 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVitalDiagnosis: AI-Driven Ecosystem for 24/7 Vital Monitoring and Chronic Disease Management
Jan 22, 2026Chronic diseases have become the leading cause of death worldwide, a challenge intensified by strained medical resources and an aging population. Individually, patients often struggle to interpret early signs of deterioration or maintain adherence to care plans. In this paper, we introduce VitalDiagnosis, an LLM-driven ecosystem designed to shift chronic disease management from passive monitoring to proactive, interactive engagement. By integrating continuous data from wearable devices with the reasoning capabilities of LLMs, the system addresses both acute health anomalies and routine adherence. It analyzes triggers through context-aware inquiries, produces provisional insights within a collaborative patient-clinician workflow, and offers personalized guidance. This approach aims to promote a more proactive and cooperative care paradigm, with the potential to enhance patient self-management and reduce avoidable clinical workload.
Human-in-the-Loop Interactive Report Generation for Chronic Disease Adherence
Jan 10, 2026Chronic disease management requires regular adherence feedback to prevent avoidable hospitalizations, yet clinicians lack time to produce personalized patient communications. Manual authoring preserves clinical accuracy but does not scale; AI generation scales but can undermine trust in patient-facing contexts. We present a clinician-in-the-loop interface that constrains AI to data organization and preserves physician oversight through recognition-based review. A single-page editor pairs AI-generated section drafts with time-aligned visualizations, enabling inline editing with visual evidence for each claim. This division of labor (AI organizes, clinician decides) targets both efficiency and accountability. In a pilot with three physicians reviewing 24 cases, AI successfully generated clinically personalized drafts matching physicians' manual authoring practice (overall mean 4.86/10 vs. 5.0/10 baseline), requiring minimal physician editing (mean 8.3\% content modification) with zero safety-critical issues, demonstrating effective automation of content generation. However, review time remained comparable to manual practice, revealing an accountability paradox: in high-stakes clinical contexts, professional responsibility requires complete verification regardless of AI accuracy. We contribute three interaction patterns for clinical AI collaboration: bounded generation with recognition-based review via chart-text pairing, automated urgency flagging that analyzes vital trends and adherence patterns with fail-safe escalation for missed critical monitoring tasks, and progressive disclosure controls that reduce cognitive load while maintaining oversight. These patterns indicate that clinical AI efficiency requires not only accurate models, but also mechanisms for selective verification that preserve accountability.
SERL: Self-Examining Reinforcement Learning on Open-Domain
Nov 18, 2025Reinforcement Learning (RL) has been shown to improve the capabilities of large language models (LLMs). However, applying RL to open-domain tasks faces two key challenges: (1) the inherent subjectivity of these tasks prevents the verifiable rewards as required by Reinforcement Learning with Verifiable Rewards (RLVR); (2) Reinforcement Learning from Human Feedback (RLHF) relies on external reward mechanisms. To overcome these limitations, we propose Self-Examining Reinforcement Learning (SERL), a novel self-improving framework where the LLM serves as both Actor and Judge. SERL introduces two synergistic reward mechanisms without any external signals. On the one hand, to improve the Actor's capability, we derive rewards from Copeland-style pairwise comparison judgments across a group of generated responses. On the other hand, a self-consistency reward that encourages coherent judgments is proposed to improve the Judge's reliability. This process refines the Judge's capability, which in turn provides a more robust reward for Actor. Experiments show that our method outperforms existing self-improvement training methods. SERL improves the LC win rate of Qwen3-8B on AlpacaEval 2 from 52.37% to 59.90%. To the best of our knowledge, our method achieves state-of-the-art performance among self-improving approaches. Furthermore, it achieves a performance comparable to significantly larger models like Qwen3-32B, demonstrating superior effectiveness and robustness on open-domain tasks.
LangGFM: A Large Language Model Alone Can be a Powerful Graph Foundation Model
Oct 19, 2024
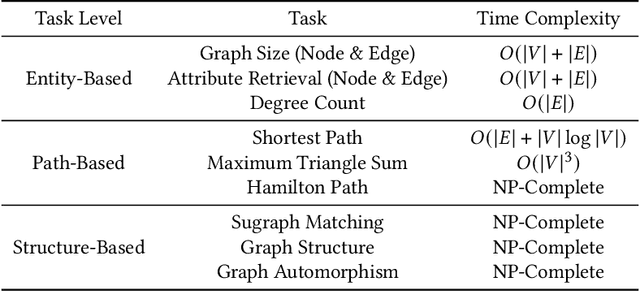

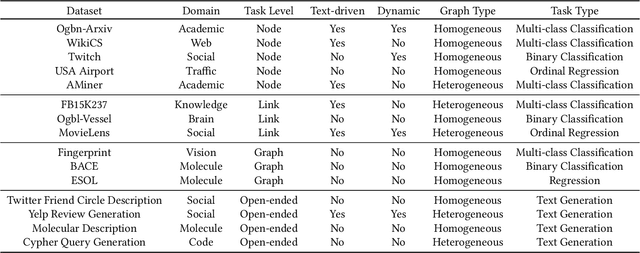
Graph foundation models (GFMs) have recently gained significant attention. However, the unique data processing and evaluation setups employed by different studies hinder a deeper understanding of their progress. Additionally, current research tends to focus on specific subsets of graph learning tasks, such as structural tasks, node-level tasks, or classification tasks. As a result, they often incorporate specialized modules tailored to particular task types, losing their applicability to other graph learning tasks and contradicting the original intent of foundation models to be universal. Therefore, to enhance consistency, coverage, and diversity across domains, tasks, and research interests within the graph learning community in the evaluation of GFMs, we propose GFMBench-a systematic and comprehensive benchmark comprising 26 datasets. Moreover, we introduce LangGFM, a novel GFM that relies entirely on large language models. By revisiting and exploring the effective graph textualization principles, as well as repurposing successful techniques from graph augmentation and graph self-supervised learning within the language space, LangGFM achieves performance on par with or exceeding the state of the art across GFMBench, which can offer us new perspectives, experiences, and baselines to drive forward the evolution of GFMs.
Can Large Language Models Grasp Legal Theories? Enhance Legal Reasoning with Insights from Multi-Agent Collaboration
Oct 03, 2024
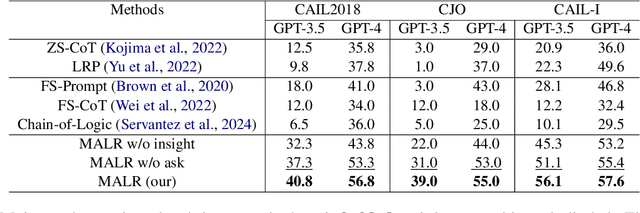

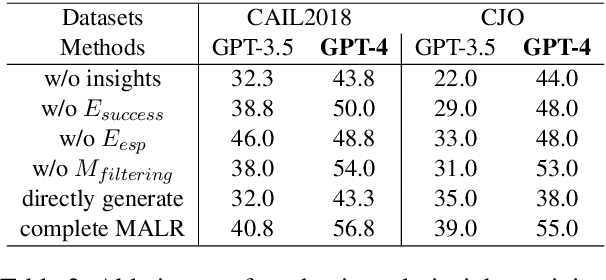
Large Language Models (LLMs) could struggle to fully understand legal theories and perform complex legal reasoning tasks. In this study, we introduce a challenging task (confusing charge prediction) to better evaluate LLMs' understanding of legal theories and reasoning capabilities. We also propose a novel framework: Multi-Agent framework for improving complex Legal Reasoning capability (MALR). MALR employs non-parametric learning, encouraging LLMs to automatically decompose complex legal tasks and mimic human learning process to extract insights from legal rules, helping LLMs better understand legal theories and enhance their legal reasoning abilities. Extensive experiments on multiple real-world datasets demonstrate that the proposed framework effectively addresses complex reasoning issues in practical scenarios, paving the way for more reliable applications in the legal domain.
Empowering Dual-Level Graph Self-Supervised Pretraining with Motif Discovery
Dec 19, 2023

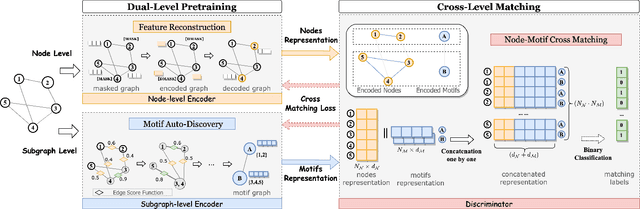
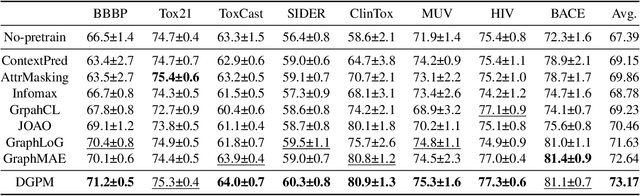
While self-supervised graph pretraining techniques have shown promising results in various domains, their application still experiences challenges of limited topology learning, human knowledge dependency, and incompetent multi-level interactions. To address these issues, we propose a novel solution, Dual-level Graph self-supervised Pretraining with Motif discovery (DGPM), which introduces a unique dual-level pretraining structure that orchestrates node-level and subgraph-level pretext tasks. Unlike prior approaches, DGPM autonomously uncovers significant graph motifs through an edge pooling module, aligning learned motif similarities with graph kernel-based similarities. A cross-matching task enables sophisticated node-motif interactions and novel representation learning. Extensive experiments on 15 datasets validate DGPM's effectiveness and generalizability, outperforming state-of-the-art methods in unsupervised representation learning and transfer learning settings. The autonomously discovered motifs demonstrate the potential of DGPM to enhance robustness and interpretability.