 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRexUniNLU: Recursive Method with Explicit Schema Instructor for Universal NLU
Sep 09, 2024
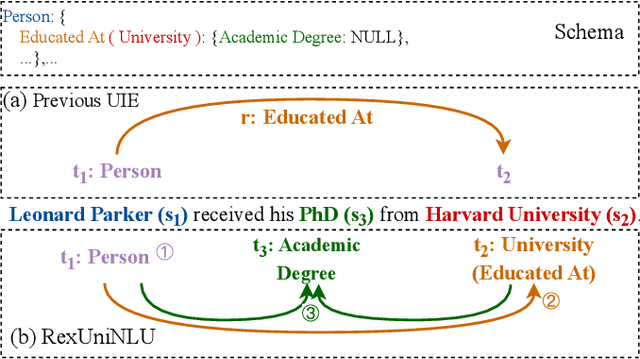
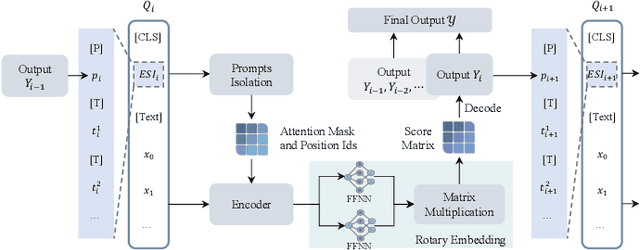
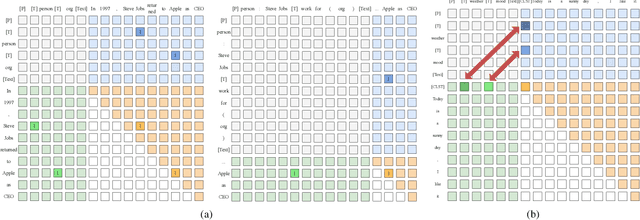
Information Extraction (IE) and Text Classification (CLS) serve as the fundamental pillars of NLU, with both disciplines relying on analyzing input sequences to categorize outputs into pre-established schemas. However, there is no existing encoder-based model that can unify IE and CLS tasks from this perspective. To fully explore the foundation shared within NLU tasks, we have proposed a Recursive Method with Explicit Schema Instructor for Universal NLU. Specifically, we firstly redefine the true universal information extraction (UIE) with a formal formulation that covers almost all extraction schemas, including quadruples and quintuples which remain unsolved for previous UIE models. Then, we expands the formulation to all CLS and multi-modal NLU tasks. Based on that, we introduce RexUniNLU, an universal NLU solution that employs explicit schema constraints for IE and CLS, which encompasses all IE and CLS tasks and prevent incorrect connections between schema and input sequence. To avoid interference between different schemas, we reset the position ids and attention mask matrices. Extensive experiments are conducted on IE, CLS in both English and Chinese, and multi-modality, revealing the effectiveness and superiority. Our codes are publicly released.
More Than Catastrophic Forgetting: Integrating General Capabilities For Domain-Specific LLMs
May 28, 2024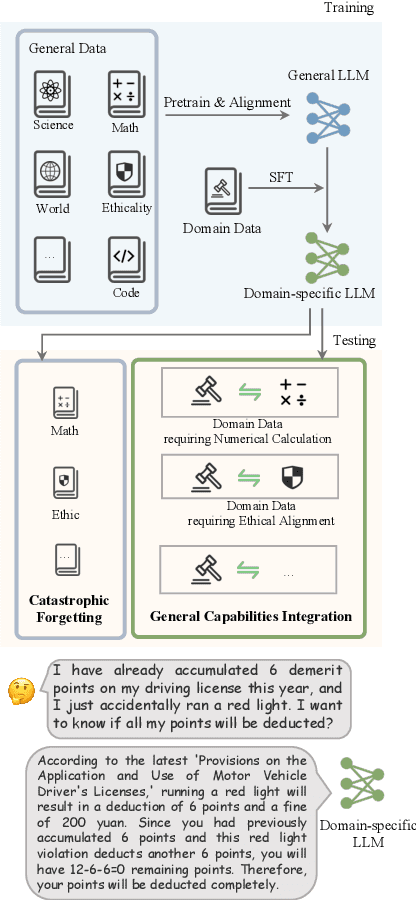


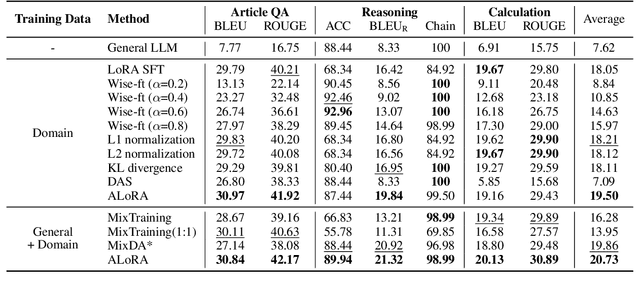
The performance on general tasks decreases after Large Language Models (LLMs) are fine-tuned on domain-specific tasks, the phenomenon is known as Catastrophic Forgetting (CF). However, this paper presents a further challenge for real application of domain-specific LLMs beyond CF, called General Capabilities Integration (GCI), which necessitates the integration of both the general capabilities and domain knowledge within a single instance. The objective of GCI is not merely to retain previously acquired general capabilities alongside new domain knowledge, but to harmonize and utilize both sets of skills in a cohesive manner to enhance performance on domain-specific tasks. Taking legal domain as an example, we carefully design three groups of training and testing tasks without lacking practicability, and construct the corresponding datasets. To better incorporate general capabilities across domain-specific scenarios, we introduce ALoRA, which utilizes a multi-head attention module upon LoRA, facilitating direct information transfer from preceding tokens to the current one. This enhancement permits the representation to dynamically switch between domain-specific knowledge and general competencies according to the attention. Extensive experiments are conducted on the proposed tasks. The results exhibit the significance of our setting, and the effectiveness of our method.
Evolving Knowledge Distillation with Large Language Models and Active Learning
Mar 11, 2024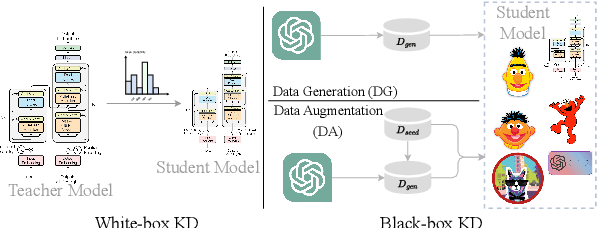
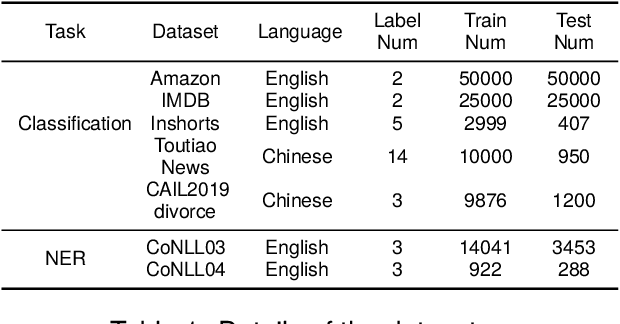

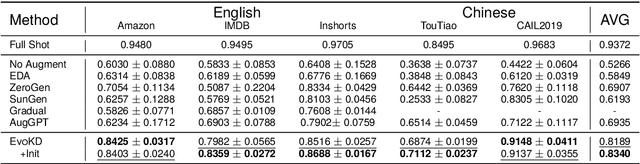
Large language models (LLMs) have demonstrated remarkable capabilities across various NLP tasks. However, their computational costs are prohibitively high. To address this issue, previous research has attempted to distill the knowledge of LLMs into smaller models by generating annotated data. Nonetheless, these works have mainly focused on the direct use of LLMs for text generation and labeling, without fully exploring their potential to comprehend the target task and acquire valuable knowledge. In this paper, we propose EvoKD: Evolving Knowledge Distillation, which leverages the concept of active learning to interactively enhance the process of data generation using large language models, simultaneously improving the task capabilities of small domain model (student model). Different from previous work, we actively analyze the student model's weaknesses, and then synthesize labeled samples based on the analysis. In addition, we provide iterative feedback to the LLMs regarding the student model's performance to continuously construct diversified and challenging samples. Experiments and analysis on different NLP tasks, namely, text classification and named entity recognition show the effectiveness of EvoKD.
Memory-Augmented LLM Personalization with Short- and Long-Term Memory Coordination
Sep 28, 2023Large Language Models (LLMs), such as GPT3.5, have exhibited remarkable proficiency in comprehending and generating natural language. However, their unpersonalized generation paradigm may result in suboptimal user-specific outcomes. Typically, users converse differently based on their knowledge and preferences. This necessitates the task of enhancing user-oriented LLM which remains unexplored. While one can fully train an LLM for this objective, the resource consumption is unaffordable. Prior research has explored memory-based methods to store and retrieve knowledge to enhance generation without retraining for new queries. However, we contend that a mere memory module is inadequate to comprehend a user's preference, and fully training an LLM can be excessively costly. In this study, we propose a novel computational bionic memory mechanism, equipped with a parameter-efficient fine-tuning schema, to personalize LLMs. Our extensive experimental results demonstrate the effectiveness and superiority of the proposed approach. To encourage further research into this area, we are releasing a new conversation dataset generated entirely by LLM based on an open-source medical corpus, as well as our implementation code.
A Chinese Prompt Attack Dataset for LLMs with Evil Content
Sep 21, 2023



Large Language Models (LLMs) present significant priority in text understanding and generation. However, LLMs suffer from the risk of generating harmful contents especially while being employed to applications. There are several black-box attack methods, such as Prompt Attack, which can change the behaviour of LLMs and induce LLMs to generate unexpected answers with harmful contents. Researchers are interested in Prompt Attack and Defense with LLMs, while there is no publicly available dataset to evaluate the abilities of defending prompt attack. In this paper, we introduce a Chinese Prompt Attack Dataset for LLMs, called CPAD. Our prompts aim to induce LLMs to generate unexpected outputs with several carefully designed prompt attack approaches and widely concerned attacking contents. Different from previous datasets involving safety estimation, We construct the prompts considering three dimensions: contents, attacking methods and goals, thus the responses can be easily evaluated and analysed. We run several well-known Chinese LLMs on our dataset, and the results show that our prompts are significantly harmful to LLMs, with around 70% attack success rate. We will release CPAD to encourage further studies on prompt attack and defense.
PPN: Parallel Pointer-based Network for Key Information Extraction with Complex Layouts
Jul 20, 2023Key Information Extraction (KIE) is a challenging multimodal task that aims to extract structured value semantic entities from visually rich documents. Although significant progress has been made, there are still two major challenges that need to be addressed. Firstly, the layout of existing datasets is relatively fixed and limited in the number of semantic entity categories, creating a significant gap between these datasets and the complex real-world scenarios. Secondly, existing methods follow a two-stage pipeline strategy, which may lead to the error propagation problem. Additionally, they are difficult to apply in situations where unseen semantic entity categories emerge. To address the first challenge, we propose a new large-scale human-annotated dataset named Complex Layout form for key information EXtraction (CLEX), which consists of 5,860 images with 1,162 semantic entity categories. To solve the second challenge, we introduce Parallel Pointer-based Network (PPN), an end-to-end model that can be applied in zero-shot and few-shot scenarios. PPN leverages the implicit clues between semantic entities to assist extracting, and its parallel extraction mechanism allows it to extract multiple results simultaneously and efficiently. Experiments on the CLEX dataset demonstrate that PPN outperforms existing state-of-the-art methods while also offering a much faster inference speed.
RexUIE: A Recursive Method with Explicit Schema Instructor for Universal Information Extraction
Apr 28, 2023Universal Information Extraction (UIE) is an area of interest due to the challenges posed by varying targets, heterogeneous structures, and demand-specific schemas. However, previous works have only achieved limited success by unifying a few tasks, such as Named Entity Recognition (NER) and Relation Extraction (RE), which fall short of being authentic UIE models particularly when extracting other general schemas such as quadruples and quintuples. Additionally, these models used an implicit structural schema instructor, which could lead to incorrect links between types, hindering the model's generalization and performance in low-resource scenarios. In this paper, we redefine the authentic UIE with a formal formulation that encompasses almost all extraction schemas. To the best of our knowledge, we are the first to introduce UIE for any kind of schemas. In addition, we propose RexUIE, which is a Recursive Method with Explicit Schema Instructor for UIE. To avoid interference between different types, we reset the position ids and attention mask matrices. RexUIE shows strong performance under both full-shot and few-shot settings and achieves State-of-the-Art results on the tasks of extracting complex schemas.
Adjacency List Oriented Relational Fact Extraction via Adaptive Multi-task Learning
Jun 03, 2021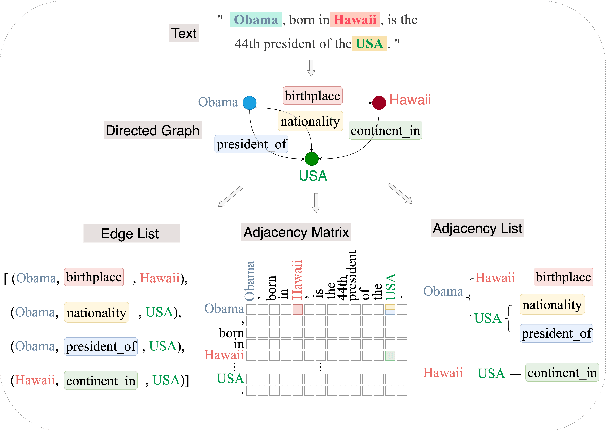
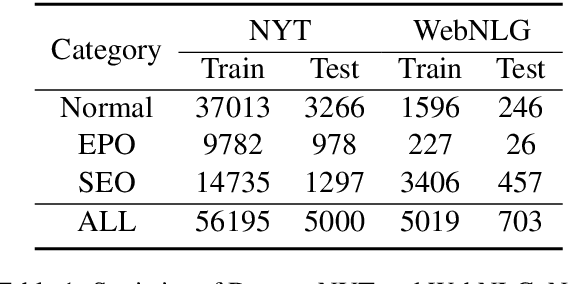
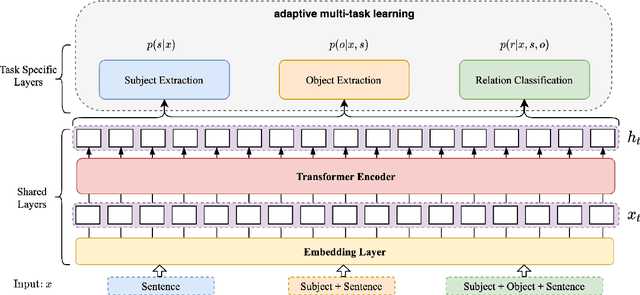

Relational fact extraction aims to extract semantic triplets from unstructured text. In this work, we show that all of the relational fact extraction models can be organized according to a graph-oriented analytical perspective. An efficient model, aDjacency lIst oRiented rElational faCT (DIRECT), is proposed based on this analytical framework. To alleviate challenges of error propagation and sub-task loss equilibrium, DIRECT employs a novel adaptive multi-task learning strategy with dynamic sub-task loss balancing. Extensive experiments are conducted on two benchmark datasets, and results prove that the proposed model outperforms a series of state-of-the-art (SoTA) models for relational triplet extraction.
Technical report on Conversational Question Answering
Sep 24, 2019
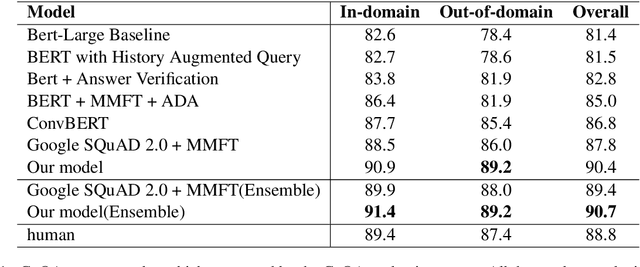
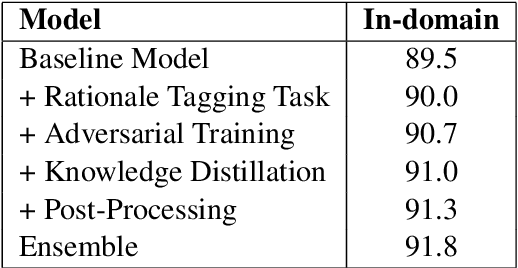
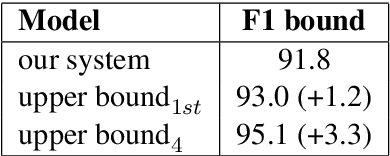
Conversational Question Answering is a challenging task since it requires understanding of conversational history. In this project, we propose a new system RoBERTa + AT +KD, which involves rationale tagging multi-task, adversarial training, knowledge distillation and a linguistic post-process strategy. Our single model achieves 90.4(F1) on the CoQA test set without data augmentation, outperforming the current state-of-the-art single model by 2.6% F1.