 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Split: Incentivizing Dual-Mode Exploration in LLM Reinforcement with Dual-Mode Entropy Regularization
Apr 13, 2026To encourage diverse exploration in reinforcement learning (RL) for large language models (LLMs) without compromising accuracy, we propose Policy Split, a novel paradigm that bifurcates the policy into normal and high-entropy modes with a high-entropy prompt. While sharing model parameters, the two modes undergo collaborative dual-mode entropy regularization tailored to distinct objectives. Specifically, the normal mode optimizes for task correctness, while the high-entropy mode incorporates a preference for exploration, and the two modes learn collaboratively. Extensive experiments demonstrate that our approach consistently outperforms established entropy-guided RL baselines across various model sizes in general and creative tasks. Further analysis reveals that Policy Split facilitates dual-mode exploration, where the high-entropy mode generates distinct behavioral patterns to the normal mode, providing unique learning signals.
Echo: Towards Advanced Audio Comprehension via Audio-Interleaved Reasoning
Feb 12, 2026The maturation of Large Audio Language Models (LALMs) has raised growing expectations for them to comprehend complex audio much like humans. Current efforts primarily replicate text-based reasoning by contextualizing audio content through a one-time encoding, which introduces a critical information bottleneck. Drawing inspiration from human cognition, we propose audio-interleaved reasoning to break through this bottleneck. It treats audio as an active reasoning component, enabling sustained audio engagement and perception-grounded analysis. To instantiate it, we introduce a two-stage training framework, first teaching LALMs to localize salient audio segments through supervised fine-tuning, and then incentivizing proficient re-listening via reinforcement learning. In parallel, a structured data generation pipeline is developed to produce high-quality training data. Consequently, we present Echo, a LALM capable of dynamically re-listening to audio in demand during reasoning. On audio comprehension benchmarks, Echo achieves overall superiority in both challenging expert-level and general-purpose tasks. Comprehensive analysis further confirms the efficiency and generalizability of audio-interleaved reasoning, establishing it as a promising direction for advancing audio comprehension. Project page: https://github.com/wdqqdw/Echo.
SIFThinker: Spatially-Aware Image Focus for Visual Reasoning
Aug 08, 2025Current multimodal large language models (MLLMs) still face significant challenges in complex visual tasks (e.g., spatial understanding, fine-grained perception). Prior methods have tried to incorporate visual reasoning, however, they fail to leverage attention correction with spatial cues to iteratively refine their focus on prompt-relevant regions. In this paper, we introduce SIFThinker, a spatially-aware "think-with-images" framework that mimics human visual perception. Specifically, SIFThinker enables attention correcting and image region focusing by interleaving depth-enhanced bounding boxes and natural language. Our contributions are twofold: First, we introduce a reverse-expansion-forward-inference strategy that facilitates the generation of interleaved image-text chains of thought for process-level supervision, which in turn leads to the construction of the SIF-50K dataset. Besides, we propose GRPO-SIF, a reinforced training paradigm that integrates depth-informed visual grounding into a unified reasoning pipeline, teaching the model to dynamically correct and focus on prompt-relevant regions. Extensive experiments demonstrate that SIFThinker outperforms state-of-the-art methods in spatial understanding and fine-grained visual perception, while maintaining strong general capabilities, highlighting the effectiveness of our method.
ListConRanker: A Contrastive Text Reranker with Listwise Encoding
Jan 13, 2025



Reranker models aim to re-rank the passages based on the semantics similarity between the given query and passages, which have recently received more attention due to the wide application of the Retrieval-Augmented Generation. Most previous methods apply pointwise encoding, meaning that it can only encode the context of the query for each passage input into the model. However, for the reranker model, given a query, the comparison results between passages are even more important, which is called listwise encoding. Besides, previous models are trained using the cross-entropy loss function, which leads to issues of unsmooth gradient changes during training and low training efficiency. To address these issues, we propose a novel Listwise-encoded Contrastive text reRanker (ListConRanker). It can help the passage to be compared with other passages during the encoding process, and enhance the contrastive information between positive examples and between positive and negative examples. At the same time, we use the circle loss to train the model to increase the flexibility of gradients and solve the problem of training efficiency. Experimental results show that ListConRanker achieves state-of-the-art performance on the reranking benchmark of Chinese Massive Text Embedding Benchmark, including the cMedQA1.0, cMedQA2.0, MMarcoReranking, and T2Reranking datasets.
Efficient and Accurate Prompt Optimization: the Benefit of Memory in Exemplar-Guided Reflection
Nov 12, 2024



Automatic prompt engineering aims to enhance the generation quality of large language models (LLMs). Recent works utilize feedbacks generated from erroneous cases to guide the prompt optimization. During inference, they may further retrieve several semantically-related exemplars and concatenate them to the optimized prompts to improve the performance. However, those works only utilize the feedback at the current step, ignoring historical and unseleccted feedbacks which are potentially beneficial. Moreover, the selection of exemplars only considers the general semantic relationship and may not be optimal in terms of task performance and matching with the optimized prompt. In this work, we propose an Exemplar-Guided Reflection with Memory mechanism (ERM) to realize more efficient and accurate prompt optimization. Specifically, we design an exemplar-guided reflection mechanism where the feedback generation is additionally guided by the generated exemplars. We further build two kinds of memory to fully utilize the historical feedback information and support more effective exemplar retrieval. Empirical evaluations show our method surpasses previous state-of-the-arts with less optimization steps, i.e., improving F1 score by 10.1 on LIAR dataset, and reducing half of the optimization steps on ProTeGi.
LangGFM: A Large Language Model Alone Can be a Powerful Graph Foundation Model
Oct 19, 2024
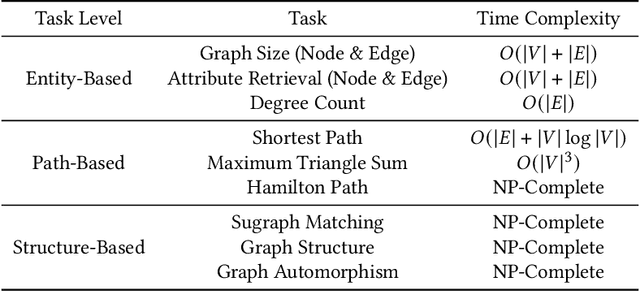

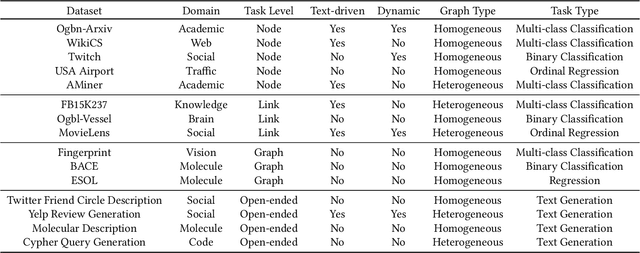
Graph foundation models (GFMs) have recently gained significant attention. However, the unique data processing and evaluation setups employed by different studies hinder a deeper understanding of their progress. Additionally, current research tends to focus on specific subsets of graph learning tasks, such as structural tasks, node-level tasks, or classification tasks. As a result, they often incorporate specialized modules tailored to particular task types, losing their applicability to other graph learning tasks and contradicting the original intent of foundation models to be universal. Therefore, to enhance consistency, coverage, and diversity across domains, tasks, and research interests within the graph learning community in the evaluation of GFMs, we propose GFMBench-a systematic and comprehensive benchmark comprising 26 datasets. Moreover, we introduce LangGFM, a novel GFM that relies entirely on large language models. By revisiting and exploring the effective graph textualization principles, as well as repurposing successful techniques from graph augmentation and graph self-supervised learning within the language space, LangGFM achieves performance on par with or exceeding the state of the art across GFMBench, which can offer us new perspectives, experiences, and baselines to drive forward the evolution of GFMs.
A Speaker Turn-Aware Multi-Task Adversarial Network for Joint User Satisfaction Estimation and Sentiment Analysis
Oct 12, 2024



User Satisfaction Estimation is an important task and increasingly being applied in goal-oriented dialogue systems to estimate whether the user is satisfied with the service. It is observed that whether the user's needs are met often triggers various sentiments, which can be pertinent to the successful estimation of user satisfaction, and vice versa. Thus, User Satisfaction Estimation (USE) and Sentiment Analysis (SA) should be treated as a joint, collaborative effort, considering the strong connections between the sentiment states of speakers and the user satisfaction. Existing joint learning frameworks mainly unify the two highly pertinent tasks over cascade or shared-bottom implementations, however they fail to distinguish task-specific and common features, which will produce sub-optimal utterance representations for downstream tasks. In this paper, we propose a novel Speaker Turn-Aware Multi-Task Adversarial Network (STMAN) for dialogue-level USE and utterance-level SA. Specifically, we first introduce a multi-task adversarial strategy which trains a task discriminator to make utterance representation more task-specific, and then utilize a speaker-turn aware multi-task interaction strategy to extract the common features which are complementary to each task. Extensive experiments conducted on two real-world service dialogue datasets show that our model outperforms several state-of-the-art methods.
Can Large Language Models Grasp Legal Theories? Enhance Legal Reasoning with Insights from Multi-Agent Collaboration
Oct 03, 2024
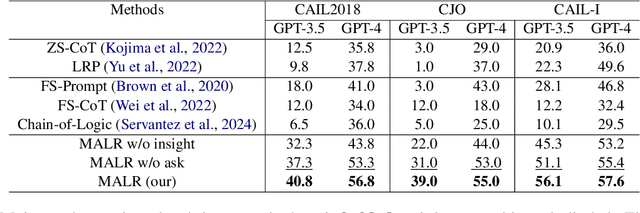

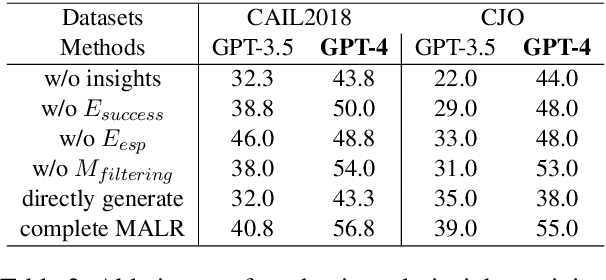
Large Language Models (LLMs) could struggle to fully understand legal theories and perform complex legal reasoning tasks. In this study, we introduce a challenging task (confusing charge prediction) to better evaluate LLMs' understanding of legal theories and reasoning capabilities. We also propose a novel framework: Multi-Agent framework for improving complex Legal Reasoning capability (MALR). MALR employs non-parametric learning, encouraging LLMs to automatically decompose complex legal tasks and mimic human learning process to extract insights from legal rules, helping LLMs better understand legal theories and enhance their legal reasoning abilities. Extensive experiments on multiple real-world datasets demonstrate that the proposed framework effectively addresses complex reasoning issues in practical scenarios, paving the way for more reliable applications in the legal domain.
Gold Panning in Vocabulary: An Adaptive Method for Vocabulary Expansion of Domain-Specific LLMs
Oct 02, 2024



While Large Language Models (LLMs) demonstrate impressive generation abilities, they frequently struggle when it comes to specialized domains due to their limited domain-specific knowledge. Studies on domain-specific LLMs resort to expanding the vocabulary before fine-tuning on domain-specific corpus, aiming to decrease the sequence length and enhance efficiency during decoding, without thoroughly investigating the results of vocabulary expansion to LLMs over different domains. Our pilot study reveals that expansion with only a subset of the entire vocabulary may lead to superior performance. Guided by the discovery, this paper explores how to identify a vocabulary subset to achieve the optimal results. We introduce VEGAD, an adaptive method that automatically identifies valuable words from a given domain vocabulary. Our method has been validated through experiments on three Chinese datasets, demonstrating its effectiveness. Additionally, we have undertaken comprehensive analyses of the method. The selection of a optimal subset for expansion has shown to enhance performance on both domain-specific tasks and general tasks, showcasing the potential of VEGAD.
RexUniNLU: Recursive Method with Explicit Schema Instructor for Universal NLU
Sep 09, 2024
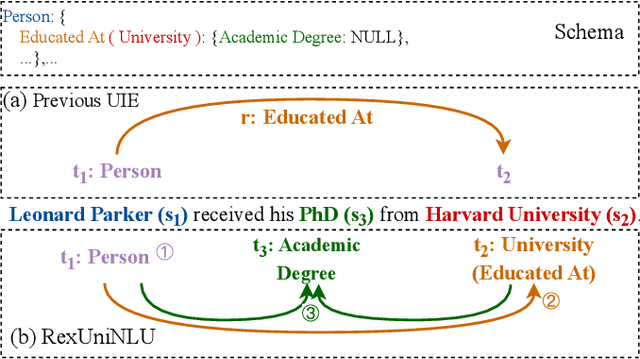
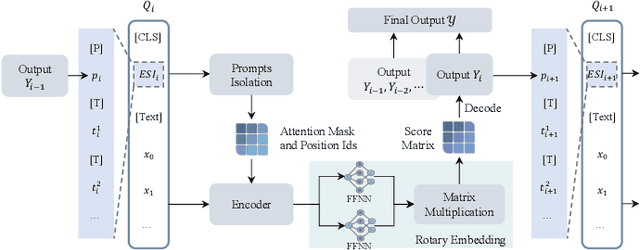
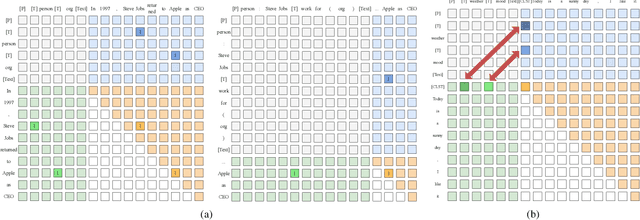
Information Extraction (IE) and Text Classification (CLS) serve as the fundamental pillars of NLU, with both disciplines relying on analyzing input sequences to categorize outputs into pre-established schemas. However, there is no existing encoder-based model that can unify IE and CLS tasks from this perspective. To fully explore the foundation shared within NLU tasks, we have proposed a Recursive Method with Explicit Schema Instructor for Universal NLU. Specifically, we firstly redefine the true universal information extraction (UIE) with a formal formulation that covers almost all extraction schemas, including quadruples and quintuples which remain unsolved for previous UIE models. Then, we expands the formulation to all CLS and multi-modal NLU tasks. Based on that, we introduce RexUniNLU, an universal NLU solution that employs explicit schema constraints for IE and CLS, which encompasses all IE and CLS tasks and prevent incorrect connections between schema and input sequence. To avoid interference between different schemas, we reset the position ids and attention mask matrices. Extensive experiments are conducted on IE, CLS in both English and Chinese, and multi-modality, revealing the effectiveness and superiority. Our codes are publicly released.