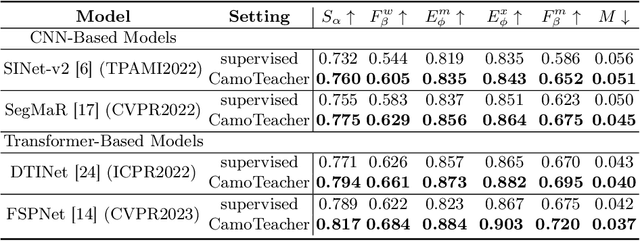
Existing camouflaged object detection~(COD) methods depend heavily on large-scale pixel-level annotations.However, acquiring such annotations is laborious due to the inherent camouflage characteristics of the objects.Semi-supervised learning offers a promising solution to this challenge.Yet, its application in COD is hindered by significant pseudo-label noise, both pixel-level and instance-level.We introduce CamoTeacher, a novel semi-supervised COD framework, utilizing Dual-Rotation Consistency Learning~(DRCL) to effectively address these noise issues.Specifically, DRCL minimizes pseudo-label noise by leveraging rotation views' consistency in pixel-level and instance-level.First, it employs Pixel-wise Consistency Learning~(PCL) to deal with pixel-level noise by reweighting the different parts within the pseudo-label.Second, Instance-wise Consistency Learning~(ICL) is used to adjust weights for pseudo-labels, which handles instance-level noise.Extensive experiments on four COD benchmark datasets demonstrate that the proposed CamoTeacher not only achieves state-of-the-art compared with semi-supervised learning methods, but also rivals established fully-supervised learning methods.Our code will be available soon.
HOPE: A Reinforcement Learning-based Hybrid Policy Path Planner for Diverse Parking Scenarios
May 31, 2024
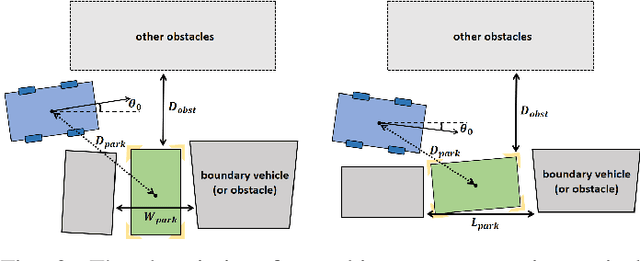


Path planning plays a pivotal role in automated parking, yet current methods struggle to efficiently handle the intricate and diverse parking scenarios. One potential solution is the reinforcement learning-based method, leveraging its exploration in unrecorded situations. However, a key challenge lies in training reinforcement learning methods is the inherent randomness in converging to a feasible policy. This paper introduces a novel solution, the Hybrid POlicy Path plannEr (HOPE), which integrates a reinforcement learning agent with Reeds-Shepp curves, enabling effective planning across diverse scenarios. The paper presents a method to calculate and implement an action mask mechanism in path planning, significantly boosting the efficiency and effectiveness of reinforcement learning training. A transformer is employed as the network structure to fuse environmental information and generate planned paths. To facilitate the training and evaluation of the proposed planner, we propose a criterion for categorizing the difficulty level of parking scenarios based on space and obstacle distribution. Experimental results demonstrate that our approach outperforms typical rule-based algorithms and traditional reinforcement learning methods, showcasing higher planning success rates and generalization across various scenarios. The code for our solution will be openly available on \href{GitHub}{https://github.com/jiamiya/HOPE}. % after the paper's acceptance.
Rethinking 3D Dense Caption and Visual Grounding in A Unified Framework through Prompt-based Localization
Apr 17, 20243D Visual Grounding (3DVG) and 3D Dense Captioning (3DDC) are two crucial tasks in various 3D applications, which require both shared and complementary information in localization and visual-language relationships. Therefore, existing approaches adopt the two-stage "detect-then-describe/discriminate" pipeline, which relies heavily on the performance of the detector, resulting in suboptimal performance. Inspired by DETR, we propose a unified framework, 3DGCTR, to jointly solve these two distinct but closely related tasks in an end-to-end fashion. The key idea is to reconsider the prompt-based localization ability of the 3DVG model. In this way, the 3DVG model with a well-designed prompt as input can assist the 3DDC task by extracting localization information from the prompt. In terms of implementation, we integrate a Lightweight Caption Head into the existing 3DVG network with a Caption Text Prompt as a connection, effectively harnessing the existing 3DVG model's inherent localization capacity, thereby boosting 3DDC capability. This integration facilitates simultaneous multi-task training on both tasks, mutually enhancing their performance. Extensive experimental results demonstrate the effectiveness of this approach. Specifically, on the ScanRefer dataset, 3DGCTR surpasses the state-of-the-art 3DDC method by 4.3% in CIDEr@0.5IoU in MLE training and improves upon the SOTA 3DVG method by 3.16% in Acc@0.25IoU.
Tactics2D: A Multi-agent Reinforcement Learning Environment for Driving Decision-making
Nov 18, 2023Tactics2D is an open-source multi-agent reinforcement learning library with a Python backend. Its goal is to provide a convenient toolset for researchers to develop decision-making algorithms for autonomous driving. The library includes diverse traffic scenarios implemented as gym-based environments equipped with multi-sensory capabilities and violation detection for traffic rules. Additionally, it features a reinforcement learning baseline tested with reasonable evaluation metrics. Tactics2D is highly modular and customizable. The source code of Tactics2D is available at https://github.com/WoodOxen/Tactics2D.
Interpretable Reinforcement Learning for Robotics and Continuous Control
Nov 16, 2023



Interpretability in machine learning is critical for the safe deployment of learned policies across legally-regulated and safety-critical domains. While gradient-based approaches in reinforcement learning have achieved tremendous success in learning policies for continuous control problems such as robotics and autonomous driving, the lack of interpretability is a fundamental barrier to adoption. We propose Interpretable Continuous Control Trees (ICCTs), a tree-based model that can be optimized via modern, gradient-based, reinforcement learning approaches to produce high-performing, interpretable policies. The key to our approach is a procedure for allowing direct optimization in a sparse decision-tree-like representation. We validate ICCTs against baselines across six domains, showing that ICCTs are capable of learning policies that parity or outperform baselines by up to 33% in autonomous driving scenarios while achieving a 300x-600x reduction in the number of parameters against deep learning baselines. We prove that ICCTs can serve as universal function approximators and display analytically that ICCTs can be verified in linear time. Furthermore, we deploy ICCTs in two realistic driving domains, based on interstate Highway-94 and 280 in the US. Finally, we verify ICCT's utility with end-users and find that ICCTs are rated easier to simulate, quicker to validate, and more interpretable than neural networks.