 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing Far Boosts Attack Transferability, but Do Not Do It
Paper and Code

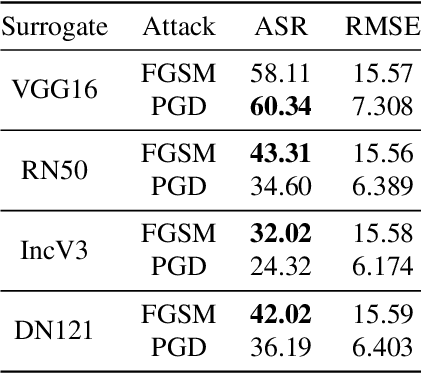
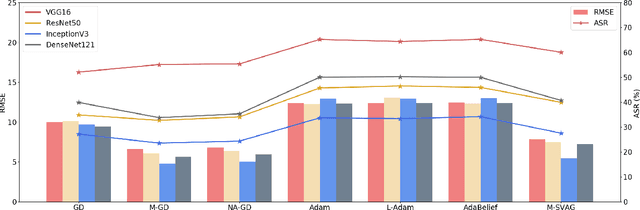
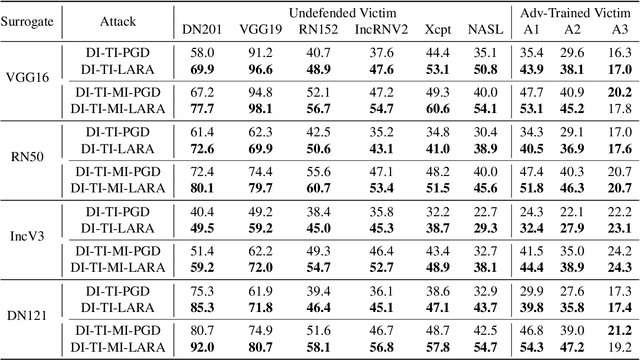
Deep Neural Networks (DNNs) could be easily fooled by Adversarial Examples (AEs) with an imperceptible difference to original ones in human eyes. Also, the AEs from attacking one surrogate DNN tend to cheat other black-box DNNs as well, i.e., the attack transferability. Existing works reveal that adopting certain optimization algorithms in attack improves transferability, but the underlying reasons have not been thoroughly studied. In this paper, we investigate the impacts of optimization on attack transferability by comprehensive experiments concerning 7 optimization algorithms, 4 surrogates, and 9 black-box models. Through the thorough empirical analysis from three perspectives, we surprisingly find that the varied transferability of AEs from optimization algorithms is strongly related to the corresponding Root Mean Square Error (RMSE) from their original samples. On such a basis, one could simply approach high transferability by attacking until RMSE decreases, which motives us to propose a LArge RMSE Attack (LARA). Although LARA significantly improves transferability by 20%, it is insufficient to exploit the vulnerability of DNNs, leading to a natural urge that the strength of all attacks should be measured by both the widely used $\ell_\infty$ bound and the RMSE addressed in this paper, so that tricky enhancement of transferability would be avoided.