 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Gradients to Improve Real-world Robustness for Deep Networks
Paper and Code


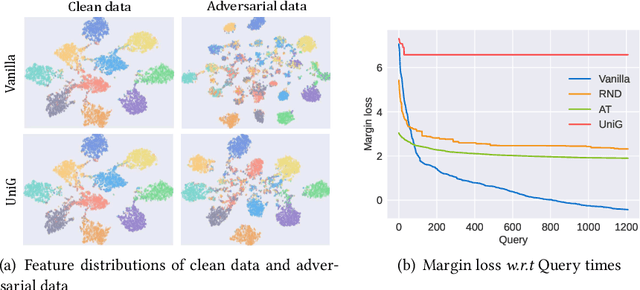

The wide application of deep neural networks (DNNs) demands an increasing amount of attention to their real-world robustness, i.e., whether a DNN resists black-box adversarial attacks, among them score-based query attacks (SQAs) are the most threatening ones because of their practicalities and effectiveness: the attackers only need dozens of queries on model outputs to seriously hurt a victim network. Defending against SQAs requires a slight but artful variation of outputs due to the service purpose for users, who share the same output information with attackers. In this paper, we propose a real-world defense, called Unifying Gradients (UniG), to unify gradients of different data so that attackers could only probe a much weaker attack direction that is similar for different samples. Since such universal attack perturbations have been validated as less aggressive than the input-specific perturbations, UniG protects real-world DNNs by indicating attackers a twisted and less informative attack direction. To enhance UniG's practical significance in real-world applications, we implement it as a Hadamard product module that is computationally-efficient and readily plugged into any model. According to extensive experiments on 5 SQAs and 4 defense baselines, UniG significantly improves real-world robustness without hurting clean accuracy on CIFAR10 and ImageNet. For instance, UniG maintains a CIFAR-10 model of 77.80% accuracy under 2500-query Square attack while the state-of-the-art adversarially-trained model only has 67.34% on CIFAR10. Simultaneously, UniG greatly surpasses all compared baselines in clean accuracy and the modification degree of outputs. The code would be released.