 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel three-step approach to forecast firm-specific technology convergence opportunity via multi-dimensional feature fusion
Apr 01, 2026As a crucial innovation paradigm, technology convergence (TC) is gaining ever-increasing attention. Yet, existing studies primarily focus on predicting TC at the industry level, with little attention paid to TC forecast for firm-specific technology opportunity discovery (TOD). Moreover, although technological documents like patents contain a rich body of bibliometric, network structure, and textual features, such features are underexploited in the extant TC predictions; most of the relevant studies only used one or two dimensions of these features, and all the three dimensional features have rarely been fused. Here we propose a novel approach that fuses multi-dimensional features from patents to predict TC for firm-specific TOD. Our method comprises three steps, which are elaborated as follows. First, bibliometric, network structure, and textual features are extracted from patent documents, and then fused at the International Patent Classification (IPC)-pair level using attention mechanisms. Second, IPC-level TC opportunities are identified using a two-stage ensemble learning model that incorporates various imbalance-handling strategies. Third, to acquire feasible firm-specific TC opportunities, the performance metrics of topic-level TC opportunities, which are refined from IPC-level opportunities, are evaluated via retrieval-augmented generation (RAG) with a large language model (LLM). We prove the effectiveness of our proposed approach by predicting TC opportunities for a leading Chinese auto part manufacturer, Zhejiang Sanhua Intelligent Controls co., ltd, in the domains of thermal management for energy storage and robotics. In sum, this work advances the theory and applicability of forecasting firm-specific TC opportunity through fusing multi-dimensional features and leveraging LLM-as-a-judge for technology opportunity evaluation.
Compensation-free Machine Unlearning in Text-to-Image Diffusion Models by Eliminating the Mutual Information
Mar 01, 2026The powerful generative capabilities of diffusion models have raised growing privacy and safety concerns regarding generating sensitive or undesired content. In response, machine unlearning (MU) -- commonly referred to as concept erasure (CE) in diffusion models -- has been introduced to remove specific knowledge from model parameters meanwhile preserving innocent knowledge. Despite recent advancements, existing unlearning methods often suffer from excessive and indiscriminate removal, which leads to substantial degradation in the quality of innocent generations. To preserve model utility, prior works rely on compensation, i.e., re-assimilating a subset of the remaining data or explicitly constraining the divergence from the pre-trained model on remaining concepts. However, we reveal that generations beyond the compensation scope still suffer, suggesting such post-remedial compensations are inherently insufficient for preserving the general utility of large-scale generative models. Therefore, in this paper, we advocate for developing compensation-free concept erasure operations, which precisely identify and eliminate the undesired knowledge such that the impact on other generations is minimal. In technique, we propose to MiM-MU, which is to unlearn a concept by minimizing the mutual information with a delicate design for computational effectiveness and for maintaining sampling distribution for other concepts. Extensive evaluations demonstrate that our proposed method achieves effective concept removal meanwhile maintaining high-quality generations for other concepts, and remarkably, without relying on any post-remedial compensation for the first time.
Compute Only Once: UG-Separation for Efficient Large Recommendation Models
Feb 11, 2026Driven by scaling laws, recommender systems increasingly rely on large-scale models to capture complex feature interactions and user behaviors, but this trend also leads to prohibitive training and inference costs. While long-sequence models(e.g., LONGER) can reuse user-side computation through KV caching, such reuse is difficult in dense feature interaction architectures(e.g., RankMixer), where user and group (candidate item) features are deeply entangled across layers. In this work, we propose User-Group Separation (UG-Sep), a novel framework that enables reusable user-side computation in dense interaction models for the first time. UG-Sep introduces a masking mechanism that explicitly disentangles user-side and item-side information flows within token-mixing layers, ensuring that a subset of tokens to preserve purely user-side representations across layers. This design enables corresponding token computations to be reused across multiple samples, significantly reducing redundant inference cost. To compensate for potential expressiveness loss induced by masking, we further propose an Information Compensation strategy that adaptively reconstructs suppressed user-item interactions. Moreover, as UG-Sep substantially reduces user-side FLOPs and exposes memory-bound components, we incorporate W8A16 (8-bit weight, 16-bit activation) weight-only quantization to alleviate memory bandwidth bottlenecks and achieve additional acceleration. We conduct extensive offline evaluations and large-scale online A/B experiments at ByteDance, demonstrating that UG-Sep reduces inference latency by up to 20 percent without degrading online user experience or commercial metrics across multiple business scenarios, including feed recommendation and advertising systems.
Pursuing Feature Separation based on Neural Collapse for Out-of-Distribution Detection
May 28, 2024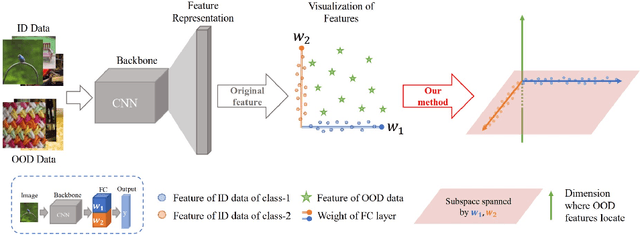



In the open world, detecting out-of-distribution (OOD) data, whose labels are disjoint with those of in-distribution (ID) samples, is important for reliable deep neural networks (DNNs). To achieve better detection performance, one type of approach proposes to fine-tune the model with auxiliary OOD datasets to amplify the difference between ID and OOD data through a separation loss defined on model outputs. However, none of these studies consider enlarging the feature disparity, which should be more effective compared to outputs. The main difficulty lies in the diversity of OOD samples, which makes it hard to describe their feature distribution, let alone design losses to separate them from ID features. In this paper, we neatly fence off the problem based on an aggregation property of ID features named Neural Collapse (NC). NC means that the penultimate features of ID samples within a class are nearly identical to the last layer weight of the corresponding class. Based on this property, we propose a simple but effective loss called OrthLoss, which binds the features of OOD data in a subspace orthogonal to the principal subspace of ID features formed by NC. In this way, the features of ID and OOD samples are separated by different dimensions. By optimizing the feature separation loss rather than purely enlarging output differences, our detection achieves SOTA performance on CIFAR benchmarks without any additional data augmentation or sampling, demonstrating the importance of feature separation in OOD detection. The code will be published.
Revisiting Random Weight Perturbation for Efficiently Improving Generalization
Mar 30, 2024



Improving the generalization ability of modern deep neural networks (DNNs) is a fundamental challenge in machine learning. Two branches of methods have been proposed to seek flat minima and improve generalization: one led by sharpness-aware minimization (SAM) minimizes the worst-case neighborhood loss through adversarial weight perturbation (AWP), and the other minimizes the expected Bayes objective with random weight perturbation (RWP). While RWP offers advantages in computation and is closely linked to AWP on a mathematical basis, its empirical performance has consistently lagged behind that of AWP. In this paper, we revisit the use of RWP for improving generalization and propose improvements from two perspectives: i) the trade-off between generalization and convergence and ii) the random perturbation generation. Through extensive experimental evaluations, we demonstrate that our enhanced RWP methods achieve greater efficiency in enhancing generalization, particularly in large-scale problems, while also offering comparable or even superior performance to SAM. The code is released at https://github.com/nblt/mARWP.
Online Continual Learning via Logit Adjusted Softmax
Nov 11, 2023Online continual learning is a challenging problem where models must learn from a non-stationary data stream while avoiding catastrophic forgetting. Inter-class imbalance during training has been identified as a major cause of forgetting, leading to model prediction bias towards recently learned classes. In this paper, we theoretically analyze that inter-class imbalance is entirely attributed to imbalanced class-priors, and the function learned from intra-class intrinsic distributions is the Bayes-optimal classifier. To that end, we present that a simple adjustment of model logits during training can effectively resist prior class bias and pursue the corresponding Bayes-optimum. Our proposed method, Logit Adjusted Softmax, can mitigate the impact of inter-class imbalance not only in class-incremental but also in realistic general setups, with little additional computational cost. We evaluate our approach on various benchmarks and demonstrate significant performance improvements compared to prior arts. For example, our approach improves the best baseline by 4.6% on CIFAR10.
Low-Dimensional Gradient Helps Out-of-Distribution Detection
Oct 26, 2023



Detecting out-of-distribution (OOD) samples is essential for ensuring the reliability of deep neural networks (DNNs) in real-world scenarios. While previous research has predominantly investigated the disparity between in-distribution (ID) and OOD data through forward information analysis, the discrepancy in parameter gradients during the backward process of DNNs has received insufficient attention. Existing studies on gradient disparities mainly focus on the utilization of gradient norms, neglecting the wealth of information embedded in gradient directions. To bridge this gap, in this paper, we conduct a comprehensive investigation into leveraging the entirety of gradient information for OOD detection. The primary challenge arises from the high dimensionality of gradients due to the large number of network parameters. To solve this problem, we propose performing linear dimension reduction on the gradient using a designated subspace that comprises principal components. This innovative technique enables us to obtain a low-dimensional representation of the gradient with minimal information loss. Subsequently, by integrating the reduced gradient with various existing detection score functions, our approach demonstrates superior performance across a wide range of detection tasks. For instance, on the ImageNet benchmark, our method achieves an average reduction of 11.15% in the false positive rate at 95% recall (FPR95) compared to the current state-of-the-art approach. The code would be released.
Efficient Generalization Improvement Guided by Random Weight Perturbation
Nov 21, 2022



To fully uncover the great potential of deep neural networks (DNNs), various learning algorithms have been developed to improve the model's generalization ability. Recently, sharpness-aware minimization (SAM) establishes a generic scheme for generalization improvements by minimizing the sharpness measure within a small neighborhood and achieves state-of-the-art performance. However, SAM requires two consecutive gradient evaluations for solving the min-max problem and inevitably doubles the training time. In this paper, we resort to filter-wise random weight perturbations (RWP) to decouple the nested gradients in SAM. Different from the small adversarial perturbations in SAM, RWP is softer and allows a much larger magnitude of perturbations. Specifically, we jointly optimize the loss function with random perturbations and the original loss function: the former guides the network towards a wider flat region while the latter helps recover the necessary local information. These two loss terms are complementary to each other and mutually independent. Hence, the corresponding gradients can be efficiently computed in parallel, enabling nearly the same training speed as regular training. As a result, we achieve very competitive performance on CIFAR and remarkably better performance on ImageNet (e.g. $\mathbf{ +1.1\%}$) compared with SAM, but always require half of the training time. The code is released at https://github.com/nblt/RWP.
On Multi-head Ensemble of Smoothed Classifiers for Certified Robustness
Nov 20, 2022Randomized Smoothing (RS) is a promising technique for certified robustness, and recently in RS the ensemble of multiple deep neural networks (DNNs) has shown state-of-the-art performances. However, such an ensemble brings heavy computation burdens in both training and certification, and yet under-exploits individual DNNs and their mutual effects, as the communication between these classifiers is commonly ignored in optimization. In this work, starting from a single DNN, we augment the network with multiple heads, each of which pertains a classifier for the ensemble. A novel training strategy, namely Self-PAced Circular-TEaching (SPACTE), is proposed accordingly. SPACTE enables a circular communication flow among those augmented heads, i.e., each head teaches its neighbor with the self-paced learning using smoothed losses, which are specifically designed in relation to certified robustness. The deployed multi-head structure and the circular-teaching scheme of SPACTE jointly contribute to diversify and enhance the classifiers in augmented heads for ensemble, leading to even stronger certified robustness than ensembling multiple DNNs (effectiveness) at the cost of much less computational expenses (efficiency), verified by extensive experiments and discussions.
Unifying Gradients to Improve Real-world Robustness for Deep Networks
Aug 12, 2022

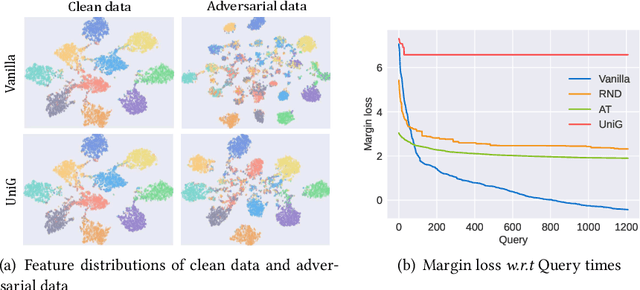

The wide application of deep neural networks (DNNs) demands an increasing amount of attention to their real-world robustness, i.e., whether a DNN resists black-box adversarial attacks, among them score-based query attacks (SQAs) are the most threatening ones because of their practicalities and effectiveness: the attackers only need dozens of queries on model outputs to seriously hurt a victim network. Defending against SQAs requires a slight but artful variation of outputs due to the service purpose for users, who share the same output information with attackers. In this paper, we propose a real-world defense, called Unifying Gradients (UniG), to unify gradients of different data so that attackers could only probe a much weaker attack direction that is similar for different samples. Since such universal attack perturbations have been validated as less aggressive than the input-specific perturbations, UniG protects real-world DNNs by indicating attackers a twisted and less informative attack direction. To enhance UniG's practical significance in real-world applications, we implement it as a Hadamard product module that is computationally-efficient and readily plugged into any model. According to extensive experiments on 5 SQAs and 4 defense baselines, UniG significantly improves real-world robustness without hurting clean accuracy on CIFAR10 and ImageNet. For instance, UniG maintains a CIFAR-10 model of 77.80% accuracy under 2500-query Square attack while the state-of-the-art adversarially-trained model only has 67.34% on CIFAR10. Simultaneously, UniG greatly surpasses all compared baselines in clean accuracy and the modification degree of outputs. The code would be released.