 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn adjoint method for training data-driven reduced-order models
Jan 12, 2026Reduced-order modeling lies at the interface of numerical analysis and data-driven scientific computing, providing principled ways to compress high-fidelity simulations in science and engineering. We propose a training framework that couples a continuous-time form of operator inference with the adjoint-state method to obtain robust data-driven reduced-order models. This method minimizes a trajectory-based loss between reduced-order solutions and projected snapshot data, which removes the need to estimate time derivatives from noisy measurements and provides intrinsic temporal regularization through time integration. We derive the corresponding continuous adjoint equations to compute gradients efficiently and implement a gradient based optimizer to update the reduced model parameters. Each iteration only requires one forward reduced order solve and one adjoint solve, followed by inexpensive gradient assembly, making the method attractive for large-scale simulations. We validate the proposed method on three partial differential equations: viscous Burgers' equation, the two-dimensional Fisher-KPP equation, and an advection-diffusion equation. We perform systematic comparisons against standard operator inference under two perturbation regimes, namely reduced temporal snapshot density and additive Gaussian noise. For clean data, both approaches deliver similar accuracy, but in situations with sparse sampling and noise, the proposed adjoint-based training provides better accuracy and enhanced roll-out stability.
Active learning for data-driven reduced models of parametric differential systems with Bayesian operator inference
Dec 30, 2025This work develops an active learning framework to intelligently enrich data-driven reduced-order models (ROMs) of parametric dynamical systems, which can serve as the foundation of virtual assets in a digital twin. Data-driven ROMs are explainable, computationally efficient scientific machine learning models that aim to preserve the underlying physics of complex dynamical simulations. Since the quality of data-driven ROMs is sensitive to the quality of the limited training data, we seek to identify training parameters for which using the associated training data results in the best possible parametric ROM. Our approach uses the operator inference methodology, a regression-based strategy which can be tailored to particular parametric structure for a large class of problems. We establish a probabilistic version of parametric operator inference, casting the learning problem as a Bayesian linear regression. Prediction uncertainties stemming from the resulting probabilistic ROM solutions are used to design a sequential adaptive sampling scheme to select new training parameter vectors that promote ROM stability and accuracy globally in the parameter domain. We conduct numerical experiments for several nonlinear parametric systems of partial differential equations and compare the results to ROMs trained on random parameter samples. The results demonstrate that the proposed adaptive sampling strategy consistently yields more stable and accurate ROMs than random sampling does under the same computational budget.
Physics-based deep kernel learning for parameter estimation in high dimensional PDEs
Sep 17, 2025Inferring parameters of high-dimensional partial differential equations (PDEs) poses significant computational and inferential challenges, primarily due to the curse of dimensionality and the inherent limitations of traditional numerical methods. This paper introduces a novel two-stage Bayesian framework that synergistically integrates training, physics-based deep kernel learning (DKL) with Hamiltonian Monte Carlo (HMC) to robustly infer unknown PDE parameters and quantify their uncertainties from sparse, exact observations. The first stage leverages physics-based DKL to train a surrogate model, which jointly yields an optimized neural network feature extractor and robust initial estimates for the PDE parameters. In the second stage, with the neural network weights fixed, HMC is employed within a full Bayesian framework to efficiently sample the joint posterior distribution of the kernel hyperparameters and the PDE parameters. Numerical experiments on canonical and high-dimensional inverse PDE problems demonstrate that our framework accurately estimates parameters, provides reliable uncertainty estimates, and effectively addresses challenges of data sparsity and model complexity, offering a robust and scalable tool for diverse scientific and engineering applications.
PDE-DKL: PDE-constrained deep kernel learning in high dimensionality
Jan 30, 2025



Many physics-informed machine learning methods for PDE-based problems rely on Gaussian processes (GPs) or neural networks (NNs). However, both face limitations when data are scarce and the dimensionality is high. Although GPs are known for their robust uncertainty quantification in low-dimensional settings, their computational complexity becomes prohibitive as the dimensionality increases. In contrast, while conventional NNs can accommodate high-dimensional input, they often require extensive training data and do not offer uncertainty quantification. To address these challenges, we propose a PDE-constrained Deep Kernel Learning (PDE-DKL) framework that combines DL and GPs under explicit PDE constraints. Specifically, NNs learn a low-dimensional latent representation of the high-dimensional PDE problem, reducing the complexity of the problem. GPs then perform kernel regression subject to the governing PDEs, ensuring accurate solutions and principled uncertainty quantification, even when available data are limited. This synergy unifies the strengths of both NNs and GPs, yielding high accuracy, robust uncertainty estimates, and computational efficiency for high-dimensional PDEs. Numerical experiments demonstrate that PDE-DKL achieves high accuracy with reduced data requirements. They highlight its potential as a practical, reliable, and scalable solver for complex PDE-based applications in science and engineering.
HypeRL: Parameter-Informed Reinforcement Learning for Parametric PDEs
Jan 08, 2025



In this work, we devise a new, general-purpose reinforcement learning strategy for the optimal control of parametric partial differential equations (PDEs). Such problems frequently arise in applied sciences and engineering and entail a significant complexity when control and/or state variables are distributed in high-dimensional space or depend on varying parameters. Traditional numerical methods, relying on either iterative minimization algorithms or dynamic programming, while reliable, often become computationally infeasible. Indeed, in either way, the optimal control problem must be solved for each instance of the parameters, and this is out of reach when dealing with high-dimensional time-dependent and parametric PDEs. In this paper, we propose HypeRL, a deep reinforcement learning (DRL) framework to overcome the limitations shown by traditional methods. HypeRL aims at approximating the optimal control policy directly. Specifically, we employ an actor-critic DRL approach to learn an optimal feedback control strategy that can generalize across the range of variation of the parameters. To effectively learn such optimal control laws, encoding the parameter information into the DRL policy and value function neural networks (NNs) is essential. To do so, HypeRL uses two additional NNs, often called hypernetworks, to learn the weights and biases of the value function and the policy NNs. We validate the proposed approach on two PDE-constrained optimal control benchmarks, namely a 1D Kuramoto-Sivashinsky equation and a 2D Navier-Stokes equations, by showing that the knowledge of the PDE parameters and how this information is encoded, i.e., via a hypernetwork, is an essential ingredient for learning parameter-dependent control policies that can generalize effectively to unseen scenarios and for improving the sample efficiency of such policies.
Sparsifying dimensionality reduction of PDE solution data with Bregman learning
Jun 18, 2024Classical model reduction techniques project the governing equations onto a linear subspace of the original state space. More recent data-driven techniques use neural networks to enable nonlinear projections. Whilst those often enable stronger compression, they may have redundant parameters and lead to suboptimal latent dimensionality. To overcome these, we propose a multistep algorithm that induces sparsity in the encoder-decoder networks for effective reduction in the number of parameters and additional compression of the latent space. This algorithm starts with sparsely initialized a network and training it using linearized Bregman iterations. These iterations have been very successful in computer vision and compressed sensing tasks, but have not yet been used for reduced-order modelling. After the training, we further compress the latent space dimensionality by using a form of proper orthogonal decomposition. Last, we use a bias propagation technique to change the induced sparsity into an effective reduction of parameters. We apply this algorithm to three representative PDE models: 1D diffusion, 1D advection, and 2D reaction-diffusion. Compared to conventional training methods like Adam, the proposed method achieves similar accuracy with 30% less parameters and a significantly smaller latent space.
Recurrent Deep Kernel Learning of Dynamical Systems
May 30, 2024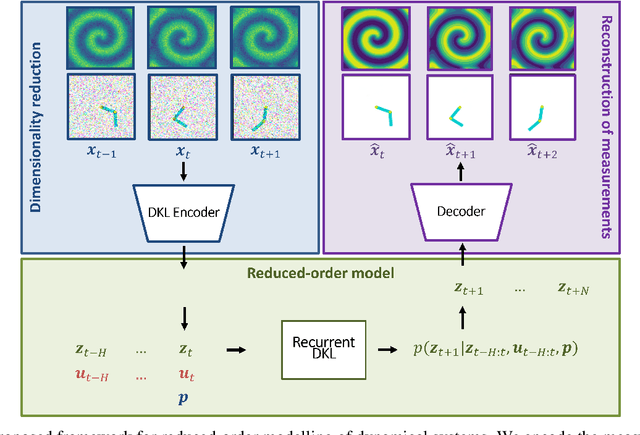
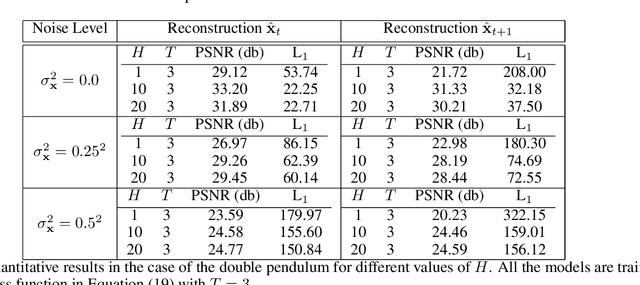
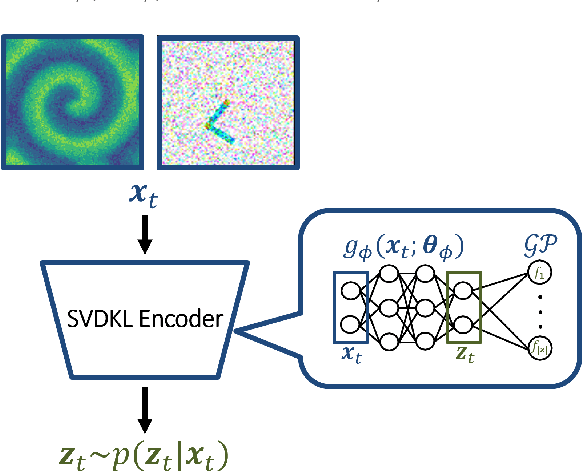
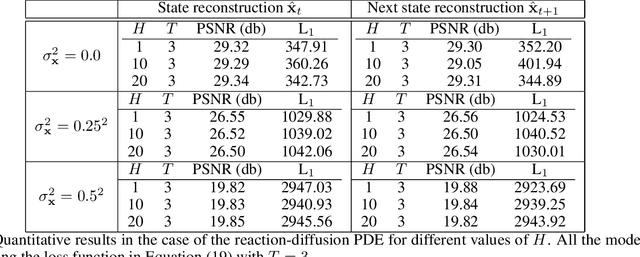
Digital twins require computationally-efficient reduced-order models (ROMs) that can accurately describe complex dynamics of physical assets. However, constructing ROMs from noisy high-dimensional data is challenging. In this work, we propose a data-driven, non-intrusive method that utilizes stochastic variational deep kernel learning (SVDKL) to discover low-dimensional latent spaces from data and a recurrent version of SVDKL for representing and predicting the evolution of latent dynamics. The proposed method is demonstrated with two challenging examples -- a double pendulum and a reaction-diffusion system. Results show that our framework is capable of (i) denoising and reconstructing measurements, (ii) learning compact representations of system states, (iii) predicting system evolution in low-dimensional latent spaces, and (iv) quantifying modeling uncertainties.
Gaussian process learning of nonlinear dynamics
Dec 19, 2023One of the pivotal tasks in scientific machine learning is to represent underlying dynamical systems from time series data. Many methods for such dynamics learning explicitly require the derivatives of state data, which are not directly available and can be approximated conventionally by finite differences. However, the discrete approximations of time derivatives may result in a poor estimation when state data are scarce and/or corrupted by noise, thus compromising the predictiveness of the learned dynamical models. To overcome this technical hurdle, we propose a new method that learns nonlinear dynamics through a Bayesian inference of characterizing model parameters. This method leverages a Gaussian process representation of states, and constructs a likelihood function using the correlation between state data and their derivatives, yet prevents explicit evaluations of time derivatives. Through a Bayesian scheme, a probabilistic estimate of the model parameters is given by the posterior distribution, and thus a quantification is facilitated for uncertainties from noisy state data and the learning process. Specifically, we will discuss the applicability of the proposed method to two typical scenarios for dynamical systems: parameter identification and estimation with an affine structure of the system, and nonlinear parametric approximation without prior knowledge.
Multi-fidelity reduced-order surrogate modeling
Sep 01, 2023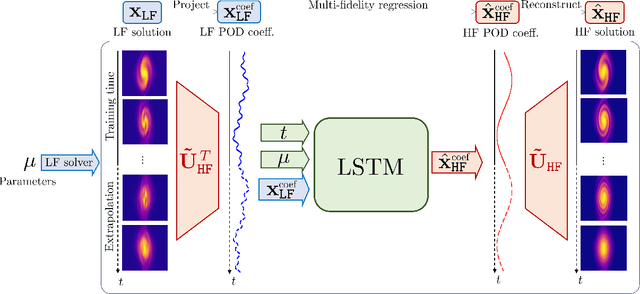

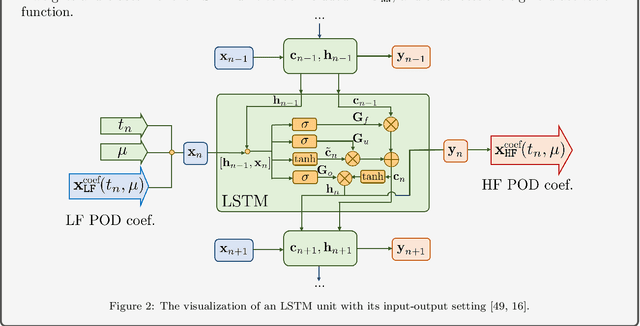

High-fidelity numerical simulations of partial differential equations (PDEs) given a restricted computational budget can significantly limit the number of parameter configurations considered and/or time window evaluated for modeling a given system. Multi-fidelity surrogate modeling aims to leverage less accurate, lower-fidelity models that are computationally inexpensive in order to enhance predictive accuracy when high-fidelity data are limited or scarce. However, low-fidelity models, while often displaying important qualitative spatio-temporal features, fail to accurately capture the onset of instability and critical transients observed in the high-fidelity models, making them impractical as surrogate models. To address this shortcoming, we present a new data-driven strategy that combines dimensionality reduction with multi-fidelity neural network surrogates. The key idea is to generate a spatial basis by applying the classical proper orthogonal decomposition (POD) to high-fidelity solution snapshots, and approximate the dynamics of the reduced states - time-parameter-dependent expansion coefficients of the POD basis - using a multi-fidelity long-short term memory (LSTM) network. By mapping low-fidelity reduced states to their high-fidelity counterpart, the proposed reduced-order surrogate model enables the efficient recovery of full solution fields over time and parameter variations in a non-intrusive manner. The generality and robustness of this method is demonstrated by a collection of parametrized, time-dependent PDE problems where the low-fidelity model can be defined by coarser meshes and/or time stepping, as well as by misspecified physical features. Importantly, the onset of instabilities and transients are well captured by this surrogate modeling technique.
Bayesian approach to Gaussian process regression with uncertain inputs
May 19, 2023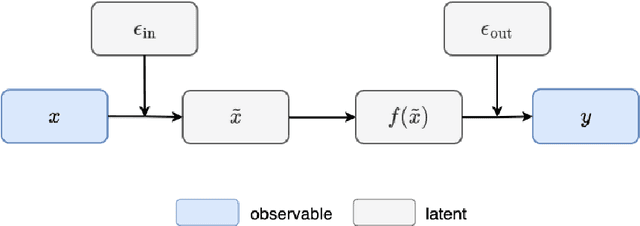
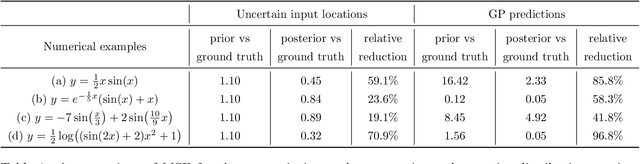
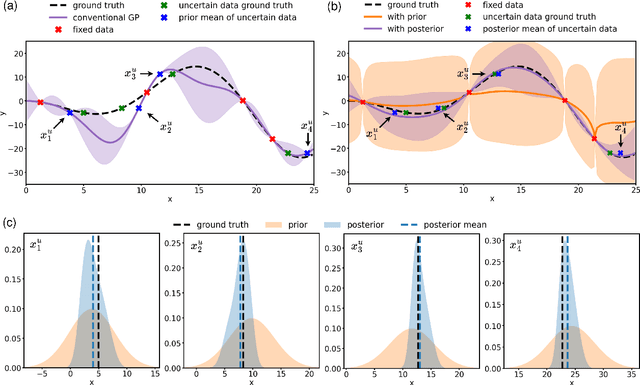
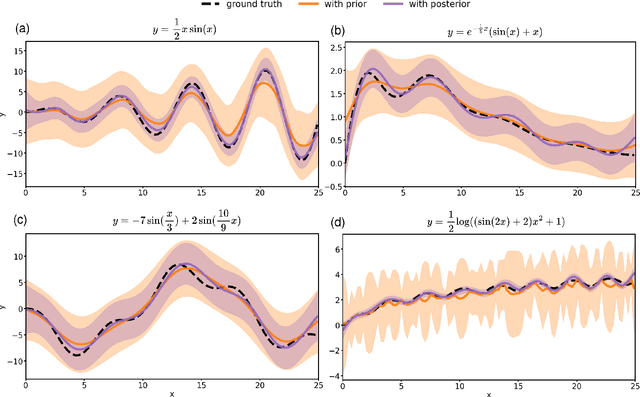
Conventional Gaussian process regression exclusively assumes the existence of noise in the output data of model observations. In many scientific and engineering applications, however, the input locations of observational data may also be compromised with uncertainties owing to modeling assumptions, measurement errors, etc. In this work, we propose a Bayesian method that integrates the variability of input data into Gaussian process regression. Considering two types of observables -- noise-corrupted outputs with fixed inputs and those with prior-distribution-defined uncertain inputs, a posterior distribution is estimated via a Bayesian framework to infer the uncertain data locations. Thereafter, such quantified uncertainties of inputs are incorporated into Gaussian process predictions by means of marginalization. The effectiveness of this new regression technique is demonstrated through several numerical examples, in which a consistently good performance of generalization is observed, while a substantial reduction in the predictive uncertainties is achieved by the Bayesian inference of uncertain inputs.