 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective User-defined Keyword Spotting with Dual-stage Matching, Multi-modal Enrollment, and Continual Adaptation
May 21, 2026User-defined keyword spotting (KWS) is crucial for personalized voice interaction, yet existing methods face several challenges: (1) insufficient discriminability among confusable words, (2) performance inconsistency across speakers with varying pronunciations, and (3) high data cost to ensure reliable wake-word performance. In this paper, we introduce DMA-KWS, an efficient and robust framework for user-defined keyword spotting. First, it adopts a dual-stage matching pipeline: CTC decoding with streaming phoneme search to locate candidate segments, followed by QbyT with a phoneme matcher for fine-grained verification, enabling it to better distinguish confusable words. Next, multi-modal enrollment fuses user-specific speech with text embeddings to further improve accuracy for registered users. Finally, a parameter-efficient continual adaptation mechanism performs lightweight updates using synthetic and real data. Extensive experiments demonstrate the superior performance of DMA-KWS. On the LibriPhrase Hard subset, it achieves 97.85% AUC and 6.13% EER, reaching state-of-the-art performance. In speaker-dependent settings, DMA-KWS consistently outperforms text-only enrollment, demonstrating significant performance gains. Moreover, the proposed parameter-efficient fine-tuning mechanism adapts DMA-KWS with only 187k updated parameters, further enhancing KWS performance while ensuring suitability for on-device deployment.
A Learnable Color Correction Matrix for RAW Reconstruction
Sep 04, 2024



Autonomous driving algorithms usually employ sRGB images as model input due to their compatibility with the human visual system. However, visually pleasing sRGB images are possibly sub-optimal for downstream tasks when compared to RAW images. The availability of RAW images is constrained by the difficulties in collecting real-world driving data and the associated challenges of annotation. To address this limitation and support research in RAW-domain driving perception, we design a novel and ultra-lightweight RAW reconstruction method. The proposed model introduces a learnable color correction matrix (CCM), which uses only a single convolutional layer to approximate the complex inverse image signal processor (ISP). Experimental results demonstrate that simulated RAW (simRAW) images generated by our method provide performance improvements equivalent to those produced by more complex inverse ISP methods when pretraining RAW-domain object detectors, which highlights the effectiveness and practicality of our approach.
TLD: A Vehicle Tail Light signal Dataset and Benchmark
Sep 04, 2024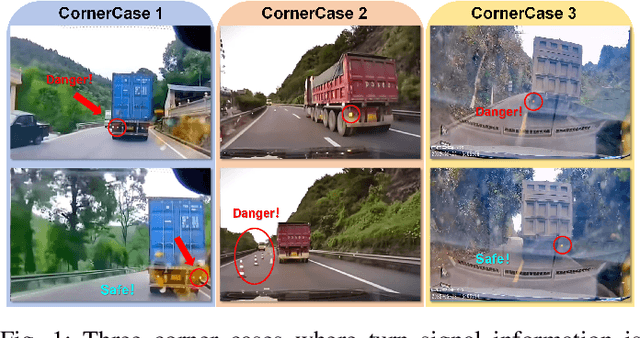


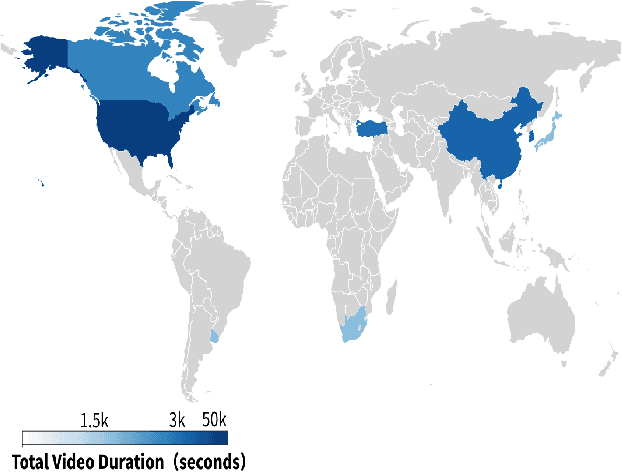
Understanding other drivers' intentions is crucial for safe driving. The role of taillights in conveying these intentions is underemphasized in current autonomous driving systems. Accurately identifying taillight signals is essential for predicting vehicle behavior and preventing collisions. Open-source taillight datasets are scarce, often small and inconsistently annotated. To address this gap, we introduce a new large-scale taillight dataset called TLD. Sourced globally, our dataset covers diverse traffic scenarios. To our knowledge, TLD is the first dataset to separately annotate brake lights and turn signals in real driving scenarios. We collected 17.78 hours of driving videos from the internet. This dataset consists of 152k labeled image frames sampled at a rate of 2 Hz, along with 1.5 million unlabeled frames interspersed throughout. Additionally, we have developed a two-stage vehicle light detection model consisting of two primary modules: a vehicle detector and a taillight classifier. Initially, YOLOv10 and DeepSORT captured consecutive vehicle images over time. Subsequently, the two classifiers work simultaneously to determine the states of the brake lights and turn signals. A post-processing procedure is then used to eliminate noise caused by misidentifications and provide the taillight states of the vehicle within a given time frame. Our method shows exceptional performance on our dataset, establishing a benchmark for vehicle taillight detection. The dataset is available at https://huggingface.co/datasets/ChaiJohn/TLD/tree/main
Affective Computing in the Era of Large Language Models: A Survey from the NLP Perspective
Jul 30, 2024



Affective Computing (AC), integrating computer science, psychology, and cognitive science knowledge, aims to enable machines to recognize, interpret, and simulate human emotions.To create more value, AC can be applied to diverse scenarios, including social media, finance, healthcare, education, etc. Affective Computing (AC) includes two mainstream tasks, i.e., Affective Understanding (AU) and Affective Generation (AG). Fine-tuning Pre-trained Language Models (PLMs) for AU tasks has succeeded considerably. However, these models lack generalization ability, requiring specialized models for specific tasks. Additionally, traditional PLMs face challenges in AG, particularly in generating diverse and emotionally rich responses. The emergence of Large Language Models (LLMs), such as the ChatGPT series and LLaMA models, brings new opportunities and challenges, catalyzing a paradigm shift in AC. LLMs possess capabilities of in-context learning, common sense reasoning, and advanced sequence generation, which present unprecedented opportunities for AU. To provide a comprehensive overview of AC in the LLMs era from an NLP perspective, we summarize the development of LLMs research in this field, aiming to offer new insights. Specifically, we first summarize the traditional tasks related to AC and introduce the preliminary study based on LLMs. Subsequently, we outline the relevant techniques of popular LLMs to improve AC tasks, including Instruction Tuning and Prompt Engineering. For Instruction Tuning, we discuss full parameter fine-tuning and parameter-efficient methods such as LoRA, P-Tuning, and Prompt Tuning. In Prompt Engineering, we examine Zero-shot, Few-shot, Chain of Thought (CoT), and Agent-based methods for AU and AG. To clearly understand the performance of LLMs on different Affective Computing tasks, we further summarize the existing benchmarks and evaluation methods.
HENet: Forcing a Network to Think More for Font Recognition
Oct 21, 2021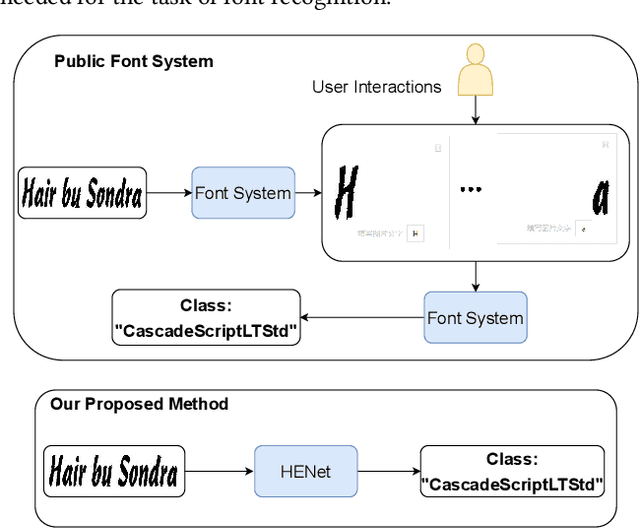
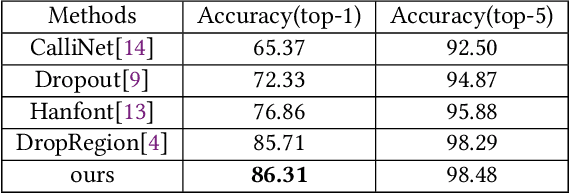
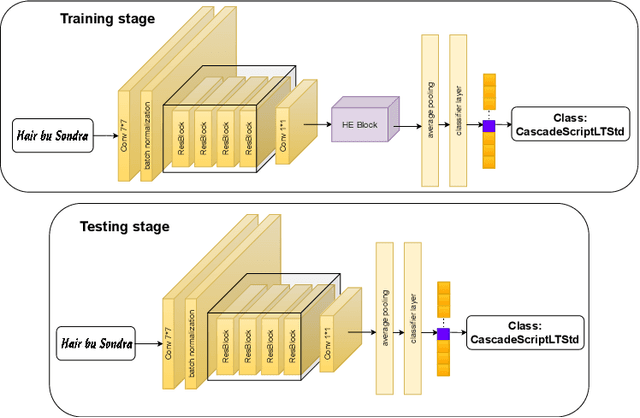

Although lots of progress were made in Text Recognition/OCR in recent years, the task of font recognition is remaining challenging. The main challenge lies in the subtle difference between these similar fonts, which is hard to distinguish. This paper proposes a novel font recognizer with a pluggable module solving the font recognition task. The pluggable module hides the most discriminative accessible features and forces the network to consider other complicated features to solve the hard examples of similar fonts, called HE Block. Compared with the available public font recognition systems, our proposed method does not require any interactions at the inference stage. Extensive experiments demonstrate that HENet achieves encouraging performance, including on character-level dataset Explor_all and word-level dataset AdobeVFR
IFR: Iterative Fusion Based Recognizer For Low Quality Scene Text Recognition
Aug 13, 2021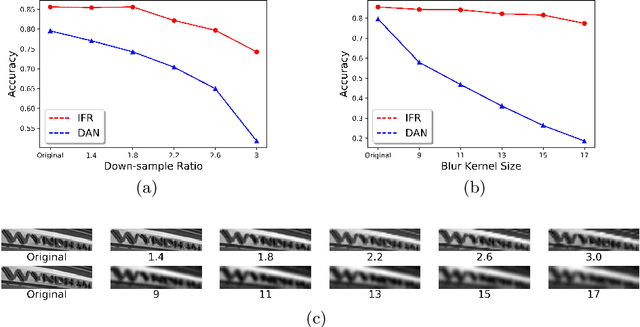
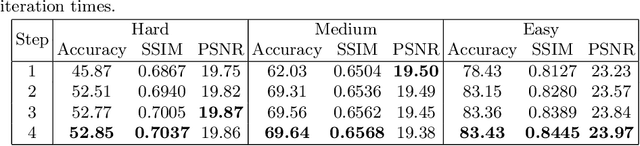


Although recent works based on deep learning have made progress in improving recognition accuracy on scene text recognition, how to handle low-quality text images in end-to-end deep networks remains a research challenge. In this paper, we propose an Iterative Fusion based Recognizer (IFR) for low quality scene text recognition, taking advantage of refined text images input and robust feature representation. IFR contains two branches which focus on scene text recognition and low quality scene text image recovery respectively. We utilize an iterative collaboration between two branches, which can effectively alleviate the impact of low quality input. A feature fusion module is proposed to strengthen the feature representation of the two branches, where the features from the Recognizer are Fused with image Restoration branch, referred to as RRF. Without changing the recognition network structure, extensive quantitative and qualitative experimental results show that the proposed method significantly outperforms the baseline methods in boosting the recognition accuracy of benchmark datasets and low resolution images in TextZoom dataset.