 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2S: Probabilistic Process Supervision for General-Domain Reasoning Question Answering
Jan 28, 2026While reinforcement learning with verifiable rewards (RLVR) has advanced LLM reasoning in structured domains like mathematics and programming, its application to general-domain reasoning tasks remains challenging due to the absence of verifiable reward signals. To this end, methods like Reinforcement Learning with Reference Probability Reward (RLPR) have emerged, leveraging the probability of generating the final answer as a reward signal. However, these outcome-focused approaches neglect crucial step-by-step supervision of the reasoning process itself. To address this gap, we introduce Probabilistic Process Supervision (P2S), a novel self-supervision framework that provides fine-grained process rewards without requiring a separate reward model or human-annotated reasoning steps. During reinforcement learning, P2S synthesizes and filters a high-quality reference reasoning chain (gold-CoT). The core of our method is to calculate a Path Faithfulness Reward (PFR) for each reasoning step, which is derived from the conditional probability of generating the gold-CoT's suffix, given the model's current reasoning prefix. Crucially, this PFR can be flexibly integrated with any outcome-based reward, directly tackling the reward sparsity problem by providing dense guidance. Extensive experiments on reading comprehension and medical Question Answering benchmarks show that P2S significantly outperforms strong baselines.
Towards Stepwise Domain Knowledge-Driven Reasoning Optimization and Reflection Improvement
Apr 12, 2025
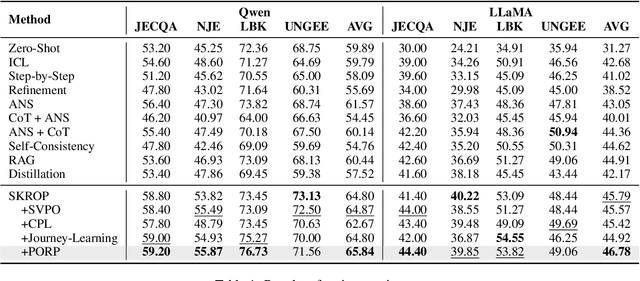
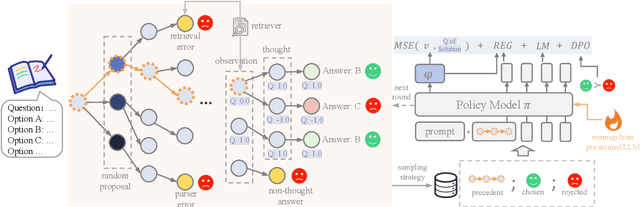
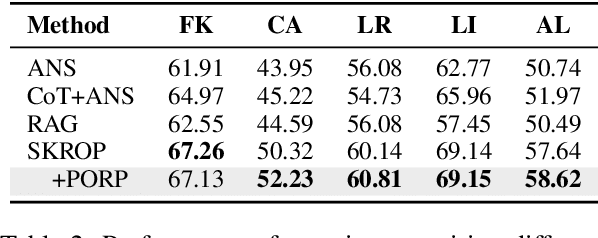
Recently, stepwise supervision on Chain of Thoughts (CoTs) presents an enhancement on the logical reasoning tasks such as coding and math, with the help of Monte Carlo Tree Search (MCTS). However, its contribution to tasks requiring domain-specific expertise and knowledge remains unexplored. Motivated by the interest, we identify several potential challenges of vanilla MCTS within this context, and propose the framework of Stepwise Domain Knowledge-Driven Reasoning Optimization, employing the MCTS algorithm to develop step-level supervision for problems that require essential comprehension, reasoning, and specialized knowledge. Additionally, we also introduce the Preference Optimization towards Reflection Paths, which iteratively learns self-reflection on the reasoning thoughts from better perspectives. We have conducted extensive experiments to evaluate the advantage of the methodologies. Empirical results demonstrate the effectiveness on various legal-domain problems. We also report a diverse set of valuable findings, hoping to encourage the enthusiasm to the research of domain-specific LLMs and MCTS.
Learning to Solve Domain-Specific Calculation Problems with Knowledge-Intensive Programs Generator
Dec 12, 2024Domain Large Language Models (LLMs) are developed for domain-specific tasks based on general LLMs. But it still requires professional knowledge to facilitate the expertise for some domain-specific tasks. In this paper, we investigate into knowledge-intensive calculation problems. We find that the math problems to be challenging for LLMs, when involving complex domain-specific rules and knowledge documents, rather than simple formulations of terminologies. Therefore, we propose a pipeline to solve the domain-specific calculation problems with Knowledge-Intensive Programs Generator more effectively, named as KIPG. It generates knowledge-intensive programs according to the domain-specific documents. For each query, key variables are extracted, then outcomes which are dependent on domain knowledge are calculated with the programs. By iterative preference alignment, the code generator learns to improve the logic consistency with the domain knowledge. Taking legal domain as an example, we have conducted experiments to prove the effectiveness of our pipeline, and extensive analysis on the modules. We also find that the code generator is also adaptable to other domains, without training on the new knowledge.
Gold Panning in Vocabulary: An Adaptive Method for Vocabulary Expansion of Domain-Specific LLMs
Oct 02, 2024



While Large Language Models (LLMs) demonstrate impressive generation abilities, they frequently struggle when it comes to specialized domains due to their limited domain-specific knowledge. Studies on domain-specific LLMs resort to expanding the vocabulary before fine-tuning on domain-specific corpus, aiming to decrease the sequence length and enhance efficiency during decoding, without thoroughly investigating the results of vocabulary expansion to LLMs over different domains. Our pilot study reveals that expansion with only a subset of the entire vocabulary may lead to superior performance. Guided by the discovery, this paper explores how to identify a vocabulary subset to achieve the optimal results. We introduce VEGAD, an adaptive method that automatically identifies valuable words from a given domain vocabulary. Our method has been validated through experiments on three Chinese datasets, demonstrating its effectiveness. Additionally, we have undertaken comprehensive analyses of the method. The selection of a optimal subset for expansion has shown to enhance performance on both domain-specific tasks and general tasks, showcasing the potential of VEGAD.
RexUniNLU: Recursive Method with Explicit Schema Instructor for Universal NLU
Sep 09, 2024
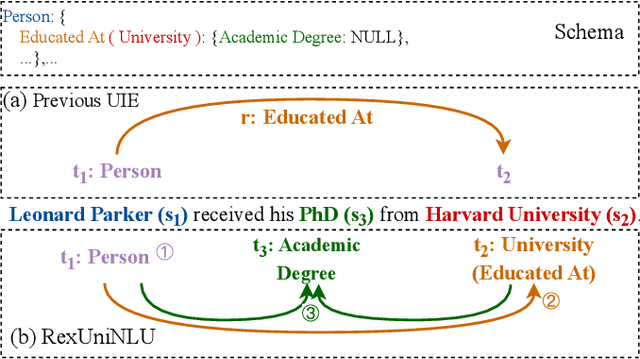
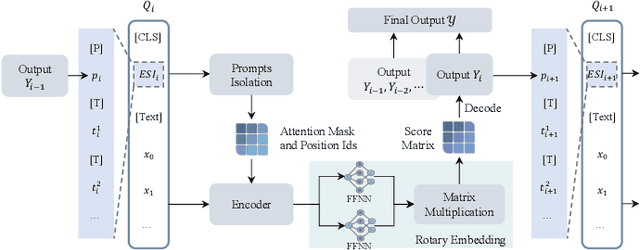
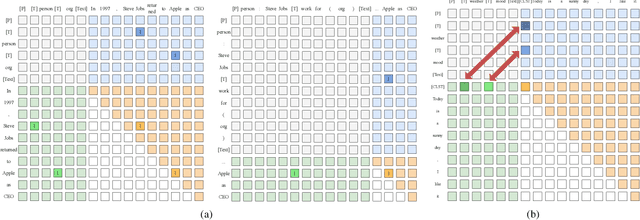
Information Extraction (IE) and Text Classification (CLS) serve as the fundamental pillars of NLU, with both disciplines relying on analyzing input sequences to categorize outputs into pre-established schemas. However, there is no existing encoder-based model that can unify IE and CLS tasks from this perspective. To fully explore the foundation shared within NLU tasks, we have proposed a Recursive Method with Explicit Schema Instructor for Universal NLU. Specifically, we firstly redefine the true universal information extraction (UIE) with a formal formulation that covers almost all extraction schemas, including quadruples and quintuples which remain unsolved for previous UIE models. Then, we expands the formulation to all CLS and multi-modal NLU tasks. Based on that, we introduce RexUniNLU, an universal NLU solution that employs explicit schema constraints for IE and CLS, which encompasses all IE and CLS tasks and prevent incorrect connections between schema and input sequence. To avoid interference between different schemas, we reset the position ids and attention mask matrices. Extensive experiments are conducted on IE, CLS in both English and Chinese, and multi-modality, revealing the effectiveness and superiority. Our codes are publicly released.
More Than Catastrophic Forgetting: Integrating General Capabilities For Domain-Specific LLMs
May 28, 2024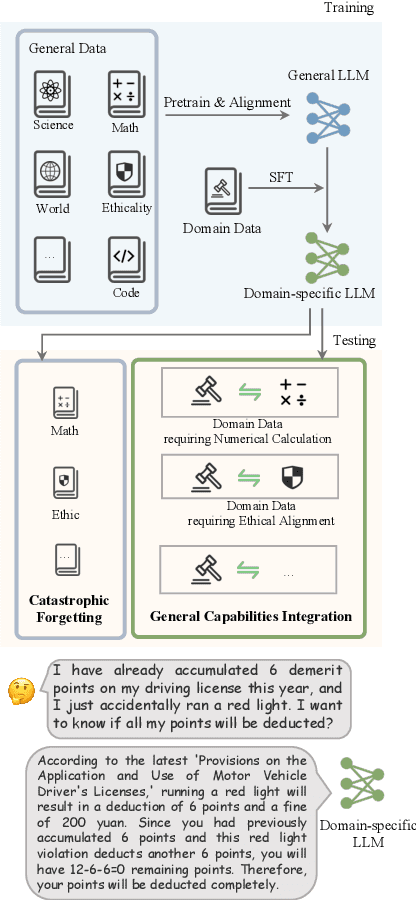


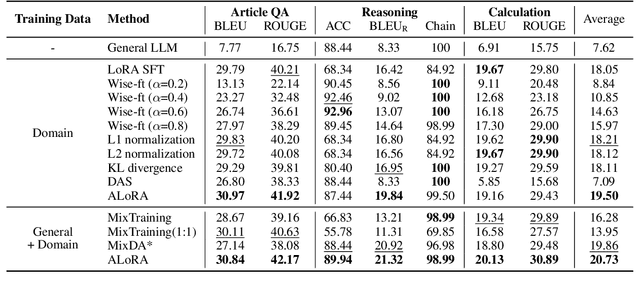
The performance on general tasks decreases after Large Language Models (LLMs) are fine-tuned on domain-specific tasks, the phenomenon is known as Catastrophic Forgetting (CF). However, this paper presents a further challenge for real application of domain-specific LLMs beyond CF, called General Capabilities Integration (GCI), which necessitates the integration of both the general capabilities and domain knowledge within a single instance. The objective of GCI is not merely to retain previously acquired general capabilities alongside new domain knowledge, but to harmonize and utilize both sets of skills in a cohesive manner to enhance performance on domain-specific tasks. Taking legal domain as an example, we carefully design three groups of training and testing tasks without lacking practicability, and construct the corresponding datasets. To better incorporate general capabilities across domain-specific scenarios, we introduce ALoRA, which utilizes a multi-head attention module upon LoRA, facilitating direct information transfer from preceding tokens to the current one. This enhancement permits the representation to dynamically switch between domain-specific knowledge and general competencies according to the attention. Extensive experiments are conducted on the proposed tasks. The results exhibit the significance of our setting, and the effectiveness of our method.
Evolving Knowledge Distillation with Large Language Models and Active Learning
Mar 11, 2024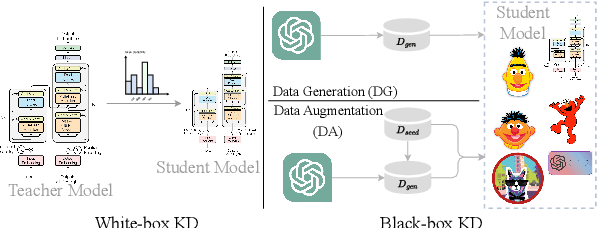
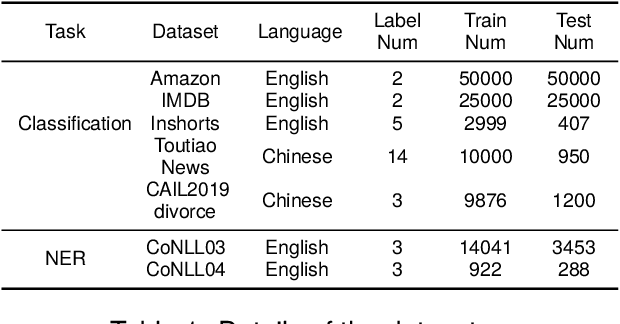

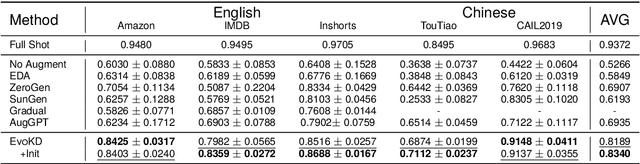
Large language models (LLMs) have demonstrated remarkable capabilities across various NLP tasks. However, their computational costs are prohibitively high. To address this issue, previous research has attempted to distill the knowledge of LLMs into smaller models by generating annotated data. Nonetheless, these works have mainly focused on the direct use of LLMs for text generation and labeling, without fully exploring their potential to comprehend the target task and acquire valuable knowledge. In this paper, we propose EvoKD: Evolving Knowledge Distillation, which leverages the concept of active learning to interactively enhance the process of data generation using large language models, simultaneously improving the task capabilities of small domain model (student model). Different from previous work, we actively analyze the student model's weaknesses, and then synthesize labeled samples based on the analysis. In addition, we provide iterative feedback to the LLMs regarding the student model's performance to continuously construct diversified and challenging samples. Experiments and analysis on different NLP tasks, namely, text classification and named entity recognition show the effectiveness of EvoKD.
A Chinese Prompt Attack Dataset for LLMs with Evil Content
Sep 21, 2023



Large Language Models (LLMs) present significant priority in text understanding and generation. However, LLMs suffer from the risk of generating harmful contents especially while being employed to applications. There are several black-box attack methods, such as Prompt Attack, which can change the behaviour of LLMs and induce LLMs to generate unexpected answers with harmful contents. Researchers are interested in Prompt Attack and Defense with LLMs, while there is no publicly available dataset to evaluate the abilities of defending prompt attack. In this paper, we introduce a Chinese Prompt Attack Dataset for LLMs, called CPAD. Our prompts aim to induce LLMs to generate unexpected outputs with several carefully designed prompt attack approaches and widely concerned attacking contents. Different from previous datasets involving safety estimation, We construct the prompts considering three dimensions: contents, attacking methods and goals, thus the responses can be easily evaluated and analysed. We run several well-known Chinese LLMs on our dataset, and the results show that our prompts are significantly harmful to LLMs, with around 70% attack success rate. We will release CPAD to encourage further studies on prompt attack and defense.
RexUIE: A Recursive Method with Explicit Schema Instructor for Universal Information Extraction
Apr 28, 2023Universal Information Extraction (UIE) is an area of interest due to the challenges posed by varying targets, heterogeneous structures, and demand-specific schemas. However, previous works have only achieved limited success by unifying a few tasks, such as Named Entity Recognition (NER) and Relation Extraction (RE), which fall short of being authentic UIE models particularly when extracting other general schemas such as quadruples and quintuples. Additionally, these models used an implicit structural schema instructor, which could lead to incorrect links between types, hindering the model's generalization and performance in low-resource scenarios. In this paper, we redefine the authentic UIE with a formal formulation that encompasses almost all extraction schemas. To the best of our knowledge, we are the first to introduce UIE for any kind of schemas. In addition, we propose RexUIE, which is a Recursive Method with Explicit Schema Instructor for UIE. To avoid interference between different types, we reset the position ids and attention mask matrices. RexUIE shows strong performance under both full-shot and few-shot settings and achieves State-of-the-Art results on the tasks of extracting complex schemas.
Investigating the Robustness of Natural Language Generation from Logical Forms via Counterfactual Samples
Oct 16, 2022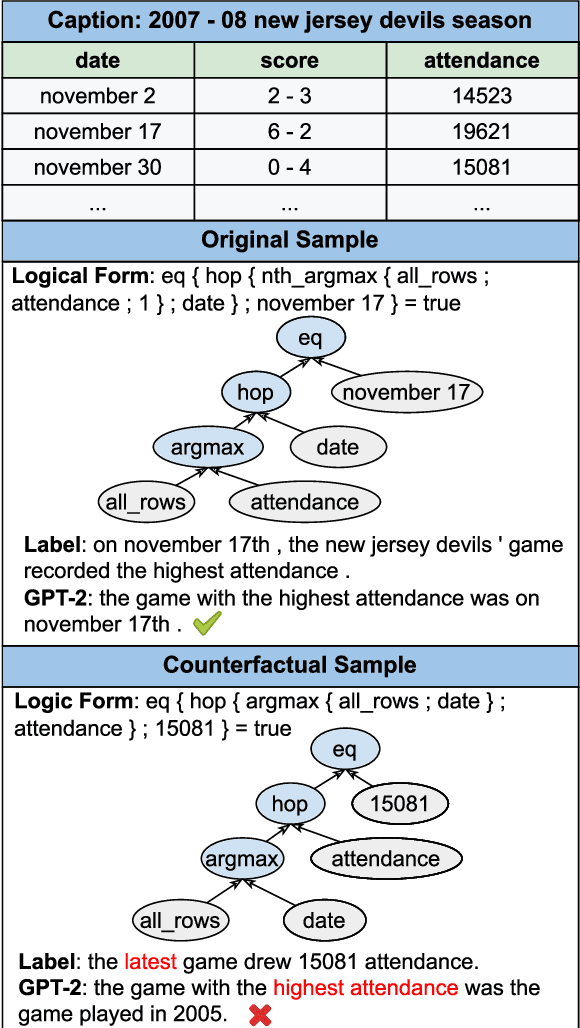
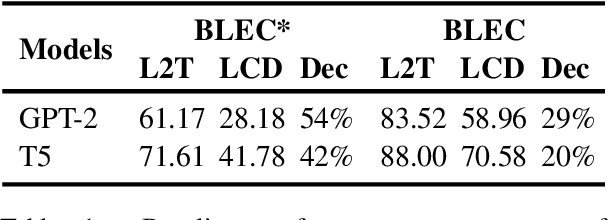
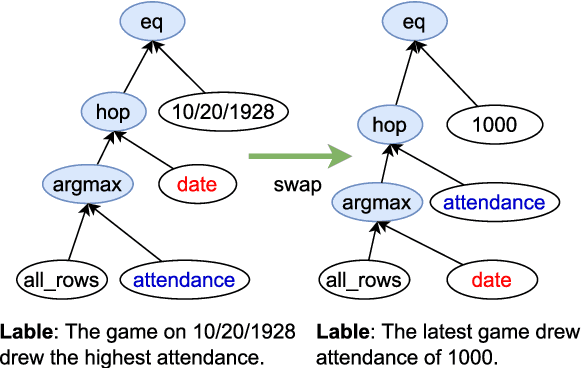
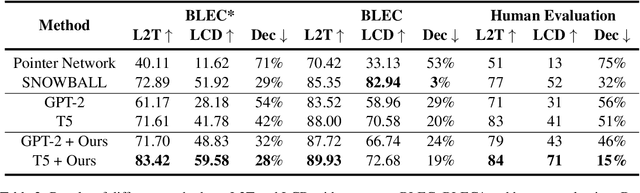
The aim of Logic2Text is to generate controllable and faithful texts conditioned on tables and logical forms, which not only requires a deep understanding of the tables and logical forms, but also warrants symbolic reasoning over the tables. State-of-the-art methods based on pre-trained models have achieved remarkable performance on the standard test dataset. However, we question whether these methods really learn how to perform logical reasoning, rather than just relying on the spurious correlations between the headers of the tables and operators of the logical form. To verify this hypothesis, we manually construct a set of counterfactual samples, which modify the original logical forms to generate counterfactual logical forms with rarely co-occurred table headers and logical operators. SOTA methods give much worse results on these counterfactual samples compared with the results on the original test dataset, which verifies our hypothesis. To deal with this problem, we firstly analyze this bias from a causal perspective, based on which we propose two approaches to reduce the model's reliance on the shortcut. The first one incorporates the hierarchical structure of the logical forms into the model. The second one exploits automatically generated counterfactual data for training. Automatic and manual experimental results on the original test dataset and the counterfactual dataset show that our method is effective to alleviate the spurious correlation. Our work points out the weakness of previous methods and takes a further step toward developing Logic2Text models with real logical reasoning ability.