 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemdctGAN: Taming transformer-based GAN for speech super-resolution with Modified DCT spectra
Paper and Code



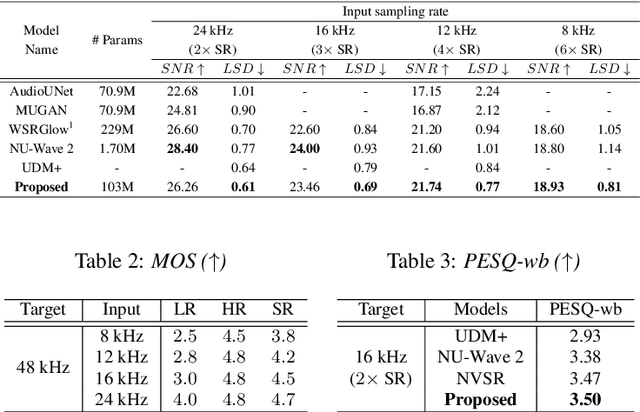
Speech super-resolution (SSR) aims to recover a high resolution (HR) speech from its corresponding low resolution (LR) counterpart. Recent SSR methods focus more on the reconstruction of the magnitude spectrogram, ignoring the importance of phase reconstruction, thereby limiting the recovery quality. To address this issue, we propose mdctGAN, a novel SSR framework based on modified discrete cosine transform (MDCT). By adversarial learning in the MDCT domain, our method reconstructs HR speeches in a phase-aware manner without vocoders or additional post-processing. Furthermore, by learning frequency consistent features with self-attentive mechanism, mdctGAN guarantees a high quality speech reconstruction. For VCTK corpus dataset, the experiment results show that our model produces natural auditory quality with high MOS and PESQ scores. It also achieves the state-of-the-art log-spectral-distance (LSD) performance on 48 kHz target resolution from various input rates. Code is available from https://github.com/neoncloud/mdctGAN