 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAD: A Large-Scale Strategic Argumentative Dialogue Dataset
Jan 12, 2026Argumentation generation has attracted substantial research interest due to its central role in human reasoning and decision-making. However, most existing argumentative corpora focus on non-interactive, single-turn settings, either generating arguments from a given topic or refuting an existing argument. In practice, however, argumentation is often realized as multi-turn dialogue, where speakers defend their stances and employ diverse argumentative strategies to strengthen persuasiveness. To support deeper modeling of argumentation dialogue, we present the first large-scale \textbf{S}trategic \textbf{A}rgumentative \textbf{D}ialogue dataset, SAD, consisting of 392,822 examples. Grounded in argumentation theories, we annotate each utterance with five strategy types, allowing multiple strategies per utterance. Unlike prior datasets, SAD requires models to generate contextually appropriate arguments conditioned on the dialogue history, a specified stance on the topic, and targeted argumentation strategies. We further benchmark a range of pretrained generative models on SAD and present in-depth analysis of strategy usage patterns in argumentation.
LeCoDe: A Benchmark Dataset for Interactive Legal Consultation Dialogue Evaluation
May 26, 2025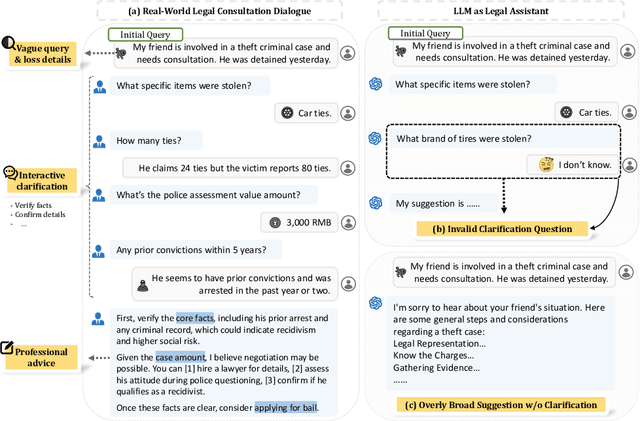


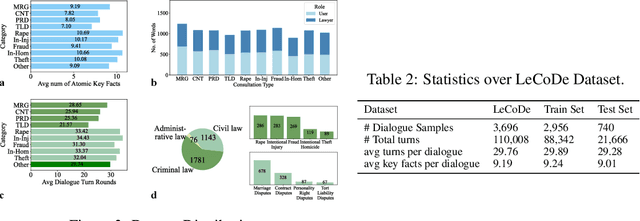
Legal consultation is essential for safeguarding individual rights and ensuring access to justice, yet remains costly and inaccessible to many individuals due to the shortage of professionals. While recent advances in Large Language Models (LLMs) offer a promising path toward scalable, low-cost legal assistance, current systems fall short in handling the interactive and knowledge-intensive nature of real-world consultations. To address these challenges, we introduce LeCoDe, a real-world multi-turn benchmark dataset comprising 3,696 legal consultation dialogues with 110,008 dialogue turns, designed to evaluate and improve LLMs' legal consultation capability. With LeCoDe, we innovatively collect live-streamed consultations from short-video platforms, providing authentic multi-turn legal consultation dialogues. The rigorous annotation by legal experts further enhances the dataset with professional insights and expertise. Furthermore, we propose a comprehensive evaluation framework that assesses LLMs' consultation capabilities in terms of (1) clarification capability and (2) professional advice quality. This unified framework incorporates 12 metrics across two dimensions. Through extensive experiments on various general and domain-specific LLMs, our results reveal significant challenges in this task, with even state-of-the-art models like GPT-4 achieving only 39.8% recall for clarification and 59% overall score for advice quality, highlighting the complexity of professional consultation scenarios. Based on these findings, we further explore several strategies to enhance LLMs' legal consultation abilities. Our benchmark contributes to advancing research in legal domain dialogue systems, particularly in simulating more real-world user-expert interactions.
Towards Stepwise Domain Knowledge-Driven Reasoning Optimization and Reflection Improvement
Apr 12, 2025
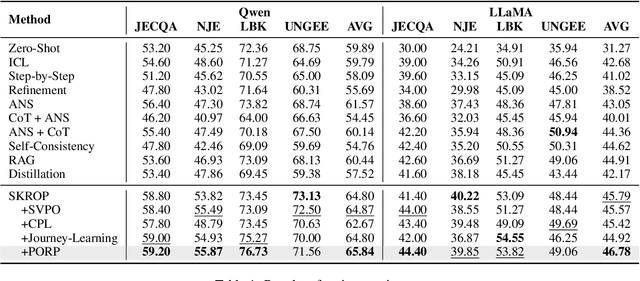
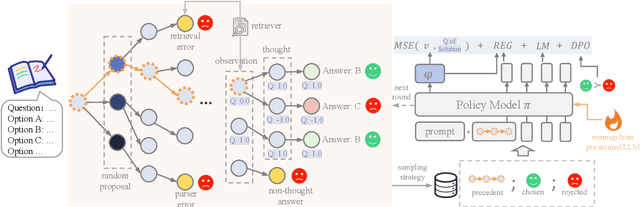
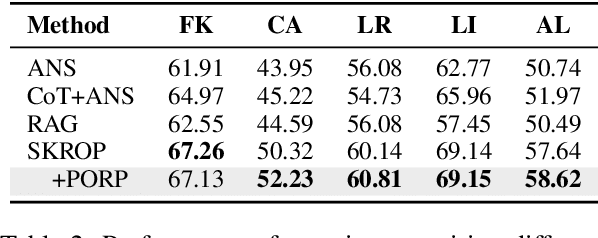
Recently, stepwise supervision on Chain of Thoughts (CoTs) presents an enhancement on the logical reasoning tasks such as coding and math, with the help of Monte Carlo Tree Search (MCTS). However, its contribution to tasks requiring domain-specific expertise and knowledge remains unexplored. Motivated by the interest, we identify several potential challenges of vanilla MCTS within this context, and propose the framework of Stepwise Domain Knowledge-Driven Reasoning Optimization, employing the MCTS algorithm to develop step-level supervision for problems that require essential comprehension, reasoning, and specialized knowledge. Additionally, we also introduce the Preference Optimization towards Reflection Paths, which iteratively learns self-reflection on the reasoning thoughts from better perspectives. We have conducted extensive experiments to evaluate the advantage of the methodologies. Empirical results demonstrate the effectiveness on various legal-domain problems. We also report a diverse set of valuable findings, hoping to encourage the enthusiasm to the research of domain-specific LLMs and MCTS.
LangGFM: A Large Language Model Alone Can be a Powerful Graph Foundation Model
Oct 19, 2024

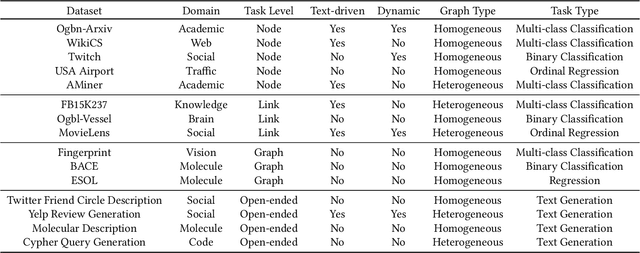
Graph foundation models (GFMs) have recently gained significant attention. However, the unique data processing and evaluation setups employed by different studies hinder a deeper understanding of their progress. Additionally, current research tends to focus on specific subsets of graph learning tasks, such as structural tasks, node-level tasks, or classification tasks. As a result, they often incorporate specialized modules tailored to particular task types, losing their applicability to other graph learning tasks and contradicting the original intent of foundation models to be universal. Therefore, to enhance consistency, coverage, and diversity across domains, tasks, and research interests within the graph learning community in the evaluation of GFMs, we propose GFMBench-a systematic and comprehensive benchmark comprising 26 datasets. Moreover, we introduce LangGFM, a novel GFM that relies entirely on large language models. By revisiting and exploring the effective graph textualization principles, as well as repurposing successful techniques from graph augmentation and graph self-supervised learning within the language space, LangGFM achieves performance on par with or exceeding the state of the art across GFMBench, which can offer us new perspectives, experiences, and baselines to drive forward the evolution of GFMs.
A Speaker Turn-Aware Multi-Task Adversarial Network for Joint User Satisfaction Estimation and Sentiment Analysis
Oct 12, 2024



User Satisfaction Estimation is an important task and increasingly being applied in goal-oriented dialogue systems to estimate whether the user is satisfied with the service. It is observed that whether the user's needs are met often triggers various sentiments, which can be pertinent to the successful estimation of user satisfaction, and vice versa. Thus, User Satisfaction Estimation (USE) and Sentiment Analysis (SA) should be treated as a joint, collaborative effort, considering the strong connections between the sentiment states of speakers and the user satisfaction. Existing joint learning frameworks mainly unify the two highly pertinent tasks over cascade or shared-bottom implementations, however they fail to distinguish task-specific and common features, which will produce sub-optimal utterance representations for downstream tasks. In this paper, we propose a novel Speaker Turn-Aware Multi-Task Adversarial Network (STMAN) for dialogue-level USE and utterance-level SA. Specifically, we first introduce a multi-task adversarial strategy which trains a task discriminator to make utterance representation more task-specific, and then utilize a speaker-turn aware multi-task interaction strategy to extract the common features which are complementary to each task. Extensive experiments conducted on two real-world service dialogue datasets show that our model outperforms several state-of-the-art methods.
Can Large Language Models Grasp Legal Theories? Enhance Legal Reasoning with Insights from Multi-Agent Collaboration
Oct 03, 2024
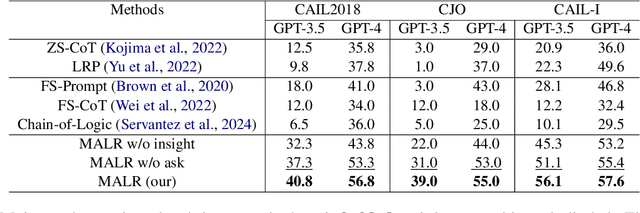

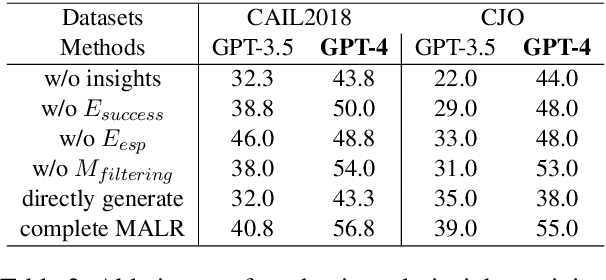
Large Language Models (LLMs) could struggle to fully understand legal theories and perform complex legal reasoning tasks. In this study, we introduce a challenging task (confusing charge prediction) to better evaluate LLMs' understanding of legal theories and reasoning capabilities. We also propose a novel framework: Multi-Agent framework for improving complex Legal Reasoning capability (MALR). MALR employs non-parametric learning, encouraging LLMs to automatically decompose complex legal tasks and mimic human learning process to extract insights from legal rules, helping LLMs better understand legal theories and enhance their legal reasoning abilities. Extensive experiments on multiple real-world datasets demonstrate that the proposed framework effectively addresses complex reasoning issues in practical scenarios, paving the way for more reliable applications in the legal domain.
Can LLMs Beat Humans in Debating? A Dynamic Multi-agent Framework for Competitive Debate
Aug 08, 2024



Competitive debate is a comprehensive and complex computational argumentation task. Large Language Models (LLMs) encounter hallucinations and lack competitiveness in this task. To address these challenges, we introduce Agent for Debate (Agent4Debate), a dynamic, multi-agent framework based on LLMs designed to enhance their capabilities in competitive debate. Drawing inspiration from human behavior in debate preparation and execution, Agent4Debate employs a collaborative architecture where four specialized agents (Searcher, Analyzer, Writer, and Reviewer) dynamically interact and cooperate. These agents work throughout the debate process, covering multiple stages from initial research and argument formulation to rebuttal and summary. To comprehensively evaluate framework performance, we construct the Chinese Debate Arena, comprising 66 carefully selected Chinese debate motions. We recruite ten experienced human debaters and collect records of 200 debates involving Agent4Debate, baseline models, and humans. The evaluation employs the Debatrix automatic scoring system and professional human reviewers based on the established Debatrix-Elo and Human-Elo ranking. Experimental results indicate that the state-of-the-art Agent4Debate exhibits capabilities comparable to those of humans. Furthermore, ablation studies demonstrate the effectiveness of each component in the agent structure.
Affective Computing in the Era of Large Language Models: A Survey from the NLP Perspective
Jul 30, 2024



Affective Computing (AC), integrating computer science, psychology, and cognitive science knowledge, aims to enable machines to recognize, interpret, and simulate human emotions.To create more value, AC can be applied to diverse scenarios, including social media, finance, healthcare, education, etc. Affective Computing (AC) includes two mainstream tasks, i.e., Affective Understanding (AU) and Affective Generation (AG). Fine-tuning Pre-trained Language Models (PLMs) for AU tasks has succeeded considerably. However, these models lack generalization ability, requiring specialized models for specific tasks. Additionally, traditional PLMs face challenges in AG, particularly in generating diverse and emotionally rich responses. The emergence of Large Language Models (LLMs), such as the ChatGPT series and LLaMA models, brings new opportunities and challenges, catalyzing a paradigm shift in AC. LLMs possess capabilities of in-context learning, common sense reasoning, and advanced sequence generation, which present unprecedented opportunities for AU. To provide a comprehensive overview of AC in the LLMs era from an NLP perspective, we summarize the development of LLMs research in this field, aiming to offer new insights. Specifically, we first summarize the traditional tasks related to AC and introduce the preliminary study based on LLMs. Subsequently, we outline the relevant techniques of popular LLMs to improve AC tasks, including Instruction Tuning and Prompt Engineering. For Instruction Tuning, we discuss full parameter fine-tuning and parameter-efficient methods such as LoRA, P-Tuning, and Prompt Tuning. In Prompt Engineering, we examine Zero-shot, Few-shot, Chain of Thought (CoT), and Agent-based methods for AU and AG. To clearly understand the performance of LLMs on different Affective Computing tasks, we further summarize the existing benchmarks and evaluation methods.
StickerConv: Generating Multimodal Empathetic Responses from Scratch
Jan 20, 2024Stickers, while widely recognized for enhancing empathetic communication in online interactions, remain underexplored in current empathetic dialogue research. In this paper, we introduce the Agent for StickerConv (Agent4SC), which uses collaborative agent interactions to realistically simulate human behavior with sticker usage, thereby enhancing multimodal empathetic communication. Building on this foundation, we develop a multimodal empathetic dialogue dataset, StickerConv, which includes 12.9K dialogue sessions, 5.8K unique stickers, and 2K diverse conversational scenarios, specifically designs to augment the generation of empathetic responses in a multimodal context. To leverage the richness of this dataset, we propose PErceive and Generate Stickers (PEGS), a multimodal empathetic response generation model, complemented by a comprehensive set of empathy evaluation metrics based on LLM. Our experiments demonstrate PEGS's effectiveness in generating contextually relevant and emotionally resonant multimodal empathetic responses, contributing to the advancement of more nuanced and engaging empathetic dialogue systems. Our project page is available at https://neu-datamining.github.io/StickerConv .
Empowering Dual-Level Graph Self-Supervised Pretraining with Motif Discovery
Dec 19, 2023

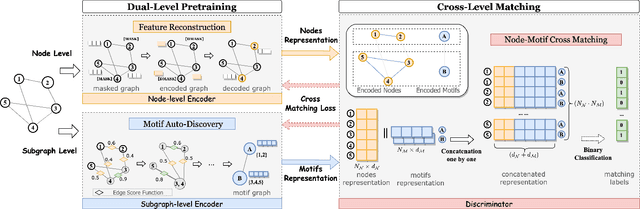
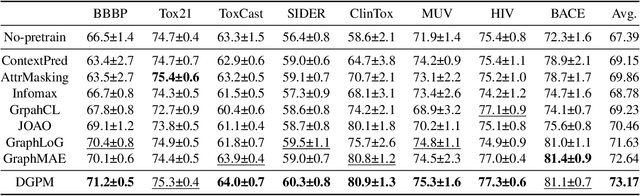
While self-supervised graph pretraining techniques have shown promising results in various domains, their application still experiences challenges of limited topology learning, human knowledge dependency, and incompetent multi-level interactions. To address these issues, we propose a novel solution, Dual-level Graph self-supervised Pretraining with Motif discovery (DGPM), which introduces a unique dual-level pretraining structure that orchestrates node-level and subgraph-level pretext tasks. Unlike prior approaches, DGPM autonomously uncovers significant graph motifs through an edge pooling module, aligning learned motif similarities with graph kernel-based similarities. A cross-matching task enables sophisticated node-motif interactions and novel representation learning. Extensive experiments on 15 datasets validate DGPM's effectiveness and generalizability, outperforming state-of-the-art methods in unsupervised representation learning and transfer learning settings. The autonomously discovered motifs demonstrate the potential of DGPM to enhance robustness and interpretability.