 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-based deep kernel learning for parameter estimation in high dimensional PDEs
Sep 17, 2025Inferring parameters of high-dimensional partial differential equations (PDEs) poses significant computational and inferential challenges, primarily due to the curse of dimensionality and the inherent limitations of traditional numerical methods. This paper introduces a novel two-stage Bayesian framework that synergistically integrates training, physics-based deep kernel learning (DKL) with Hamiltonian Monte Carlo (HMC) to robustly infer unknown PDE parameters and quantify their uncertainties from sparse, exact observations. The first stage leverages physics-based DKL to train a surrogate model, which jointly yields an optimized neural network feature extractor and robust initial estimates for the PDE parameters. In the second stage, with the neural network weights fixed, HMC is employed within a full Bayesian framework to efficiently sample the joint posterior distribution of the kernel hyperparameters and the PDE parameters. Numerical experiments on canonical and high-dimensional inverse PDE problems demonstrate that our framework accurately estimates parameters, provides reliable uncertainty estimates, and effectively addresses challenges of data sparsity and model complexity, offering a robust and scalable tool for diverse scientific and engineering applications.
Learning-based 3D Reconstruction in Autonomous Driving: A Comprehensive Survey
Mar 17, 2025Learning-based 3D reconstruction has emerged as a transformative technique in autonomous driving, enabling precise modeling of both dynamic and static environments through advanced neural representations. Despite augmenting perception, 3D reconstruction inspires pioneering solution for vital tasks in the field of autonomous driving, such as scene understanding and closed-loop simulation. Commencing with an examination of input modalities, we investigates the details of 3D reconstruction and conducts a multi-perspective, in-depth analysis of recent advancements. Specifically, we first provide a systematic introduction of preliminaries, including data formats, benchmarks and technical preliminaries of learning-based 3D reconstruction, facilitating instant identification of suitable methods based on hardware configurations and sensor suites. Then, we systematically review learning-based 3D reconstruction methods in autonomous driving, categorizing approaches by subtasks and conducting multi-dimensional analysis and summary to establish a comprehensive technical reference. The development trends and existing challenges is summarized in the context of learning-based 3D reconstruction in autonomous driving. We hope that our review will inspire future researches.
PDE-DKL: PDE-constrained deep kernel learning in high dimensionality
Jan 30, 2025



Many physics-informed machine learning methods for PDE-based problems rely on Gaussian processes (GPs) or neural networks (NNs). However, both face limitations when data are scarce and the dimensionality is high. Although GPs are known for their robust uncertainty quantification in low-dimensional settings, their computational complexity becomes prohibitive as the dimensionality increases. In contrast, while conventional NNs can accommodate high-dimensional input, they often require extensive training data and do not offer uncertainty quantification. To address these challenges, we propose a PDE-constrained Deep Kernel Learning (PDE-DKL) framework that combines DL and GPs under explicit PDE constraints. Specifically, NNs learn a low-dimensional latent representation of the high-dimensional PDE problem, reducing the complexity of the problem. GPs then perform kernel regression subject to the governing PDEs, ensuring accurate solutions and principled uncertainty quantification, even when available data are limited. This synergy unifies the strengths of both NNs and GPs, yielding high accuracy, robust uncertainty estimates, and computational efficiency for high-dimensional PDEs. Numerical experiments demonstrate that PDE-DKL achieves high accuracy with reduced data requirements. They highlight its potential as a practical, reliable, and scalable solver for complex PDE-based applications in science and engineering.
Cross-Modal Visual Relocalization in Prior LiDAR Maps Utilizing Intensity Textures
Dec 02, 2024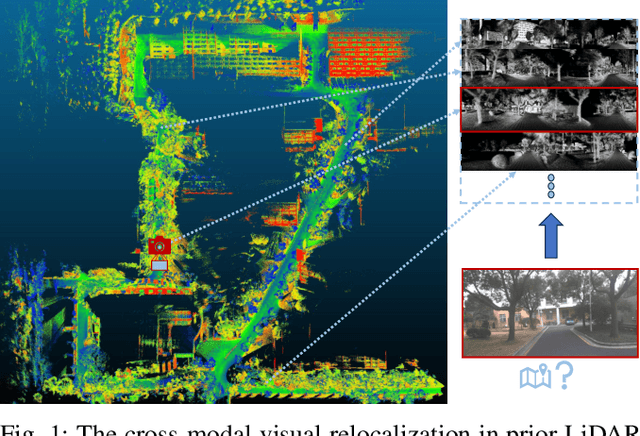


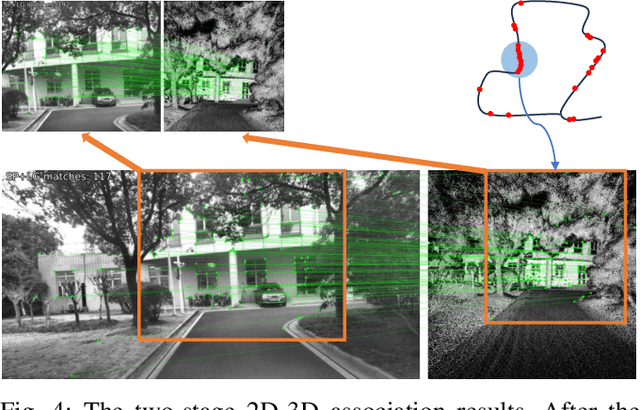
Cross-modal localization has drawn increasing attention in recent years, while the visual relocalization in prior LiDAR maps is less studied. Related methods usually suffer from inconsistency between the 2D texture and 3D geometry, neglecting the intensity features in the LiDAR point cloud. In this paper, we propose a cross-modal visual relocalization system in prior LiDAR maps utilizing intensity textures, which consists of three main modules: map projection, coarse retrieval, and fine relocalization. In the map projection module, we construct the database of intensity channel map images leveraging the dense characteristic of panoramic projection. The coarse retrieval module retrieves the top-K most similar map images to the query image from the database, and retains the top-K' results by covisibility clustering. The fine relocalization module applies a two-stage 2D-3D association and a covisibility inlier selection method to obtain robust correspondences for 6DoF pose estimation. The experimental results on our self-collected datasets demonstrate the effectiveness in both place recognition and pose estimation tasks.
Revisiting Random Weight Perturbation for Efficiently Improving Generalization
Mar 30, 2024



Improving the generalization ability of modern deep neural networks (DNNs) is a fundamental challenge in machine learning. Two branches of methods have been proposed to seek flat minima and improve generalization: one led by sharpness-aware minimization (SAM) minimizes the worst-case neighborhood loss through adversarial weight perturbation (AWP), and the other minimizes the expected Bayes objective with random weight perturbation (RWP). While RWP offers advantages in computation and is closely linked to AWP on a mathematical basis, its empirical performance has consistently lagged behind that of AWP. In this paper, we revisit the use of RWP for improving generalization and propose improvements from two perspectives: i) the trade-off between generalization and convergence and ii) the random perturbation generation. Through extensive experimental evaluations, we demonstrate that our enhanced RWP methods achieve greater efficiency in enhancing generalization, particularly in large-scale problems, while also offering comparable or even superior performance to SAM. The code is released at https://github.com/nblt/mARWP.
A Survey of Simulators for Autonomous Driving: Taxonomy, Challenges, and Evaluation Metrics
Nov 18, 2023Simulators have irreplaceable importance for the research and development of autonomous driving. Besides saving resources, labor, and time, simulation is the only feasible way to reproduce many severe accident scenarios. Despite their widespread adoption across academia and industry, there is an absence in the evolutionary trajectory of simulators and critical discourse on their limitations. To bridge the gap in research, this paper conducts an in-depth review of simulators for autonomous driving. It delineates the three-decade development into three stages: specialized development period, gap period, and comprehensive development, from which it detects a trend of implementing comprehensive functionalities and open-source accessibility. Then it classifies the simulators by functions, identifying five categories: traffic flow simulator, vehicle dynamics simulator, scenario editor, sensory data generator, and driving strategy validator. Simulators that amalgamate diverse features are defined as comprehensive simulators. By investigating commercial and open-source simulators, this paper reveals that the critical issues faced by simulators primarily revolve around fidelity and efficiency concerns. This paper justifies that enhancing the realism of adverse weather simulation, automated map reconstruction, and interactive traffic participants will bolster credibility. Concurrently, headless simulation and multiple-speed simulation techniques will exploit the theoretic advantages. Moreover, this paper delves into potential solutions for the identified issues. It explores qualitative and quantitative evaluation metrics to assess the simulator's performance. This paper guides users to find suitable simulators efficiently and provides instructive suggestions for developers to improve simulator efficacy purposefully.
Efficient Generalization Improvement Guided by Random Weight Perturbation
Nov 21, 2022



To fully uncover the great potential of deep neural networks (DNNs), various learning algorithms have been developed to improve the model's generalization ability. Recently, sharpness-aware minimization (SAM) establishes a generic scheme for generalization improvements by minimizing the sharpness measure within a small neighborhood and achieves state-of-the-art performance. However, SAM requires two consecutive gradient evaluations for solving the min-max problem and inevitably doubles the training time. In this paper, we resort to filter-wise random weight perturbations (RWP) to decouple the nested gradients in SAM. Different from the small adversarial perturbations in SAM, RWP is softer and allows a much larger magnitude of perturbations. Specifically, we jointly optimize the loss function with random perturbations and the original loss function: the former guides the network towards a wider flat region while the latter helps recover the necessary local information. These two loss terms are complementary to each other and mutually independent. Hence, the corresponding gradients can be efficiently computed in parallel, enabling nearly the same training speed as regular training. As a result, we achieve very competitive performance on CIFAR and remarkably better performance on ImageNet (e.g. $\mathbf{ +1.1\%}$) compared with SAM, but always require half of the training time. The code is released at https://github.com/nblt/RWP.
SUNet: Scale-aware Unified Network for Panoptic Segmentation
Sep 07, 2022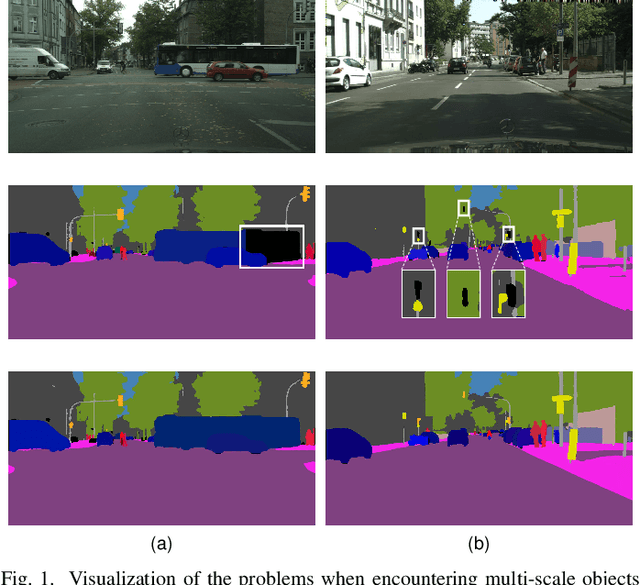
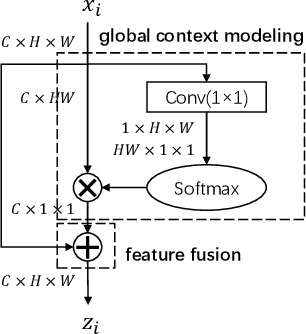
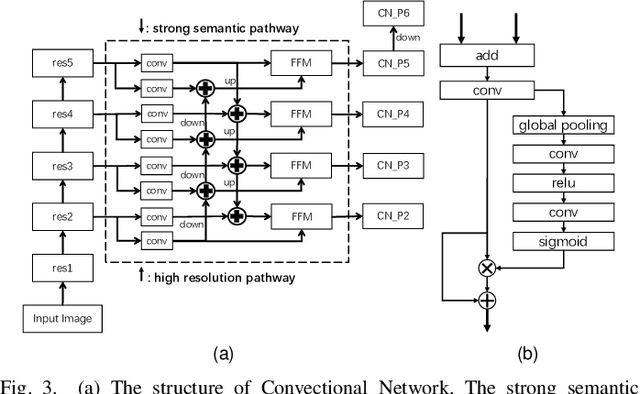
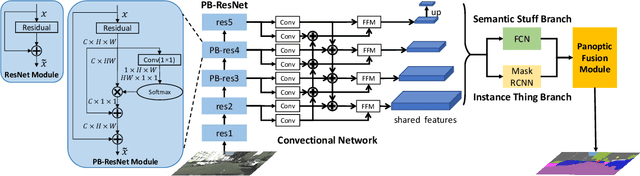
Panoptic segmentation combines the advantages of semantic and instance segmentation, which can provide both pixel-level and instance-level environmental perception information for intelligent vehicles. However, it is challenged with segmenting objects of various scales, especially on extremely large and small ones. In this work, we propose two lightweight modules to mitigate this problem. First, Pixel-relation Block is designed to model global context information for large-scale things, which is based on a query-independent formulation and brings small parameter increments. Then, Convectional Network is constructed to collect extra high-resolution information for small-scale stuff, supplying more appropriate semantic features for the downstream segmentation branches. Based on these two modules, we present an end-to-end Scale-aware Unified Network (SUNet), which is more adaptable to multi-scale objects. Extensive experiments on Cityscapes and COCO demonstrate the effectiveness of the proposed methods.
Threshold-adaptive Unsupervised Focal Loss for Domain Adaptation of Semantic Segmentation
Aug 23, 2022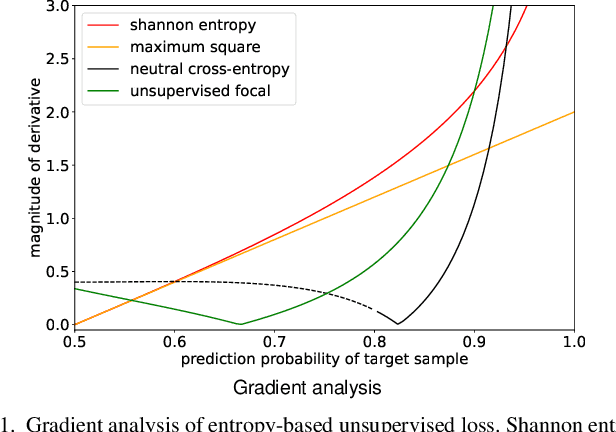
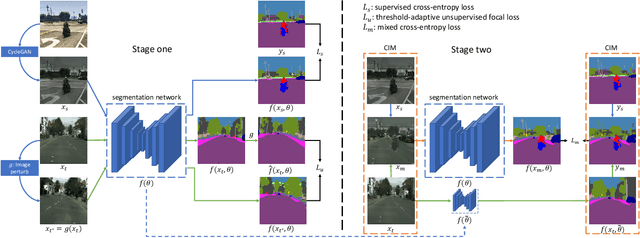
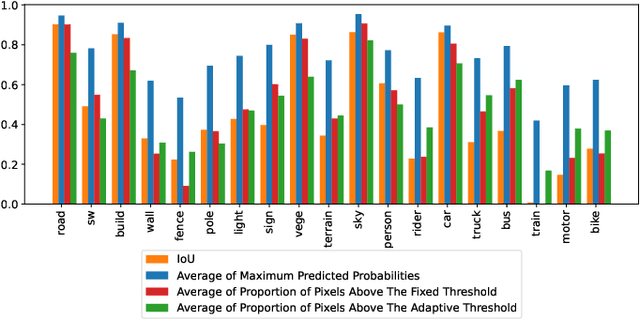

Semantic segmentation is an important task for intelligent vehicles to understand the environment. Current deep learning methods require large amounts of labeled data for training. Manual annotation is expensive, while simulators can provide accurate annotations. However, the performance of the semantic segmentation model trained with the data of the simulator will significantly decrease when applied in the actual scene. Unsupervised domain adaptation (UDA) for semantic segmentation has recently gained increasing research attention, aiming to reduce the domain gap and improve the performance on the target domain. In this paper, we propose a novel two-stage entropy-based UDA method for semantic segmentation. In stage one, we design a threshold-adaptative unsupervised focal loss to regularize the prediction in the target domain, which has a mild gradient neutralization mechanism and mitigates the problem that hard samples are barely optimized in entropy-based methods. In stage two, we introduce a data augmentation method named cross-domain image mixing (CIM) to bridge the semantic knowledge from two domains. Our method achieves state-of-the-art 58.4% and 59.6% mIoUs on SYNTHIA-to-Cityscapes and GTA5-to-Cityscapes using DeepLabV2 and competitive performance using the lightweight BiSeNet.