 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-free Super-Resolution Microvessel Color Flow Imaging with Ultrasound
May 27, 2025

We present phase subtraction imaging (PSI), a new spatial-temporal beamforming method that enables micrometer level resolution imaging of microvessels in live animals without labels, which are microbubbles in ultrasound super-resolution imaging. Subtraction of relative phase differences between consecutive frames beamformed with mismatched apodizations is used in PSI to overcome the diffraction limit. We validated this method by imaging both the mouse brain and rabbit kidney using different ultrasound probes and scanning machines.
Sculpting Memory: Multi-Concept Forgetting in Diffusion Models via Dynamic Mask and Concept-Aware Optimization
Apr 12, 2025Text-to-image (T2I) diffusion models have achieved remarkable success in generating high-quality images from textual prompts. However, their ability to store vast amounts of knowledge raises concerns in scenarios where selective forgetting is necessary, such as removing copyrighted content, reducing biases, or eliminating harmful concepts. While existing unlearning methods can remove certain concepts, they struggle with multi-concept forgetting due to instability, residual knowledge persistence, and generation quality degradation. To address these challenges, we propose \textbf{Dynamic Mask coupled with Concept-Aware Loss}, a novel unlearning framework designed for multi-concept forgetting in diffusion models. Our \textbf{Dynamic Mask} mechanism adaptively updates gradient masks based on current optimization states, allowing selective weight modifications that prevent interference with unrelated knowledge. Additionally, our \textbf{Concept-Aware Loss} explicitly guides the unlearning process by enforcing semantic consistency through superclass alignment, while a regularization loss based on knowledge distillation ensures that previously unlearned concepts remain forgotten during sequential unlearning. We conduct extensive experiments to evaluate our approach. Results demonstrate that our method outperforms existing unlearning techniques in forgetting effectiveness, output fidelity, and semantic coherence, particularly in multi-concept scenarios. Our work provides a principled and flexible framework for stable and high-fidelity unlearning in generative models. The code will be released publicly.
FairSAM: Fair Classification on Corrupted Data Through Sharpness-Aware Minimization
Mar 29, 2025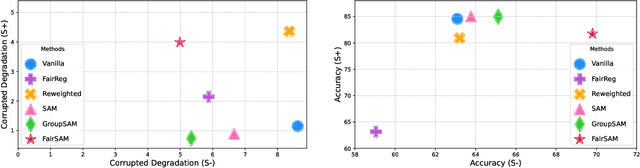
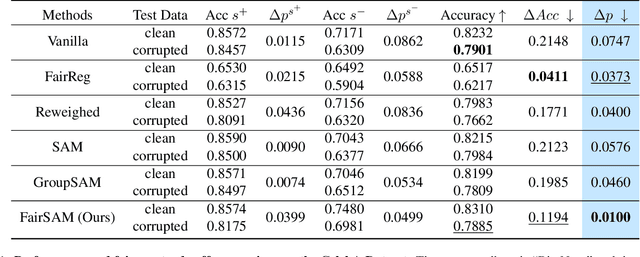

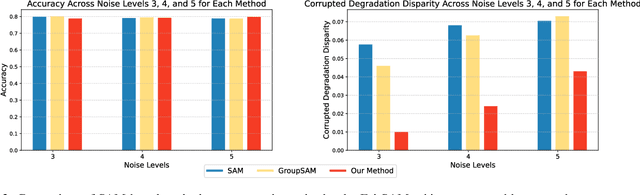
Image classification models trained on clean data often suffer from significant performance degradation when exposed to testing corrupted data, such as images with impulse noise, Gaussian noise, or environmental noise. This degradation not only impacts overall performance but also disproportionately affects various demographic subgroups, raising critical algorithmic bias concerns. Although robust learning algorithms like Sharpness-Aware Minimization (SAM) have shown promise in improving overall model robustness and generalization, they fall short in addressing the biased performance degradation across demographic subgroups. Existing fairness-aware machine learning methods - such as fairness constraints and reweighing strategies - aim to reduce performance disparities but hardly maintain robust and equitable accuracy across demographic subgroups when faced with data corruption. This reveals an inherent tension between robustness and fairness when dealing with corrupted data. To address these challenges, we introduce one novel metric specifically designed to assess performance degradation across subgroups under data corruption. Additionally, we propose \textbf{FairSAM}, a new framework that integrates \underline{Fair}ness-oriented strategies into \underline{SAM} to deliver equalized performance across demographic groups under corrupted conditions. Our experiments on multiple real-world datasets and various predictive tasks show that FairSAM successfully reconciles robustness and fairness, offering a structured solution for equitable and resilient image classification in the presence of data corruption.
Condense, Don't Just Prune: Enhancing Efficiency and Performance in MoE Layer Pruning
Nov 26, 2024



Mixture-of-Experts (MOE) has garnered significant attention for their ability to scale up neural networks while utilizing the same or even fewer active parameters. However, MoE does not relieve the massive memory requirements of networks, which limits their practicality in real-world applications, especially in the era of large language models (LLMs). While recent work explores the possibility of removing entire layers of MoE to reduce memory, the performance degradation is still notable. In this paper, we propose Condense-MoE (CD-MoE} that, instead of dropping the entire MoE layer, condenses the big, sparse MoE layer into a small but dense layer with only a few experts that are activated for all tokens. Our approach is specifically designed for fine-grained MoE with shared experts, where Feed-Forward Networks are split into many small experts, with certain experts isolated to serve as shared experts that are always activated. We demonstrate the effectiveness of our method across multiple MoE models such as DeepSeekMoE and QwenMoE on various benchmarks. Specifically, for the DeepSeekMoE-16B model, our approach maintains nearly 90% of the average accuracy while reducing memory usage by 30% and enhancing inference speed by 30%. Moreover, we show that with lightweight expert fine-tuning, the pruned model can achieve further improvements on specific tasks. Our code are available at https://github.com/duterscmy/CD-MoE/tree/main.
Data Overfitting for On-Device Super-Resolution with Dynamic Algorithm and Compiler Co-Design
Jul 03, 2024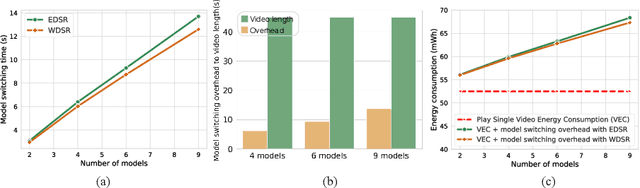

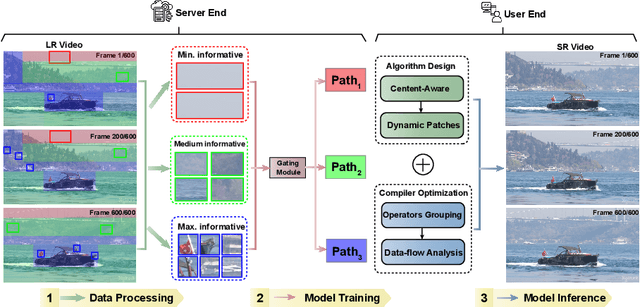
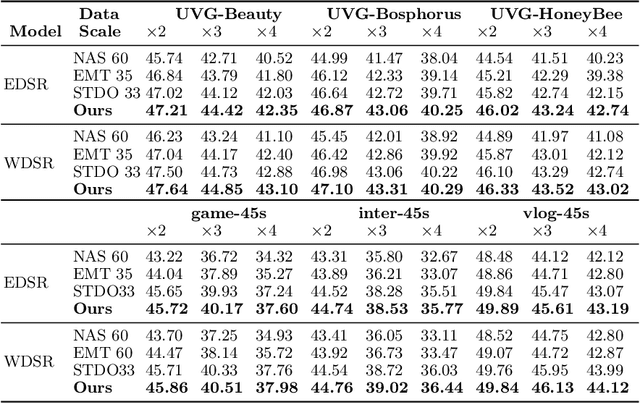
Deep neural networks (DNNs) are frequently employed in a variety of computer vision applications. Nowadays, an emerging trend in the current video distribution system is to take advantage of DNN's overfitting properties to perform video resolution upscaling. By splitting videos into chunks and applying a super-resolution (SR) model to overfit each chunk, this scheme of SR models plus video chunks is able to replace traditional video transmission to enhance video quality and transmission efficiency. However, many models and chunks are needed to guarantee high performance, which leads to tremendous overhead on model switching and memory footprints at the user end. To resolve such problems, we propose a Dynamic Deep neural network assisted by a Content-Aware data processing pipeline to reduce the model number down to one (Dy-DCA), which helps promote performance while conserving computational resources. Additionally, to achieve real acceleration on the user end, we designed a framework that optimizes dynamic features (e.g., dynamic shapes, sizes, and control flow) in Dy-DCA to enable a series of compilation optimizations, including fused code generation, static execution planning, etc. By employing such techniques, our method achieves better PSNR and real-time performance (33 FPS) on an off-the-shelf mobile phone. Meanwhile, assisted by our compilation optimization, we achieve a 1.7$\times$ speedup while saving up to 1.61$\times$ memory consumption. Code available in https://github.com/coulsonlee/Dy-DCA-ECCV2024.
Uncertainty Decomposition and Quantification for In-Context Learning of Large Language Models
Feb 15, 2024
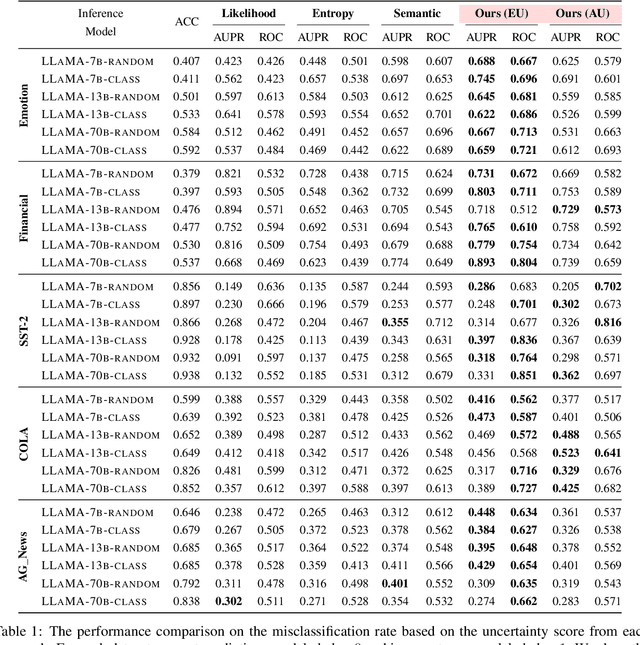
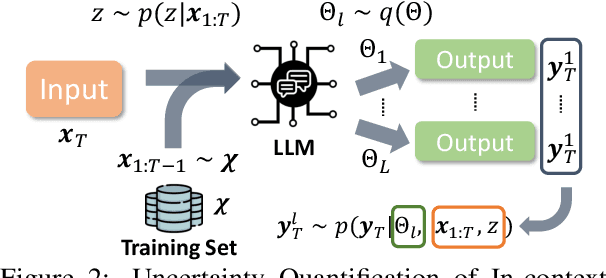
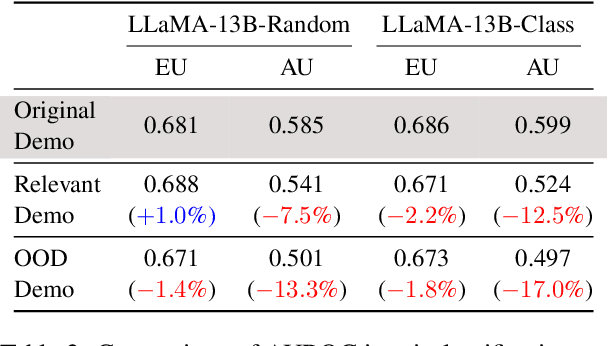
In-context learning has emerged as a groundbreaking ability of Large Language Models (LLMs) and revolutionized various fields by providing a few task-relevant demonstrations in the prompt. However, trustworthy issues with LLM's response, such as hallucination, have also been actively discussed. Existing works have been devoted to quantifying the uncertainty in LLM's response, but they often overlook the complex nature of LLMs and the uniqueness of in-context learning. In this work, we delve into the predictive uncertainty of LLMs associated with in-context learning, highlighting that such uncertainties may stem from both the provided demonstrations (aleatoric uncertainty) and ambiguities tied to the model's configurations (epistemic uncertainty). We propose a novel formulation and corresponding estimation method to quantify both types of uncertainties. The proposed method offers an unsupervised way to understand the prediction of in-context learning in a plug-and-play fashion. Extensive experiments are conducted to demonstrate the effectiveness of the decomposition. The code and data are available at: \url{https://github.com/lingchen0331/UQ_ICL}.
Multi-Loss Convolutional Network with Time-Frequency Attention for Speech Enhancement
Jun 15, 2023
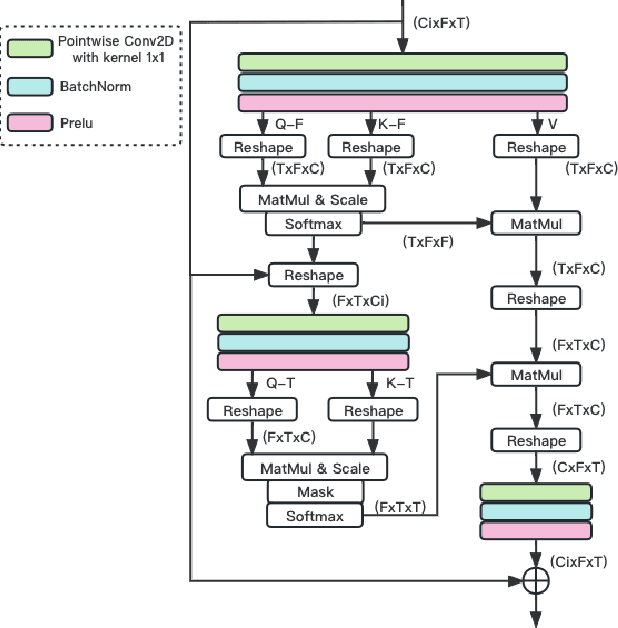
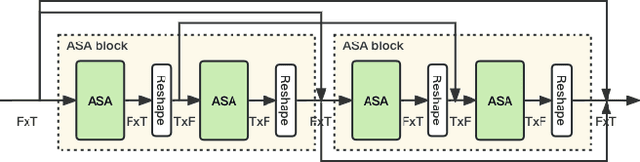
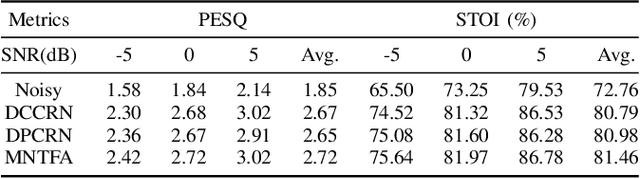
The Dual-Path Convolution Recurrent Network (DPCRN) was proposed to effectively exploit time-frequency domain information. By combining the DPRNN module with Convolution Recurrent Network (CRN), the DPCRN obtained a promising performance in speech separation with a limited model size. In this paper, we explore self-attention in the DPCRN module and design a model called Multi-Loss Convolutional Network with Time-Frequency Attention(MNTFA) for speech enhancement. We use self-attention modules to exploit the long-time information, where the intra-chunk self-attentions are used to model the spectrum pattern and the inter-chunk self-attention are used to model the dependence between consecutive frames. Compared to DPRNN, axial self-attention greatly reduces the need for memory and computation, which is more suitable for long sequences of speech signals. In addition, we propose a joint training method of a multi-resolution STFT loss and a WavLM loss using a pre-trained WavLM network. Experiments show that with only 0.23M parameters, the proposed model achieves a better performance than DPCRN.
Towards High-Quality and Efficient Video Super-Resolution via Spatial-Temporal Data Overfitting
Mar 15, 2023
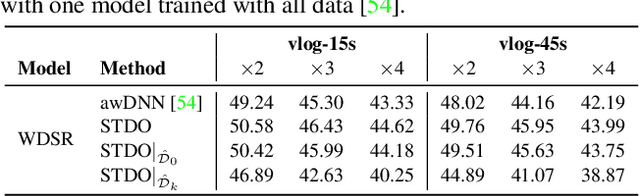
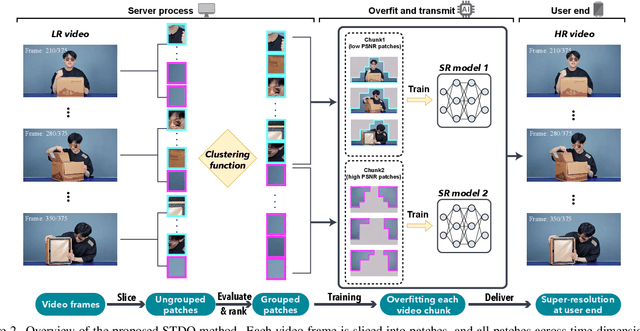
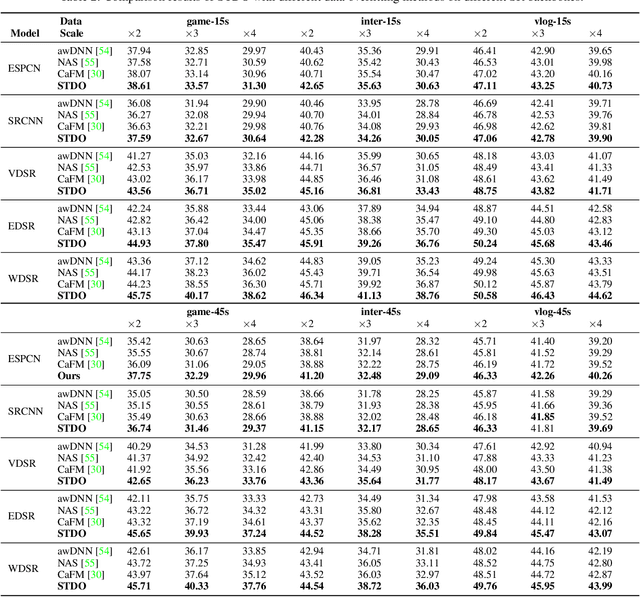
As deep convolutional neural networks (DNNs) are widely used in various fields of computer vision, leveraging the overfitting ability of the DNN to achieve video resolution upscaling has become a new trend in the modern video delivery system. By dividing videos into chunks and overfitting each chunk with a super-resolution model, the server encodes videos before transmitting them to the clients, thus achieving better video quality and transmission efficiency. However, a large number of chunks are expected to ensure good overfitting quality, which substantially increases the storage and consumes more bandwidth resources for data transmission. On the other hand, decreasing the number of chunks through training optimization techniques usually requires high model capacity, which significantly slows down execution speed. To reconcile such, we propose a novel method for high-quality and efficient video resolution upscaling tasks, which leverages the spatial-temporal information to accurately divide video into chunks, thus keeping the number of chunks as well as the model size to minimum. Additionally, we advance our method into a single overfitting model by a data-aware joint training technique, which further reduces the storage requirement with negligible quality drop. We deploy our models on an off-the-shelf mobile phone, and experimental results show that our method achieves real-time video super-resolution with high video quality. Compared with the state-of-the-art, our method achieves 28 fps streaming speed with 41.6 PSNR, which is 14$\times$ faster and 2.29 dB better in the live video resolution upscaling tasks. Our codes are available at: https://github.com/coulsonlee/STDO-CVPR2023.git
Detecting Problem Statements in Peer Assessments
May 30, 2020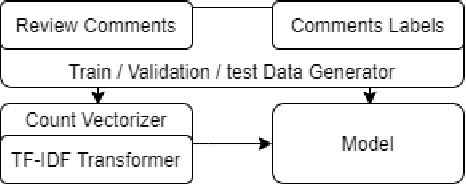

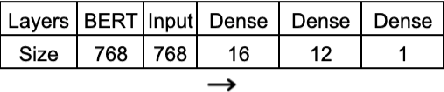

Effective peer assessment requires students to be attentive to the deficiencies in the work they rate. Thus, their reviews should identify problems. But what ways are there to check that they do? We attempt to automate the process of deciding whether a review comment detects a problem. We use over 18,000 review comments that were labeled by the reviewees as either detecting or not detecting a problem with the work. We deploy several traditional machine-learning models, as well as neural-network models using GloVe and BERT embeddings. We find that the best performer is the Hierarchical Attention Network classifier, followed by the Bidirectional Gated Recurrent Units (GRU) Attention and Capsule model with scores of 93.1% and 90.5% respectively. The best non-neural network model was the support vector machine with a score of 89.71%. This is followed by the Stochastic Gradient Descent model and the Logistic Regression model with 89.70% and 88.98%.