 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFG-UAP: Feature-Gathering Universal Adversarial Perturbation
Sep 27, 2022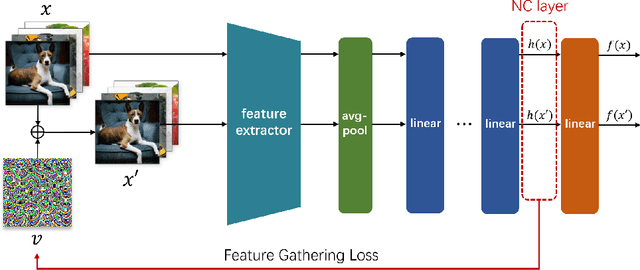
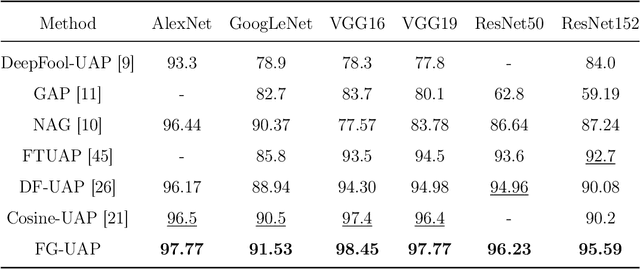

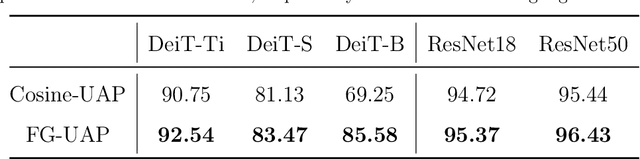
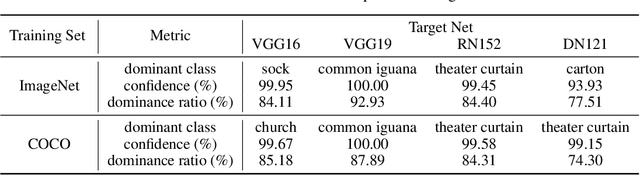
Deep Neural Networks (DNNs) are susceptible to elaborately designed perturbations, whether such perturbations are dependent or independent of images. The latter one, called Universal Adversarial Perturbation (UAP), is very attractive for model robustness analysis, since its independence of input reveals the intrinsic characteristics of the model. Relatively, another interesting observation is Neural Collapse (NC), which means the feature variability may collapse during the terminal phase of training. Motivated by this, we propose to generate UAP by attacking the layer where NC phenomenon happens. Because of NC, the proposed attack could gather all the natural images' features to its surrounding, which is hence called Feature-Gathering UAP (FG-UAP). We evaluate the effectiveness our proposed algorithm on abundant experiments, including untargeted and targeted universal attacks, attacks under limited dataset, and transfer-based black-box attacks among different architectures including Vision Transformers, which are believed to be more robust. Furthermore, we investigate FG-UAP in the view of NC by analyzing the labels and extracted features of adversarial examples, finding that collapse phenomenon becomes stronger after the model is corrupted. The code will be released when the paper is accepted.
Dominant Patterns: Critical Features Hidden in Deep Neural Networks
May 31, 2021


In this paper, we find the existence of critical features hidden in Deep NeuralNetworks (DNNs), which are imperceptible but can actually dominate the outputof DNNs. We call these features dominant patterns. As the name suggests, for a natural image, if we add the dominant pattern of a DNN to it, the output of this DNN is determined by the dominant pattern instead of the original image, i.e., DNN's prediction is the same with the dominant pattern's. We design an algorithm to find such patterns by pursuing the insensitivity in the feature space. A direct application of the dominant patterns is the Universal Adversarial Perturbations(UAPs). Numerical experiments show that the found dominant patterns defeat state-of-the-art UAP methods, especially in label-free settings. In addition, dominant patterns are proved to have the potential to attack downstream tasks in which DNNs share the same backbone. We claim that DNN-specific dominant patterns reveal some essential properties of a DNN and are of great importance for its feature analysis and robustness enhancement.
Going Far Boosts Attack Transferability, but Do Not Do It
Feb 20, 2021
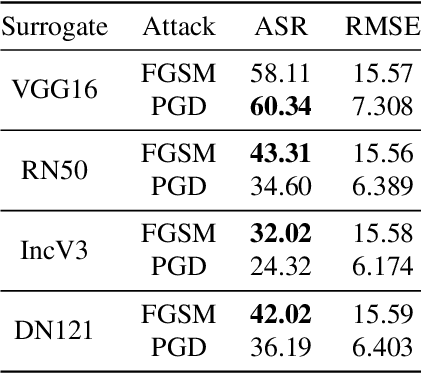
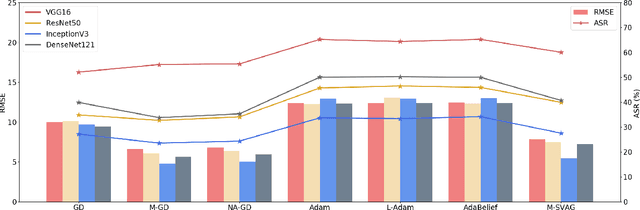
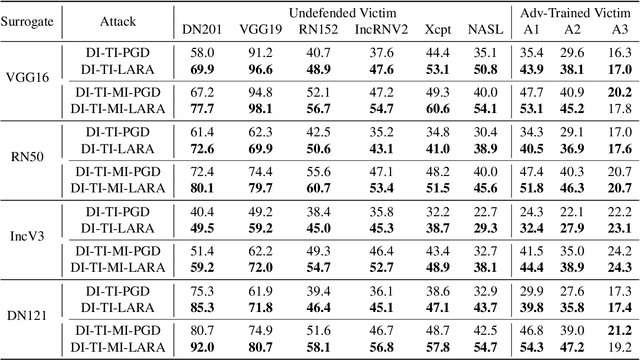
Deep Neural Networks (DNNs) could be easily fooled by Adversarial Examples (AEs) with an imperceptible difference to original ones in human eyes. Also, the AEs from attacking one surrogate DNN tend to cheat other black-box DNNs as well, i.e., the attack transferability. Existing works reveal that adopting certain optimization algorithms in attack improves transferability, but the underlying reasons have not been thoroughly studied. In this paper, we investigate the impacts of optimization on attack transferability by comprehensive experiments concerning 7 optimization algorithms, 4 surrogates, and 9 black-box models. Through the thorough empirical analysis from three perspectives, we surprisingly find that the varied transferability of AEs from optimization algorithms is strongly related to the corresponding Root Mean Square Error (RMSE) from their original samples. On such a basis, one could simply approach high transferability by attacking until RMSE decreases, which motives us to propose a LArge RMSE Attack (LARA). Although LARA significantly improves transferability by 20%, it is insufficient to exploit the vulnerability of DNNs, leading to a natural urge that the strength of all attacks should be measured by both the widely used $\ell_\infty$ bound and the RMSE addressed in this paper, so that tricky enhancement of transferability would be avoided.