 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Full-Pipeline Framework for Evaluating Membership Inference Attacks in Machine Learning
May 28, 2026While Membership Inference Attacks (MIAs) are the prevailing method for identifying training data, their application has expanded into privacy auditing and machine unlearning. Nevertheless, the field lacks a systematic framework for evaluating how different contexts affect MIA efficacy. Without such a characterization, practitioners risk deploying algorithms that perform well on benchmarks but become statistically irrelevant when faced with the nuances of specific, real-world datasets. To bridge this gap and provide actionable insights, we introduce a comprehensive evaluation framework that systematically characterizes privacy risks across the entire machine learning pipeline, spanning data, architectures, algorithms, and post-training modules. Designed to inherently capture diverse operational contexts, our framework rigorously evaluates state-of-the-art MIAs across a broad spectrum of training configurations. To account for varying misclassification costs in real-world deployments, we employ three complementary metrics: Balanced Accuracy for symmetric costs, alongside TPR at low FPR (or TNR at low FNR) for asymmetric scenarios where false alarms or missed detections are strictly penalized. Furthermore, recognizing that existing MIAs assume divergent adversary capabilities, we formalize two standardized threat models and adapt these attacks into corresponding variants to ensure an equitable benchmark. Extensive empirical evaluations demonstrate that the efficacy of specific MIA methodologies is highly sensitive to the assumed threat models and chosen evaluation metrics. Ultimately, we distill these findings into actionable guidelines and provide a ready-to-use auditing toolkit, empowering practitioners to conduct better privacy assessments.
Compensation-free Machine Unlearning in Text-to-Image Diffusion Models by Eliminating the Mutual Information
Mar 01, 2026The powerful generative capabilities of diffusion models have raised growing privacy and safety concerns regarding generating sensitive or undesired content. In response, machine unlearning (MU) -- commonly referred to as concept erasure (CE) in diffusion models -- has been introduced to remove specific knowledge from model parameters meanwhile preserving innocent knowledge. Despite recent advancements, existing unlearning methods often suffer from excessive and indiscriminate removal, which leads to substantial degradation in the quality of innocent generations. To preserve model utility, prior works rely on compensation, i.e., re-assimilating a subset of the remaining data or explicitly constraining the divergence from the pre-trained model on remaining concepts. However, we reveal that generations beyond the compensation scope still suffer, suggesting such post-remedial compensations are inherently insufficient for preserving the general utility of large-scale generative models. Therefore, in this paper, we advocate for developing compensation-free concept erasure operations, which precisely identify and eliminate the undesired knowledge such that the impact on other generations is minimal. In technique, we propose to MiM-MU, which is to unlearn a concept by minimizing the mutual information with a delicate design for computational effectiveness and for maintaining sampling distribution for other concepts. Extensive evaluations demonstrate that our proposed method achieves effective concept removal meanwhile maintaining high-quality generations for other concepts, and remarkably, without relying on any post-remedial compensation for the first time.
A Unified Gradient-based Framework for Task-agnostic Continual Learning-Unlearning
May 21, 2025Recent advancements in deep models have highlighted the need for intelligent systems that combine continual learning (CL) for knowledge acquisition with machine unlearning (MU) for data removal, forming the Continual Learning-Unlearning (CLU) paradigm. While existing work treats CL and MU as separate processes, we reveal their intrinsic connection through a unified optimization framework based on Kullback-Leibler divergence minimization. This framework decomposes gradient updates for approximate CLU into four components: learning new knowledge, unlearning targeted data, preserving existing knowledge, and modulation via weight saliency. A critical challenge lies in balancing knowledge update and retention during sequential learning-unlearning cycles. To resolve this stability-plasticity dilemma, we introduce a remain-preserved manifold constraint to induce a remaining Hessian compensation for CLU iterations. A fast-slow weight adaptation mechanism is designed to efficiently approximate the second-order optimization direction, combined with adaptive weighting coefficients and a balanced weight saliency mask, proposing a unified implementation framework for gradient-based CLU. Furthermore, we pioneer task-agnostic CLU scenarios that support fine-grained unlearning at the cross-task category and random sample levels beyond the traditional task-aware setups. Experiments demonstrate that the proposed UG-CLU framework effectively coordinates incremental learning, precise unlearning, and knowledge stability across multiple datasets and model architectures, providing a theoretical foundation and methodological support for dynamic, compliant intelligent systems.
Unified Gradient-Based Machine Unlearning with Remain Geometry Enhancement
Sep 29, 2024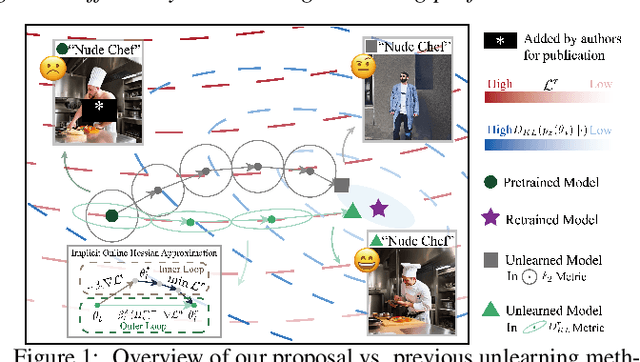



Machine unlearning (MU) has emerged to enhance the privacy and trustworthiness of deep neural networks. Approximate MU is a practical method for large-scale models. Our investigation into approximate MU starts with identifying the steepest descent direction, minimizing the output Kullback-Leibler divergence to exact MU inside a parameters' neighborhood. This probed direction decomposes into three components: weighted forgetting gradient ascent, fine-tuning retaining gradient descent, and a weight saliency matrix. Such decomposition derived from Euclidean metric encompasses most existing gradient-based MU methods. Nevertheless, adhering to Euclidean space may result in sub-optimal iterative trajectories due to the overlooked geometric structure of the output probability space. We suggest embedding the unlearning update into a manifold rendered by the remaining geometry, incorporating second-order Hessian from the remaining data. It helps prevent effective unlearning from interfering with the retained performance. However, computing the second-order Hessian for large-scale models is intractable. To efficiently leverage the benefits of Hessian modulation, we propose a fast-slow parameter update strategy to implicitly approximate the up-to-date salient unlearning direction. Free from specific modal constraints, our approach is adaptable across computer vision unlearning tasks, including classification and generation. Extensive experiments validate our efficacy and efficiency. Notably, our method successfully performs class-forgetting on ImageNet using DiT and forgets a class on CIFAR-10 using DDPM in just 50 steps, compared to thousands of steps required by previous methods.
Pursuing Feature Separation based on Neural Collapse for Out-of-Distribution Detection
May 28, 2024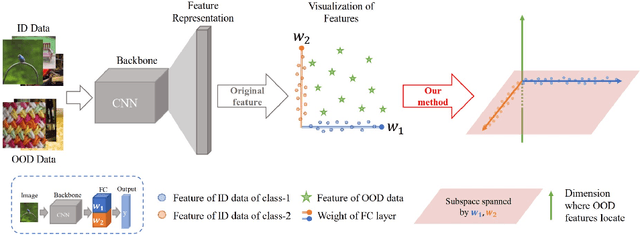



In the open world, detecting out-of-distribution (OOD) data, whose labels are disjoint with those of in-distribution (ID) samples, is important for reliable deep neural networks (DNNs). To achieve better detection performance, one type of approach proposes to fine-tune the model with auxiliary OOD datasets to amplify the difference between ID and OOD data through a separation loss defined on model outputs. However, none of these studies consider enlarging the feature disparity, which should be more effective compared to outputs. The main difficulty lies in the diversity of OOD samples, which makes it hard to describe their feature distribution, let alone design losses to separate them from ID features. In this paper, we neatly fence off the problem based on an aggregation property of ID features named Neural Collapse (NC). NC means that the penultimate features of ID samples within a class are nearly identical to the last layer weight of the corresponding class. Based on this property, we propose a simple but effective loss called OrthLoss, which binds the features of OOD data in a subspace orthogonal to the principal subspace of ID features formed by NC. In this way, the features of ID and OOD samples are separated by different dimensions. By optimizing the feature separation loss rather than purely enlarging output differences, our detection achieves SOTA performance on CIFAR benchmarks without any additional data augmentation or sampling, demonstrating the importance of feature separation in OOD detection. The code will be published.
Towards Natural Machine Unlearning
May 24, 2024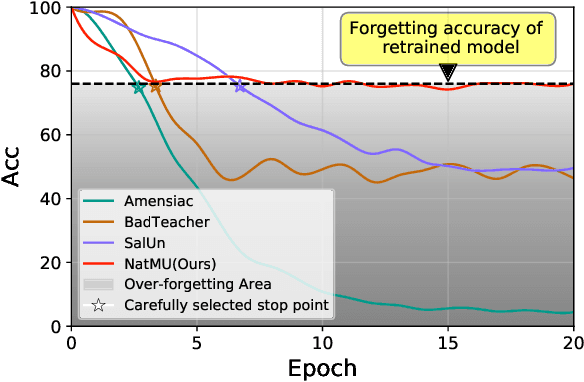
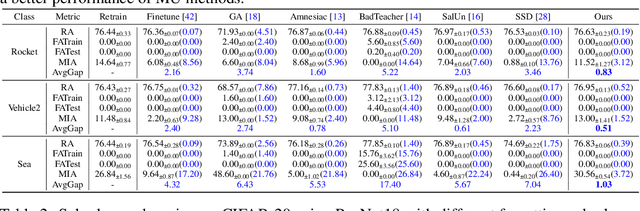
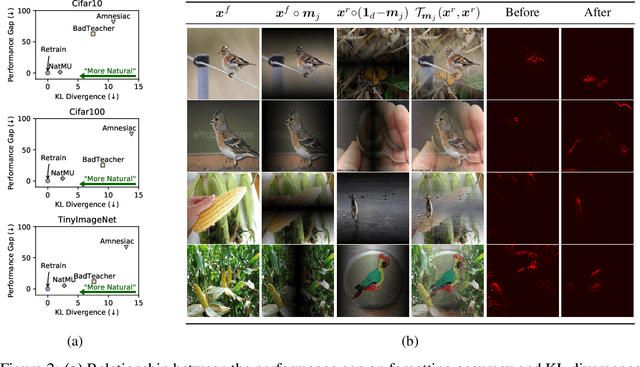

Machine unlearning (MU) aims to eliminate information that has been learned from specific training data, namely forgetting data, from a pre-trained model. Currently, the mainstream of existing MU methods involves modifying the forgetting data with incorrect labels and subsequently fine-tuning the model. While learning such incorrect information can indeed remove knowledge, the process is quite unnatural as the unlearning process undesirably reinforces the incorrect information and leads to over-forgetting. Towards more \textit{natural} machine unlearning, we inject correct information from the remaining data to the forgetting samples when changing their labels. Through pairing these adjusted samples with their labels, the model will tend to use the injected correct information and naturally suppress the information meant to be forgotten. Albeit straightforward, such a first step towards natural machine unlearning can significantly outperform current state-of-the-art approaches. In particular, our method substantially reduces the over-forgetting and leads to strong robustness to hyperparameters, making it a promising candidate for practical machine unlearning.
Friendly Sharpness-Aware Minimization
Mar 19, 2024



Sharpness-Aware Minimization (SAM) has been instrumental in improving deep neural network training by minimizing both training loss and loss sharpness. Despite the practical success, the mechanisms behind SAM's generalization enhancements remain elusive, limiting its progress in deep learning optimization. In this work, we investigate SAM's core components for generalization improvement and introduce "Friendly-SAM" (F-SAM) to further enhance SAM's generalization. Our investigation reveals the key role of batch-specific stochastic gradient noise within the adversarial perturbation, i.e., the current minibatch gradient, which significantly influences SAM's generalization performance. By decomposing the adversarial perturbation in SAM into full gradient and stochastic gradient noise components, we discover that relying solely on the full gradient component degrades generalization while excluding it leads to improved performance. The possible reason lies in the full gradient component's increase in sharpness loss for the entire dataset, creating inconsistencies with the subsequent sharpness minimization step solely on the current minibatch data. Inspired by these insights, F-SAM aims to mitigate the negative effects of the full gradient component. It removes the full gradient estimated by an exponentially moving average (EMA) of historical stochastic gradients, and then leverages stochastic gradient noise for improved generalization. Moreover, we provide theoretical validation for the EMA approximation and prove the convergence of F-SAM on non-convex problems. Extensive experiments demonstrate the superior generalization performance and robustness of F-SAM over vanilla SAM. Code is available at https://github.com/nblt/F-SAM.
Machine Unlearning by Suppressing Sample Contribution
Feb 23, 2024



Machine Unlearning (MU) is to forget data from a well-trained model, which is practically important due to the "right to be forgotten". In this paper, we start from the fundamental distinction between training data and unseen data on their contribution to the model: the training data contributes to the final model while the unseen data does not. We theoretically discover that the input sensitivity can approximately measure the contribution and practically design an algorithm, called MU-Mis (machine unlearning via minimizing input sensitivity), to suppress the contribution of the forgetting data. Experimental results demonstrate that MU-Mis outperforms state-of-the-art MU methods significantly. Additionally, MU-Mis aligns more closely with the application of MU as it does not require the use of remaining data.
Low-Dimensional Gradient Helps Out-of-Distribution Detection
Oct 26, 2023



Detecting out-of-distribution (OOD) samples is essential for ensuring the reliability of deep neural networks (DNNs) in real-world scenarios. While previous research has predominantly investigated the disparity between in-distribution (ID) and OOD data through forward information analysis, the discrepancy in parameter gradients during the backward process of DNNs has received insufficient attention. Existing studies on gradient disparities mainly focus on the utilization of gradient norms, neglecting the wealth of information embedded in gradient directions. To bridge this gap, in this paper, we conduct a comprehensive investigation into leveraging the entirety of gradient information for OOD detection. The primary challenge arises from the high dimensionality of gradients due to the large number of network parameters. To solve this problem, we propose performing linear dimension reduction on the gradient using a designated subspace that comprises principal components. This innovative technique enables us to obtain a low-dimensional representation of the gradient with minimal information loss. Subsequently, by integrating the reduced gradient with various existing detection score functions, our approach demonstrates superior performance across a wide range of detection tasks. For instance, on the ImageNet benchmark, our method achieves an average reduction of 11.15% in the false positive rate at 95% recall (FPR95) compared to the current state-of-the-art approach. The code would be released.
Self-Ensemble Protection: Training Checkpoints Are Good Data Protectors
Nov 22, 2022As data become increasingly vital for deep learning, a company would be very cautious about releasing data, because the competitors could use the released data to train high-performance models, thereby posing a tremendous threat to the company's commercial competence. To prevent training good models on the data, imperceptible perturbations could be added to it. Since such perturbations aim at hurting the entire training process, they should reflect the vulnerability of DNN training, rather than that of a single model. Based on this new idea, we seek adversarial examples that are always unrecognized (never correctly classified) in training. In this paper, we uncover them by modeling checkpoints' gradients, forming the proposed self-ensemble protection (SEP), which is very effective because (1) learning on examples ignored during normal training tends to yield DNNs ignoring normal examples; (2) checkpoints' cross-model gradients are close to orthogonal, meaning that they are as diverse as DNNs with different architectures in conventional ensemble. That is, our amazing performance of ensemble only requires the computation of training one model. By extensive experiments with 9 baselines on 3 datasets and 5 architectures, SEP is verified to be a new state-of-the-art, e.g., our small $\ell_\infty=2/255$ perturbations reduce the accuracy of a CIFAR-10 ResNet18 from 94.56\% to 14.68\%, compared to 41.35\% by the best-known method.Code is available at https://github.com/Sizhe-Chen/SEP.