 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALL-IN-ONE: Multi-Task Learning BERT models for Evaluating Peer Assessments
Oct 08, 2021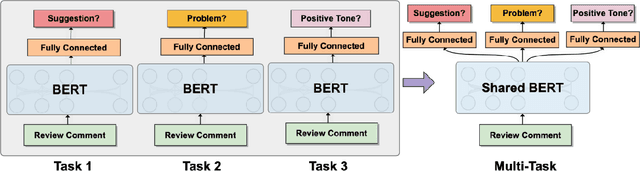
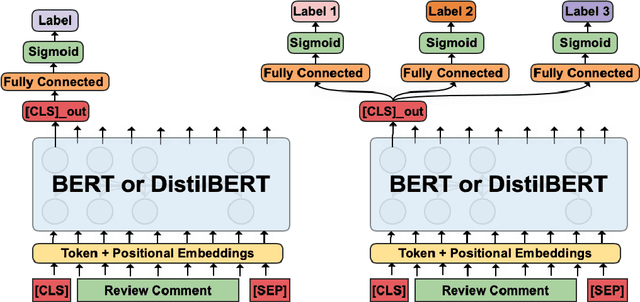
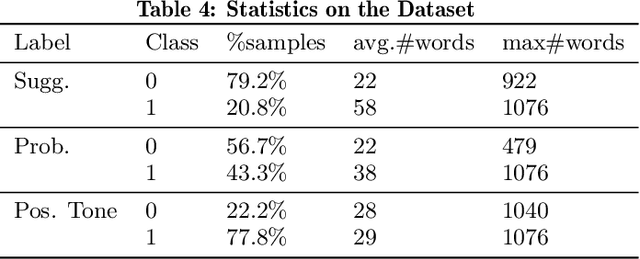
Peer assessment has been widely applied across diverse academic fields over the last few decades and has demonstrated its effectiveness. However, the advantages of peer assessment can only be achieved with high-quality peer reviews. Previous studies have found that high-quality review comments usually comprise several features (e.g., contain suggestions, mention problems, use a positive tone). Thus, researchers have attempted to evaluate peer-review comments by detecting different features using various machine learning and deep learning models. However, there is no single study that investigates using a multi-task learning (MTL) model to detect multiple features simultaneously. This paper presents two MTL models for evaluating peer-review comments by leveraging the state-of-the-art pre-trained language representation models BERT and DistilBERT. Our results demonstrate that BERT-based models significantly outperform previous GloVe-based methods by around 6% in F1-score on tasks of detecting a single feature, and MTL further improves performance while reducing model size.
Detecting Problem Statements in Peer Assessments
May 30, 2020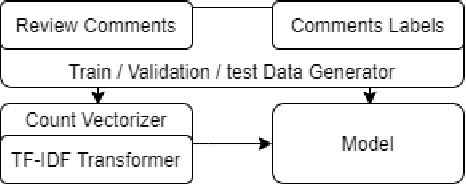

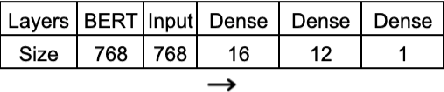

Effective peer assessment requires students to be attentive to the deficiencies in the work they rate. Thus, their reviews should identify problems. But what ways are there to check that they do? We attempt to automate the process of deciding whether a review comment detects a problem. We use over 18,000 review comments that were labeled by the reviewees as either detecting or not detecting a problem with the work. We deploy several traditional machine-learning models, as well as neural-network models using GloVe and BERT embeddings. We find that the best performer is the Hierarchical Attention Network classifier, followed by the Bidirectional Gated Recurrent Units (GRU) Attention and Capsule model with scores of 93.1% and 90.5% respectively. The best non-neural network model was the support vector machine with a score of 89.71%. This is followed by the Stochastic Gradient Descent model and the Logistic Regression model with 89.70% and 88.98%.