 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthy Multi-Task Adversarial Attacks
Nov 26, 2024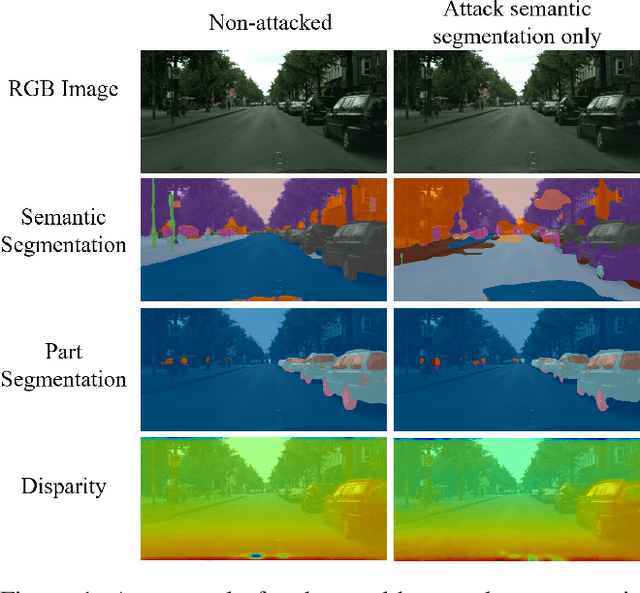
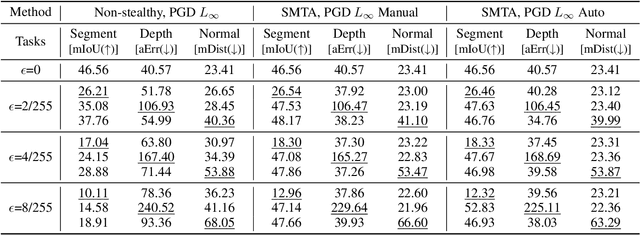
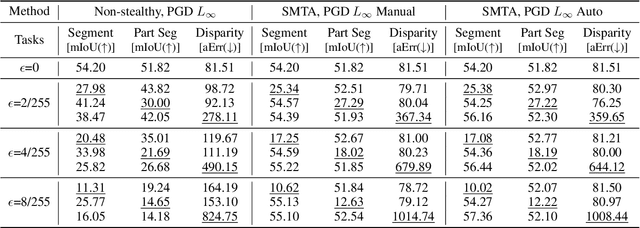
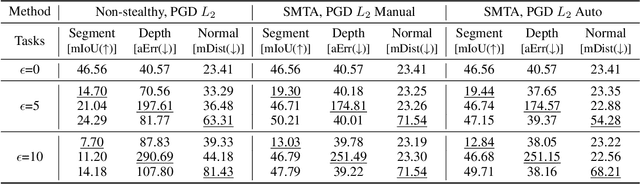
Deep Neural Networks exhibit inherent vulnerabilities to adversarial attacks, which can significantly compromise their outputs and reliability. While existing research primarily focuses on attacking single-task scenarios or indiscriminately targeting all tasks in multi-task environments, we investigate selectively targeting one task while preserving performance in others within a multi-task framework. This approach is motivated by varying security priorities among tasks in real-world applications, such as autonomous driving, where misinterpreting critical objects (e.g., signs, traffic lights) poses a greater security risk than minor depth miscalculations. Consequently, attackers may hope to target security-sensitive tasks while avoiding non-critical tasks from being compromised, thus evading being detected before compromising crucial functions. In this paper, we propose a method for the stealthy multi-task attack framework that utilizes multiple algorithms to inject imperceptible noise into the input. This novel method demonstrates remarkable efficacy in compromising the target task while simultaneously maintaining or even enhancing performance across non-targeted tasks - a criterion hitherto unexplored in the field. Additionally, we introduce an automated approach for searching the weighting factors in the loss function, further enhancing attack efficiency. Experimental results validate our framework's ability to successfully attack the target task while preserving the performance of non-targeted tasks. The automated loss function weight searching method demonstrates comparable efficacy to manual tuning, establishing a state-of-the-art multi-task attack framework.
The Uniqueness of LLaMA3-70B with Per-Channel Quantization: An Empirical Study
Aug 27, 2024



We have observed a distinctive quantization-related behavior in the LLaMA3/3.1-70B models that is absent in both the LLaMA2-70B and LLaMA3/3.1-8B/405B models. Quantization is a crucial technique for deploying large language models (LLMs) efficiently. Among various bit widths and representations for weights and activations, the 8-bit integer weight and 8-bit integer activation (W8A8) configuration is particularly popular due to its widespread hardware support. However, the impact of W8A8 post-training quantization on model accuracy remains contentious. While several studies have suggested calibrating either weights or activations to mitigate accuracy degradation, a comprehensive solution has yet to be identified. In this paper, we empirically investigate multiple LLMs featured on an open LLM leaderboard, discovering that the LLaMA3-70B model series have a unique accuracy degradation behavior with W8A8 per-channel post-training quantization. In contrast, other model series such as LLaMA2, LLaMA3-8B, Qwen, Mixtral, Mistral, Phi-3, and Falcon demonstrate robust performance with W8A8, sometimes surpassing their FP16 counterparts. Contrary to previous assertions attributing degradation to the large dynamic range of activations, our findings indicate that the weight distribution of the LLaMA3-70B is the primary factor behind the vulnerability. By meticulously analyzing the distinct characteristics of weight distributions across Transformer blocks, we propose a mixed strategy with less than 3% of the layers enabling finer W8A8 quantization granularity, while the remaining 97% of layers retain the per-channel configuration. As a result, the average accuracy of LLaMA3-70B-W8A8 is increased from 45.5% to 73.4% (just 0.7% shy of LLaMA3-70B-FP16) across eight reasoning tasks. Notably, our method requires neither calibration nor fine-tuning.
Data Overfitting for On-Device Super-Resolution with Dynamic Algorithm and Compiler Co-Design
Jul 03, 2024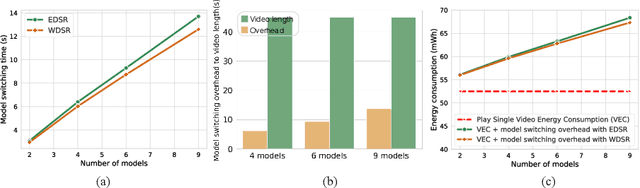

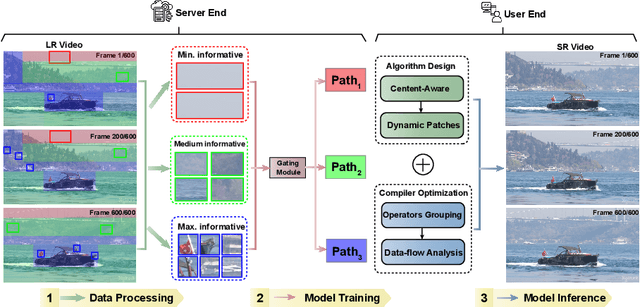
Deep neural networks (DNNs) are frequently employed in a variety of computer vision applications. Nowadays, an emerging trend in the current video distribution system is to take advantage of DNN's overfitting properties to perform video resolution upscaling. By splitting videos into chunks and applying a super-resolution (SR) model to overfit each chunk, this scheme of SR models plus video chunks is able to replace traditional video transmission to enhance video quality and transmission efficiency. However, many models and chunks are needed to guarantee high performance, which leads to tremendous overhead on model switching and memory footprints at the user end. To resolve such problems, we propose a Dynamic Deep neural network assisted by a Content-Aware data processing pipeline to reduce the model number down to one (Dy-DCA), which helps promote performance while conserving computational resources. Additionally, to achieve real acceleration on the user end, we designed a framework that optimizes dynamic features (e.g., dynamic shapes, sizes, and control flow) in Dy-DCA to enable a series of compilation optimizations, including fused code generation, static execution planning, etc. By employing such techniques, our method achieves better PSNR and real-time performance (33 FPS) on an off-the-shelf mobile phone. Meanwhile, assisted by our compilation optimization, we achieve a 1.7$\times$ speedup while saving up to 1.61$\times$ memory consumption. Code available in https://github.com/coulsonlee/Dy-DCA-ECCV2024.
Towards High-Quality and Efficient Video Super-Resolution via Spatial-Temporal Data Overfitting
Mar 15, 2023
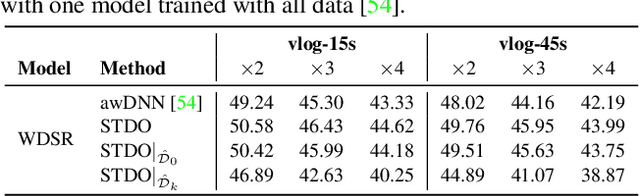
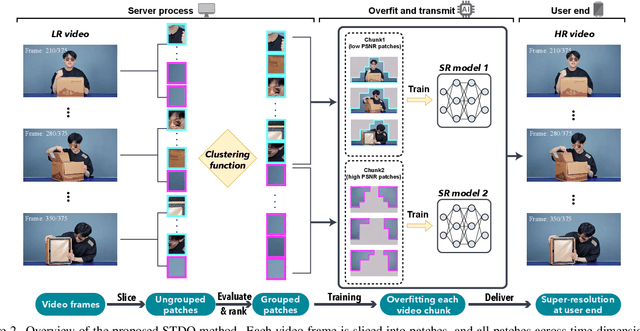
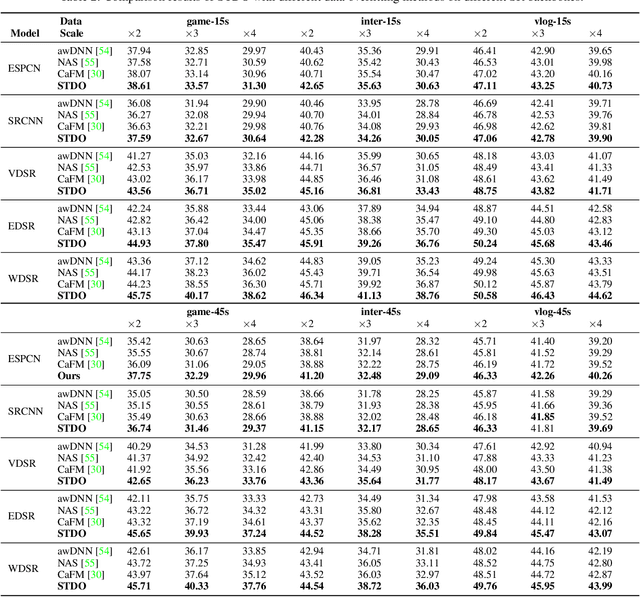
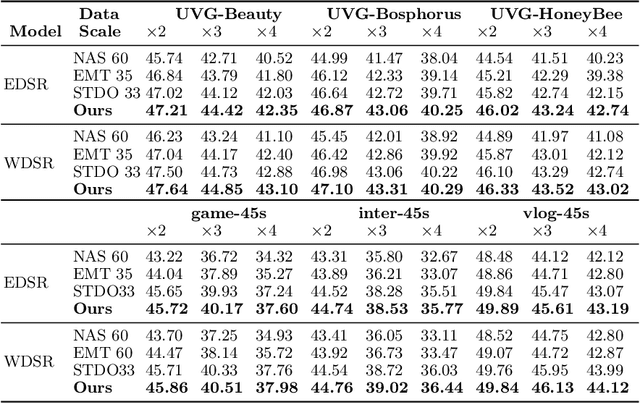
As deep convolutional neural networks (DNNs) are widely used in various fields of computer vision, leveraging the overfitting ability of the DNN to achieve video resolution upscaling has become a new trend in the modern video delivery system. By dividing videos into chunks and overfitting each chunk with a super-resolution model, the server encodes videos before transmitting them to the clients, thus achieving better video quality and transmission efficiency. However, a large number of chunks are expected to ensure good overfitting quality, which substantially increases the storage and consumes more bandwidth resources for data transmission. On the other hand, decreasing the number of chunks through training optimization techniques usually requires high model capacity, which significantly slows down execution speed. To reconcile such, we propose a novel method for high-quality and efficient video resolution upscaling tasks, which leverages the spatial-temporal information to accurately divide video into chunks, thus keeping the number of chunks as well as the model size to minimum. Additionally, we advance our method into a single overfitting model by a data-aware joint training technique, which further reduces the storage requirement with negligible quality drop. We deploy our models on an off-the-shelf mobile phone, and experimental results show that our method achieves real-time video super-resolution with high video quality. Compared with the state-of-the-art, our method achieves 28 fps streaming speed with 41.6 PSNR, which is 14$\times$ faster and 2.29 dB better in the live video resolution upscaling tasks. Our codes are available at: https://github.com/coulsonlee/STDO-CVPR2023.git
DISCO: Distributed Inference with Sparse Communications
Feb 22, 2023Deep neural networks (DNNs) have great potential to solve many real-world problems, but they usually require an extensive amount of computation and memory. It is of great difficulty to deploy a large DNN model to a single resource-limited device with small memory capacity. Distributed computing is a common approach to reduce single-node memory consumption and to accelerate the inference of DNN models. In this paper, we explore the "within-layer model parallelism", which distributes the inference of each layer into multiple nodes. In this way, the memory requirement can be distributed to many nodes, making it possible to use several edge devices to infer a large DNN model. Due to the dependency within each layer, data communications between nodes during this parallel inference can be a bottleneck when the communication bandwidth is limited. We propose a framework to train DNN models for Distributed Inference with Sparse Communications (DISCO). We convert the problem of selecting which subset of data to transmit between nodes into a model optimization problem, and derive models with both computation and communication reduction when each layer is inferred on multiple nodes. We show the benefit of the DISCO framework on a variety of CV tasks such as image classification, object detection, semantic segmentation, and image super resolution. The corresponding models include important DNN building blocks such as convolutions and transformers. For example, each layer of a ResNet-50 model can be distributively inferred across two nodes with five times less data communications, almost half overall computations and half memory requirement for a single node, and achieve comparable accuracy to the original ResNet-50 model. This also results in 4.7 times overall inference speedup.
All-in-One: A Highly Representative DNN Pruning Framework for Edge Devices with Dynamic Power Management
Dec 09, 2022



During the deployment of deep neural networks (DNNs) on edge devices, many research efforts are devoted to the limited hardware resource. However, little attention is paid to the influence of dynamic power management. As edge devices typically only have a budget of energy with batteries (rather than almost unlimited energy support on servers or workstations), their dynamic power management often changes the execution frequency as in the widely-used dynamic voltage and frequency scaling (DVFS) technique. This leads to highly unstable inference speed performance, especially for computation-intensive DNN models, which can harm user experience and waste hardware resources. We firstly identify this problem and then propose All-in-One, a highly representative pruning framework to work with dynamic power management using DVFS. The framework can use only one set of model weights and soft masks (together with other auxiliary parameters of negligible storage) to represent multiple models of various pruning ratios. By re-configuring the model to the corresponding pruning ratio for a specific execution frequency (and voltage), we are able to achieve stable inference speed, i.e., keeping the difference in speed performance under various execution frequencies as small as possible. Our experiments demonstrate that our method not only achieves high accuracy for multiple models of different pruning ratios, but also reduces their variance of inference latency for various frequencies, with minimal memory consumption of only one model and one soft mask.
Self-Ensemble Protection: Training Checkpoints Are Good Data Protectors
Nov 22, 2022As data become increasingly vital for deep learning, a company would be very cautious about releasing data, because the competitors could use the released data to train high-performance models, thereby posing a tremendous threat to the company's commercial competence. To prevent training good models on the data, imperceptible perturbations could be added to it. Since such perturbations aim at hurting the entire training process, they should reflect the vulnerability of DNN training, rather than that of a single model. Based on this new idea, we seek adversarial examples that are always unrecognized (never correctly classified) in training. In this paper, we uncover them by modeling checkpoints' gradients, forming the proposed self-ensemble protection (SEP), which is very effective because (1) learning on examples ignored during normal training tends to yield DNNs ignoring normal examples; (2) checkpoints' cross-model gradients are close to orthogonal, meaning that they are as diverse as DNNs with different architectures in conventional ensemble. That is, our amazing performance of ensemble only requires the computation of training one model. By extensive experiments with 9 baselines on 3 datasets and 5 architectures, SEP is verified to be a new state-of-the-art, e.g., our small $\ell_\infty=2/255$ perturbations reduce the accuracy of a CIFAR-10 ResNet18 from 94.56\% to 14.68\%, compared to 41.35\% by the best-known method.Code is available at https://github.com/Sizhe-Chen/SEP.
Peeling the Onion: Hierarchical Reduction of Data Redundancy for Efficient Vision Transformer Training
Nov 19, 2022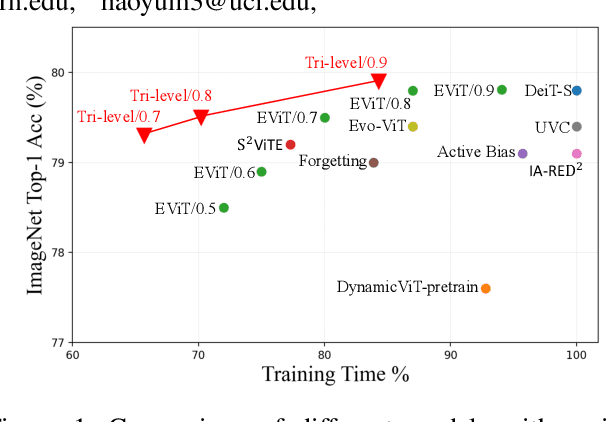
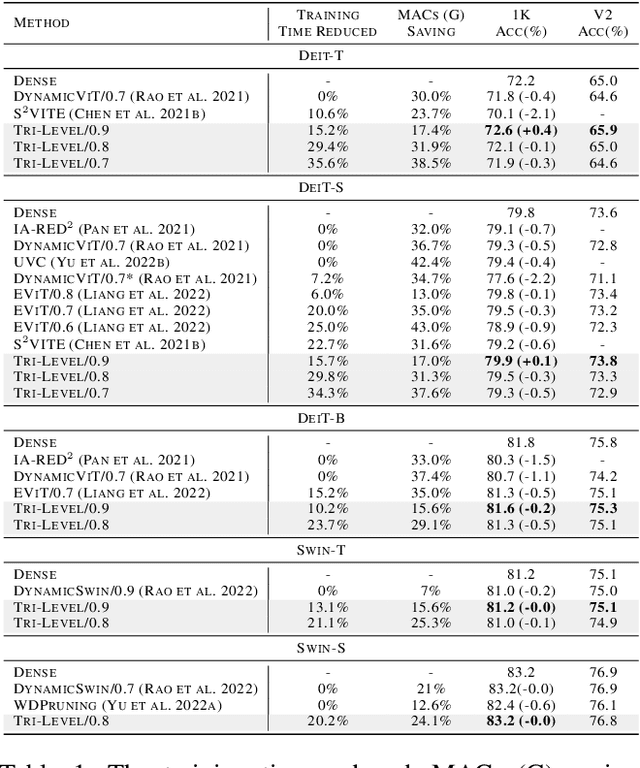


Vision transformers (ViTs) have recently obtained success in many applications, but their intensive computation and heavy memory usage at both training and inference time limit their generalization. Previous compression algorithms usually start from the pre-trained dense models and only focus on efficient inference, while time-consuming training is still unavoidable. In contrast, this paper points out that the million-scale training data is redundant, which is the fundamental reason for the tedious training. To address the issue, this paper aims to introduce sparsity into data and proposes an end-to-end efficient training framework from three sparse perspectives, dubbed Tri-Level E-ViT. Specifically, we leverage a hierarchical data redundancy reduction scheme, by exploring the sparsity under three levels: number of training examples in the dataset, number of patches (tokens) in each example, and number of connections between tokens that lie in attention weights. With extensive experiments, we demonstrate that our proposed technique can noticeably accelerate training for various ViT architectures while maintaining accuracy. Remarkably, under certain ratios, we are able to improve the ViT accuracy rather than compromising it. For example, we can achieve 15.2% speedup with 72.6% (+0.4) Top-1 accuracy on Deit-T, and 15.7% speedup with 79.9% (+0.1) Top-1 accuracy on Deit-S. This proves the existence of data redundancy in ViT.
The Lottery Ticket Hypothesis for Vision Transformers
Nov 02, 2022



The conventional lottery ticket hypothesis (LTH) claims that there exists a sparse subnetwork within a dense neural network and a proper random initialization method, called the winning ticket, such that it can be trained from scratch to almost as good as the dense counterpart. Meanwhile, the research of LTH in vision transformers (ViTs) is scarcely evaluated. In this paper, we first show that the conventional winning ticket is hard to find at weight level of ViTs by existing methods. Then, we generalize the LTH for ViTs to input images consisting of image patches inspired by the input dependence of ViTs. That is, there exists a subset of input image patches such that a ViT can be trained from scratch by using only this subset of patches and achieve similar accuracy to the ViTs trained by using all image patches. We call this subset of input patches the winning tickets, which represent a significant amount of information in the input. Furthermore, we present a simple yet effective method to find the winning tickets in input patches for various types of ViT, including DeiT, LV-ViT, and Swin Transformers. More specifically, we use a ticket selector to generate the winning tickets based on the informativeness of patches. Meanwhile, we build another randomly selected subset of patches for comparison, and the experiments show that there is clear difference between the performance of models trained with winning tickets and randomly selected subsets.
Compiler-Aware Neural Architecture Search for On-Mobile Real-time Super-Resolution
Jul 25, 2022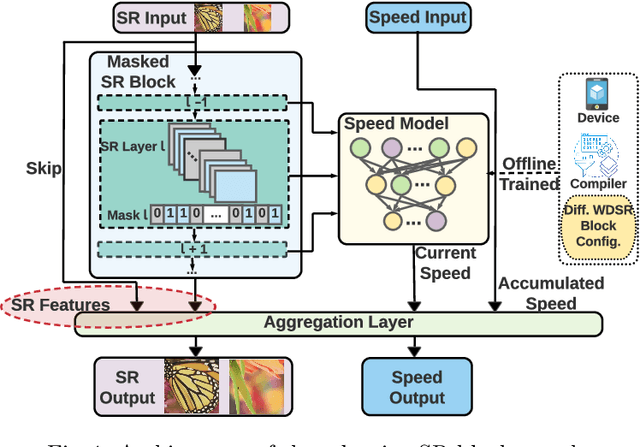
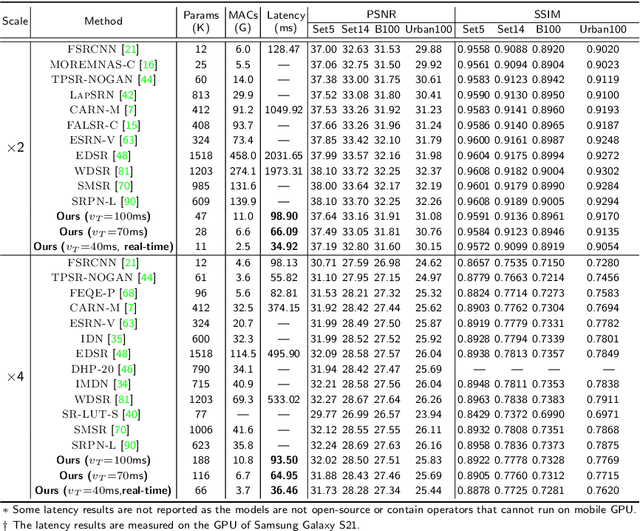


Deep learning-based super-resolution (SR) has gained tremendous popularity in recent years because of its high image quality performance and wide application scenarios. However, prior methods typically suffer from large amounts of computations and huge power consumption, causing difficulties for real-time inference, especially on resource-limited platforms such as mobile devices. To mitigate this, we propose a compiler-aware SR neural architecture search (NAS) framework that conducts depth search and per-layer width search with adaptive SR blocks. The inference speed is directly taken into the optimization along with the SR loss to derive SR models with high image quality while satisfying the real-time inference requirement. Instead of measuring the speed on mobile devices at each iteration during the search process, a speed model incorporated with compiler optimizations is leveraged to predict the inference latency of the SR block with various width configurations for faster convergence. With the proposed framework, we achieve real-time SR inference for implementing 720p resolution with competitive SR performance (in terms of PSNR and SSIM) on GPU/DSP of mobile platforms (Samsung Galaxy S21).