 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDominant Patterns: Critical Features Hidden in Deep Neural Networks
Paper and Code
May 31, 2021


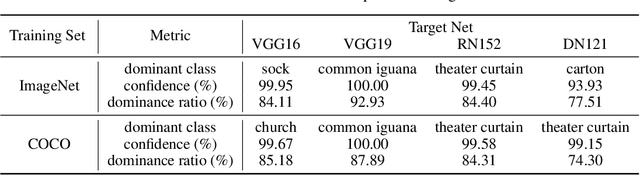
In this paper, we find the existence of critical features hidden in Deep NeuralNetworks (DNNs), which are imperceptible but can actually dominate the outputof DNNs. We call these features dominant patterns. As the name suggests, for a natural image, if we add the dominant pattern of a DNN to it, the output of this DNN is determined by the dominant pattern instead of the original image, i.e., DNN's prediction is the same with the dominant pattern's. We design an algorithm to find such patterns by pursuing the insensitivity in the feature space. A direct application of the dominant patterns is the Universal Adversarial Perturbations(UAPs). Numerical experiments show that the found dominant patterns defeat state-of-the-art UAP methods, especially in label-free settings. In addition, dominant patterns are proved to have the potential to attack downstream tasks in which DNNs share the same backbone. We claim that DNN-specific dominant patterns reveal some essential properties of a DNN and are of great importance for its feature analysis and robustness enhancement.