 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper Denoise Net: Speech Super Resolution with Noise Cancellation in Low Sampling Rate Noisy Environments
Oct 10, 2023Speech super-resolution (SSR) aims to predict a high resolution (HR) speech signal from its low resolution (LR) corresponding part. Most neural SSR models focus on producing the final result in a noise-free environment by recovering the spectrogram of high-frequency part of the signal and concatenating it with the original low-frequency part. Although these methods achieve high accuracy, they become less effective when facing the real-world scenario, where unavoidable noise is present. To address this problem, we propose a Super Denoise Net (SDNet), a neural network for a joint task of super-resolution and noise reduction from a low sampling rate signal. To that end, we design gated convolution and lattice convolution blocks to enhance the repair capability and capture information in the time-frequency axis, respectively. The experiments show our method outperforms baseline speech denoising and SSR models on DNS 2020 no-reverb test set with higher objective and subjective scores.
Multi-Loss Convolutional Network with Time-Frequency Attention for Speech Enhancement
Jun 15, 2023
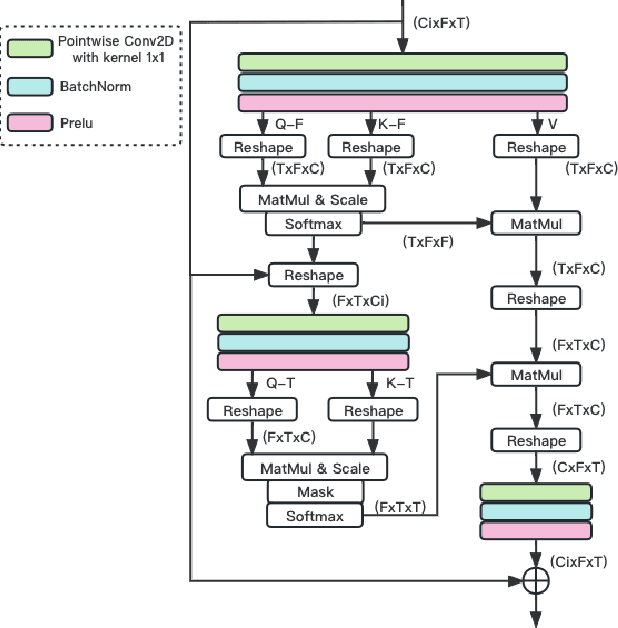
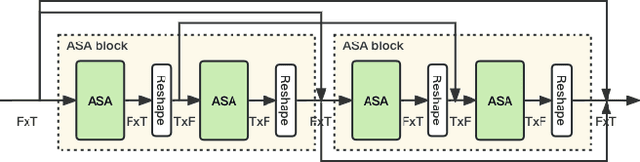
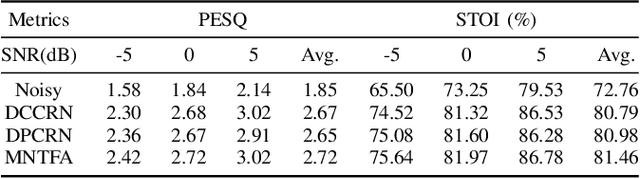
The Dual-Path Convolution Recurrent Network (DPCRN) was proposed to effectively exploit time-frequency domain information. By combining the DPRNN module with Convolution Recurrent Network (CRN), the DPCRN obtained a promising performance in speech separation with a limited model size. In this paper, we explore self-attention in the DPCRN module and design a model called Multi-Loss Convolutional Network with Time-Frequency Attention(MNTFA) for speech enhancement. We use self-attention modules to exploit the long-time information, where the intra-chunk self-attentions are used to model the spectrum pattern and the inter-chunk self-attention are used to model the dependence between consecutive frames. Compared to DPRNN, axial self-attention greatly reduces the need for memory and computation, which is more suitable for long sequences of speech signals. In addition, we propose a joint training method of a multi-resolution STFT loss and a WavLM loss using a pre-trained WavLM network. Experiments show that with only 0.23M parameters, the proposed model achieves a better performance than DPCRN.
mdctGAN: Taming transformer-based GAN for speech super-resolution with Modified DCT spectra
May 19, 2023


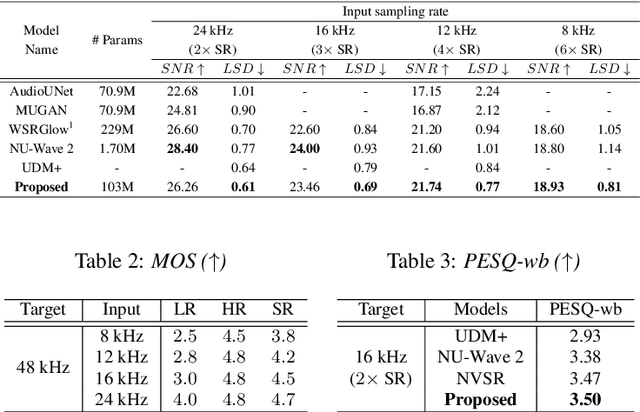
Speech super-resolution (SSR) aims to recover a high resolution (HR) speech from its corresponding low resolution (LR) counterpart. Recent SSR methods focus more on the reconstruction of the magnitude spectrogram, ignoring the importance of phase reconstruction, thereby limiting the recovery quality. To address this issue, we propose mdctGAN, a novel SSR framework based on modified discrete cosine transform (MDCT). By adversarial learning in the MDCT domain, our method reconstructs HR speeches in a phase-aware manner without vocoders or additional post-processing. Furthermore, by learning frequency consistent features with self-attentive mechanism, mdctGAN guarantees a high quality speech reconstruction. For VCTK corpus dataset, the experiment results show that our model produces natural auditory quality with high MOS and PESQ scores. It also achieves the state-of-the-art log-spectral-distance (LSD) performance on 48 kHz target resolution from various input rates. Code is available from https://github.com/neoncloud/mdctGAN