 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Driving in High-Interaction Traffic Scenarios with Reinforcement Learning
Oct 03, 2024Dynamic and interactive traffic scenarios pose significant challenges for autonomous driving systems. Reinforcement learning (RL) offers a promising approach by enabling the exploration of driving policies beyond the constraints of pre-collected datasets and predefined conditions, particularly in complex environments. However, a critical challenge lies in effectively extracting spatial and temporal features from sequences of high-dimensional, multi-modal observations while minimizing the accumulation of errors over time. Additionally, efficiently guiding large-scale RL models to converge on optimal driving policies without frequent failures during the training process remains tricky. We propose an end-to-end model-based RL algorithm named Ramble to address these issues. Ramble processes multi-view RGB images and LiDAR point clouds into low-dimensional latent features to capture the context of traffic scenarios at each time step. A transformer-based architecture is then employed to model temporal dependencies and predict future states. By learning a dynamics model of the environment, Ramble can foresee upcoming traffic events and make more informed, strategic decisions. Our implementation demonstrates that prior experience in feature extraction and decision-making plays a pivotal role in accelerating the convergence of RL models toward optimal driving policies. Ramble achieves state-of-the-art performance regarding route completion rate and driving score on the CARLA Leaderboard 2.0, showcasing its effectiveness in managing complex and dynamic traffic situations.
HOPE: A Reinforcement Learning-based Hybrid Policy Path Planner for Diverse Parking Scenarios
May 31, 2024
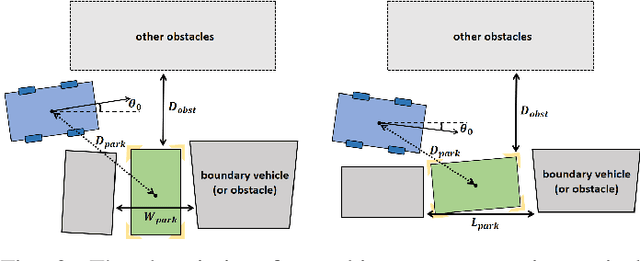


Path planning plays a pivotal role in automated parking, yet current methods struggle to efficiently handle the intricate and diverse parking scenarios. One potential solution is the reinforcement learning-based method, leveraging its exploration in unrecorded situations. However, a key challenge lies in training reinforcement learning methods is the inherent randomness in converging to a feasible policy. This paper introduces a novel solution, the Hybrid POlicy Path plannEr (HOPE), which integrates a reinforcement learning agent with Reeds-Shepp curves, enabling effective planning across diverse scenarios. The paper presents a method to calculate and implement an action mask mechanism in path planning, significantly boosting the efficiency and effectiveness of reinforcement learning training. A transformer is employed as the network structure to fuse environmental information and generate planned paths. To facilitate the training and evaluation of the proposed planner, we propose a criterion for categorizing the difficulty level of parking scenarios based on space and obstacle distribution. Experimental results demonstrate that our approach outperforms typical rule-based algorithms and traditional reinforcement learning methods, showcasing higher planning success rates and generalization across various scenarios. The code for our solution will be openly available on \href{GitHub}{https://github.com/jiamiya/HOPE}. % after the paper's acceptance.
A Survey of Simulators for Autonomous Driving: Taxonomy, Challenges, and Evaluation Metrics
Nov 18, 2023Simulators have irreplaceable importance for the research and development of autonomous driving. Besides saving resources, labor, and time, simulation is the only feasible way to reproduce many severe accident scenarios. Despite their widespread adoption across academia and industry, there is an absence in the evolutionary trajectory of simulators and critical discourse on their limitations. To bridge the gap in research, this paper conducts an in-depth review of simulators for autonomous driving. It delineates the three-decade development into three stages: specialized development period, gap period, and comprehensive development, from which it detects a trend of implementing comprehensive functionalities and open-source accessibility. Then it classifies the simulators by functions, identifying five categories: traffic flow simulator, vehicle dynamics simulator, scenario editor, sensory data generator, and driving strategy validator. Simulators that amalgamate diverse features are defined as comprehensive simulators. By investigating commercial and open-source simulators, this paper reveals that the critical issues faced by simulators primarily revolve around fidelity and efficiency concerns. This paper justifies that enhancing the realism of adverse weather simulation, automated map reconstruction, and interactive traffic participants will bolster credibility. Concurrently, headless simulation and multiple-speed simulation techniques will exploit the theoretic advantages. Moreover, this paper delves into potential solutions for the identified issues. It explores qualitative and quantitative evaluation metrics to assess the simulator's performance. This paper guides users to find suitable simulators efficiently and provides instructive suggestions for developers to improve simulator efficacy purposefully.
Tactics2D: A Multi-agent Reinforcement Learning Environment for Driving Decision-making
Nov 18, 2023Tactics2D is an open-source multi-agent reinforcement learning library with a Python backend. Its goal is to provide a convenient toolset for researchers to develop decision-making algorithms for autonomous driving. The library includes diverse traffic scenarios implemented as gym-based environments equipped with multi-sensory capabilities and violation detection for traffic rules. Additionally, it features a reinforcement learning baseline tested with reasonable evaluation metrics. Tactics2D is highly modular and customizable. The source code of Tactics2D is available at https://github.com/WoodOxen/Tactics2D.
Unifying Discourse Resources with Dependency Framework
Jan 19, 2021

For text-level discourse analysis, there are various discourse schemes but relatively few labeled data, because discourse research is still immature and it is labor-intensive to annotate the inner logic of a text. In this paper, we attempt to unify multiple Chinese discourse corpora under different annotation schemes with discourse dependency framework by designing semi-automatic methods to convert them into dependency structures. We also implement several benchmark dependency parsers and research on how they can leverage the unified data to improve performance.
Learning Where to Look While Tracking Instruments in Robot-assisted Surgery
Jun 29, 2019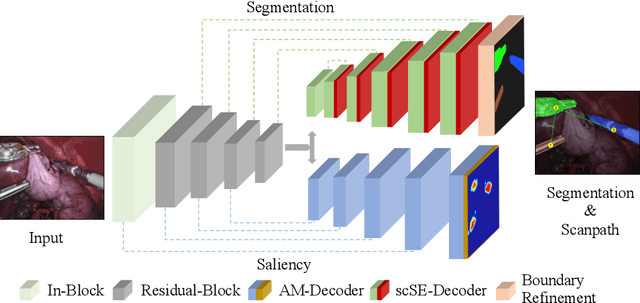
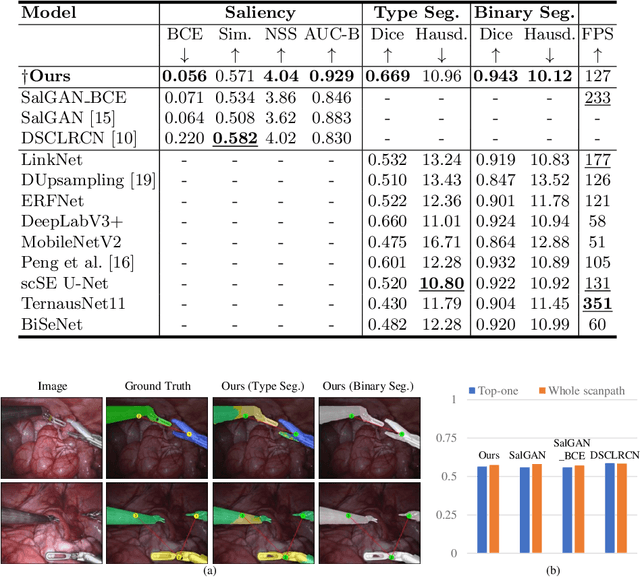
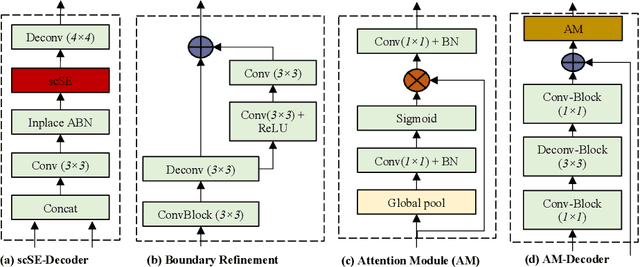
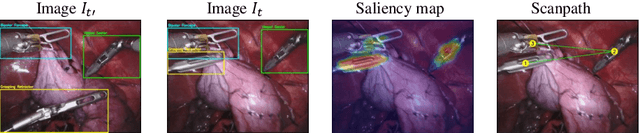
Directing of the task-specific attention while tracking instrument in surgery holds great potential in robot-assisted intervention. For this purpose, we propose an end-to-end trainable multitask learning (MTL) model for real-time surgical instrument segmentation and attention prediction. Our model is designed with a weight-shared encoder and two task-oriented decoders and optimized for the joint tasks. We introduce batch-Wasserstein (bW) loss and construct a soft attention module to refine the distinctive visual region for efficient saliency learning. For multitask optimization, it is always challenging to obtain convergence of both tasks in the same epoch. We deal with this problem by adopting `poly' loss weight and two phases of training. We further propose a novel way to generate task-aware saliency map and scanpath of the instruments on MICCAI robotic instrument segmentation dataset. Compared to the state of the art segmentation and saliency models, our model outperforms most of the evaluation metrics.