 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORGE: Fragment-Oriented Ranking and Generation for Context-Aware Molecular Optimization
May 11, 2026Molecular optimization seeks to improve a molecule through small structural edits while preserving similarity to the starting compound. Recent language-model approaches typically treat this task as prompt-conditioned sequence generation. However, relying on natural language introduces an inherent data-scaling bottleneck, often leads to chemical hallucinations, and ignores the strong context dependence of fragment effects. We present FORGE, a two-stage framework that reformulates molecular optimization as context-aware local editing. By utilizing automatically mined, verified low-to-high edit pairs instead of expensive human text annotations, Stage 1 ranks candidate fragments by their property contribution under the full molecular context to inject chemical prior, and Stage 2 generates explicit fragment replacements. Built on a compact 0.6B language model, FORGE further adapts to unseen black-box objectives through in-context demonstrations. Across Prompt-MolOpt, PMO-1k and ChemCoTBench, FORGE consistently outperforms prior methods, including substantially larger language models and graph methods. These results highlight the value of explicit fragment-level supervision as a more easily obtainable, scalable, and hallucination-less alternative to natural language training.
VimRAG: Navigating Massive Visual Context in Retrieval-Augmented Generation via Multimodal Memory Graph
Feb 13, 2026Effectively retrieving, reasoning, and understanding multimodal information remains a critical challenge for agentic systems. Traditional Retrieval-augmented Generation (RAG) methods rely on linear interaction histories, which struggle to handle long-context tasks, especially those involving information-sparse yet token-heavy visual data in iterative reasoning scenarios. To bridge this gap, we introduce VimRAG, a framework tailored for multimodal Retrieval-augmented Reasoning across text, images, and videos. Inspired by our systematic study, we model the reasoning process as a dynamic directed acyclic graph that structures the agent states and retrieved multimodal evidence. Building upon this structured memory, we introduce a Graph-Modulated Visual Memory Encoding mechanism, with which the significance of memory nodes is evaluated via their topological position, allowing the model to dynamically allocate high-resolution tokens to pivotal evidence while compressing or discarding trivial clues. To implement this paradigm, we propose a Graph-Guided Policy Optimization strategy. This strategy disentangles step-wise validity from trajectory-level rewards by pruning memory nodes associated with redundant actions, thereby facilitating fine-grained credit assignment. Extensive experiments demonstrate that VimRAG consistently achieves state-of-the-art performance on diverse multimodal RAG benchmarks. The code is available at https://github.com/Alibaba-NLP/VRAG.
ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking
Jan 10, 2026Reinforcement learning has substantially improved the performance of LLM agents on tasks with verifiable outcomes, but it still struggles on open-ended agent tasks with vast solution spaces (e.g., complex travel planning). Due to the absence of objective ground-truth for these tasks, current RL algorithms largely rely on reward models that assign scalar scores to individual responses. We contend that such pointwise scoring suffers from an inherent discrimination collapse: the reward model struggles to distinguish subtle advantages among different trajectories, resulting in scores within a group being compressed into a narrow range. Consequently, the effective reward signal becomes dominated by noise from the reward model, leading to optimization stagnation. To address this, we propose ArenaRL, a reinforcement learning paradigm that shifts from pointwise scalar scoring to intra-group relative ranking. ArenaRL introduces a process-aware pairwise evaluation mechanism, employing multi-level rubrics to assign fine-grained relative scores to trajectories. Additionally, we construct an intra-group adversarial arena and devise a tournament-based ranking scheme to obtain stable advantage signals. Empirical results confirm that the built seeded single-elimination scheme achieves nearly equivalent advantage estimation accuracy to full pairwise comparisons with O(N^2) complexity, while operating with only O(N) complexity, striking an optimal balance between efficiency and precision. Furthermore, to address the lack of full-cycle benchmarks for open-ended agents, we build Open-Travel and Open-DeepResearch, two high-quality benchmarks featuring a comprehensive pipeline covering SFT, RL training, and multi-dimensional evaluation. Extensive experiments show that ArenaRL substantially outperforms standard RL baselines, enabling LLM agents to generate more robust solutions for complex real-world tasks.
Learn More, Forget Less: A Gradient-Aware Data Selection Approach for LLM
Nov 07, 2025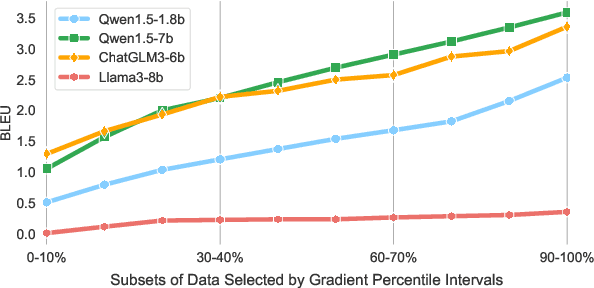
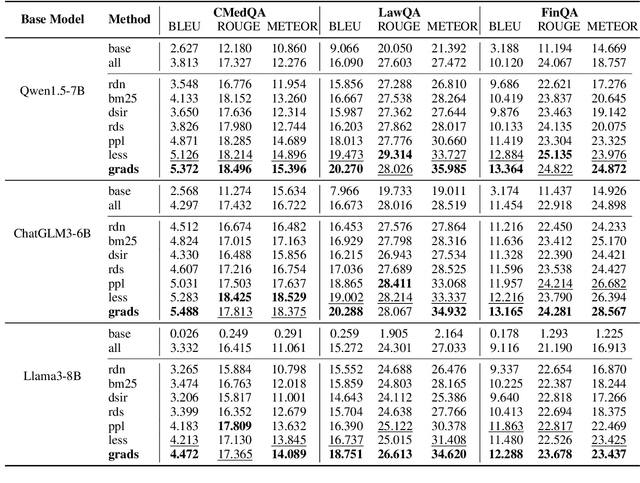
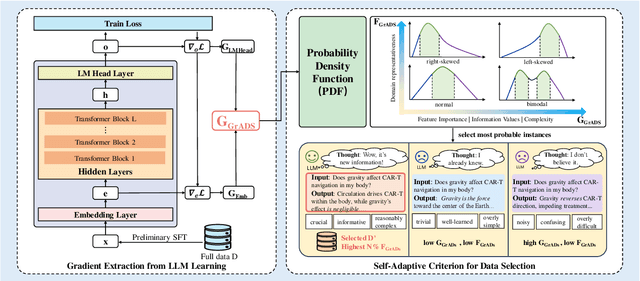
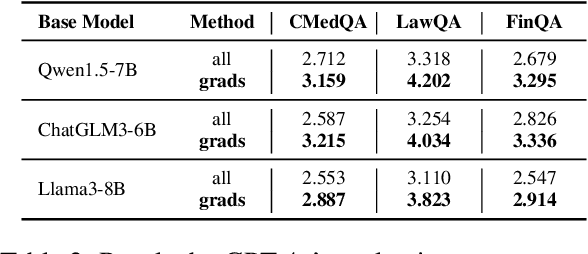
Despite large language models (LLMs) have achieved impressive achievements across numerous tasks, supervised fine-tuning (SFT) remains essential for adapting these models to specialized domains. However, SFT for domain specialization can be resource-intensive and sometimes leads to a deterioration in performance over general capabilities due to catastrophic forgetting (CF). To address these issues, we propose a self-adaptive gradient-aware data selection approach (GrADS) for supervised fine-tuning of LLMs, which identifies effective subsets of training data by analyzing gradients obtained from a preliminary training phase. Specifically, we design self-guided criteria that leverage the magnitude and statistical distribution of gradients to prioritize examples that contribute the most to the model's learning process. This approach enables the acquisition of representative samples that enhance LLMs understanding of domain-specific tasks. Through extensive experimentation with various LLMs across diverse domains such as medicine, law, and finance, GrADS has demonstrated significant efficiency and cost-effectiveness. Remarkably, utilizing merely 5% of the selected GrADS data, LLMs already surpass the performance of those fine-tuned on the entire dataset, and increasing to 50% of the data results in significant improvements! With catastrophic forgetting substantially mitigated simultaneously. We will release our code for GrADS later.
VRAG-RL: Empower Vision-Perception-Based RAG for Visually Rich Information Understanding via Iterative Reasoning with Reinforcement Learning
May 28, 2025Effectively retrieving, reasoning and understanding visually rich information remains a challenge for RAG methods. Traditional text-based methods cannot handle visual-related information. On the other hand, current vision-based RAG approaches are often limited by fixed pipelines and frequently struggle to reason effectively due to the insufficient activation of the fundamental capabilities of models. As RL has been proven to be beneficial for model reasoning, we introduce VRAG-RL, a novel RL framework tailored for complex reasoning across visually rich information. With this framework, VLMs interact with search engines, autonomously sampling single-turn or multi-turn reasoning trajectories with the help of visual perception tokens and undergoing continual optimization based on these samples. Our approach highlights key limitations of RL in RAG domains: (i) Prior Multi-modal RAG approaches tend to merely incorporate images into the context, leading to insufficient reasoning token allocation and neglecting visual-specific perception; and (ii) When models interact with search engines, their queries often fail to retrieve relevant information due to the inability to articulate requirements, thereby leading to suboptimal performance. To address these challenges, we define an action space tailored for visually rich inputs, with actions including cropping and scaling, allowing the model to gather information from a coarse-to-fine perspective. Furthermore, to bridge the gap between users' original inquiries and the retriever, we employ a simple yet effective reward that integrates query rewriting and retrieval performance with a model-based reward. Our VRAG-RL optimizes VLMs for RAG tasks using specially designed RL strategies, aligning the model with real-world applications. The code is available at \hyperlink{https://github.com/Alibaba-NLP/VRAG}{https://github.com/Alibaba-NLP/VRAG}.
Towards Stepwise Domain Knowledge-Driven Reasoning Optimization and Reflection Improvement
Apr 12, 2025
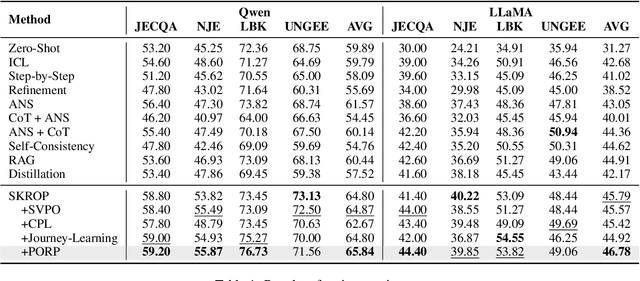
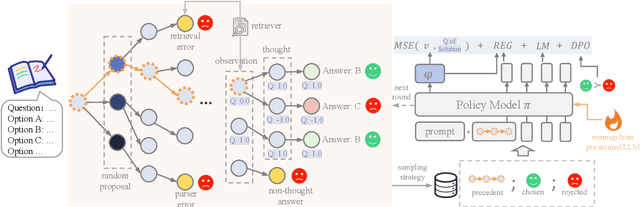
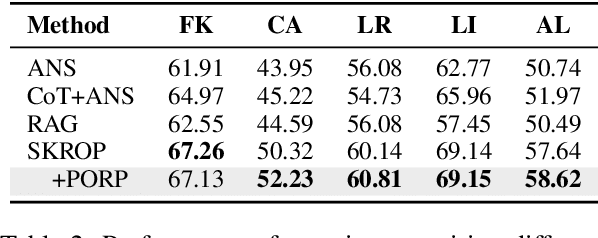
Recently, stepwise supervision on Chain of Thoughts (CoTs) presents an enhancement on the logical reasoning tasks such as coding and math, with the help of Monte Carlo Tree Search (MCTS). However, its contribution to tasks requiring domain-specific expertise and knowledge remains unexplored. Motivated by the interest, we identify several potential challenges of vanilla MCTS within this context, and propose the framework of Stepwise Domain Knowledge-Driven Reasoning Optimization, employing the MCTS algorithm to develop step-level supervision for problems that require essential comprehension, reasoning, and specialized knowledge. Additionally, we also introduce the Preference Optimization towards Reflection Paths, which iteratively learns self-reflection on the reasoning thoughts from better perspectives. We have conducted extensive experiments to evaluate the advantage of the methodologies. Empirical results demonstrate the effectiveness on various legal-domain problems. We also report a diverse set of valuable findings, hoping to encourage the enthusiasm to the research of domain-specific LLMs and MCTS.
PhenoProfiler: Advancing Phenotypic Learning for Image-based Drug Discovery
Feb 26, 2025In the field of image-based drug discovery, capturing the phenotypic response of cells to various drug treatments and perturbations is a crucial step. However, existing methods require computationally extensive and complex multi-step procedures, which can introduce inefficiencies, limit generalizability, and increase potential errors. To address these challenges, we present PhenoProfiler, an innovative model designed to efficiently and effectively extract morphological representations, enabling the elucidation of phenotypic changes induced by treatments. PhenoProfiler is designed as an end-to-end tool that processes whole-slide multi-channel images directly into low-dimensional quantitative representations, eliminating the extensive computational steps required by existing methods. It also includes a multi-objective learning module to enhance robustness, accuracy, and generalization in morphological representation learning. PhenoProfiler is rigorously evaluated on large-scale publicly available datasets, including over 230,000 whole-slide multi-channel images in end-to-end scenarios and more than 8.42 million single-cell images in non-end-to-end settings. Across these benchmarks, PhenoProfiler consistently outperforms state-of-the-art methods by up to 20%, demonstrating substantial improvements in both accuracy and robustness. Furthermore, PhenoProfiler uses a tailored phenotype correction strategy to emphasize relative phenotypic changes under treatments, facilitating the detection of biologically meaningful signals. UMAP visualizations of treatment profiles demonstrate PhenoProfiler ability to effectively cluster treatments with similar biological annotations, thereby enhancing interpretability. These findings establish PhenoProfiler as a scalable, generalizable, and robust tool for phenotypic learning.
ViDoRAG: Visual Document Retrieval-Augmented Generation via Dynamic Iterative Reasoning Agents
Feb 25, 2025



Understanding information from visually rich documents remains a significant challenge for traditional Retrieval-Augmented Generation (RAG) methods. Existing benchmarks predominantly focus on image-based question answering (QA), overlooking the fundamental challenges of efficient retrieval, comprehension, and reasoning within dense visual documents. To bridge this gap, we introduce ViDoSeek, a novel dataset designed to evaluate RAG performance on visually rich documents requiring complex reasoning. Based on it, we identify key limitations in current RAG approaches: (i) purely visual retrieval methods struggle to effectively integrate both textual and visual features, and (ii) previous approaches often allocate insufficient reasoning tokens, limiting their effectiveness. To address these challenges, we propose ViDoRAG, a novel multi-agent RAG framework tailored for complex reasoning across visual documents. ViDoRAG employs a Gaussian Mixture Model (GMM)-based hybrid strategy to effectively handle multi-modal retrieval. To further elicit the model's reasoning capabilities, we introduce an iterative agent workflow incorporating exploration, summarization, and reflection, providing a framework for investigating test-time scaling in RAG domains. Extensive experiments on ViDoSeek validate the effectiveness and generalization of our approach. Notably, ViDoRAG outperforms existing methods by over 10% on the competitive ViDoSeek benchmark.
Learning to Solve Domain-Specific Calculation Problems with Knowledge-Intensive Programs Generator
Dec 12, 2024Domain Large Language Models (LLMs) are developed for domain-specific tasks based on general LLMs. But it still requires professional knowledge to facilitate the expertise for some domain-specific tasks. In this paper, we investigate into knowledge-intensive calculation problems. We find that the math problems to be challenging for LLMs, when involving complex domain-specific rules and knowledge documents, rather than simple formulations of terminologies. Therefore, we propose a pipeline to solve the domain-specific calculation problems with Knowledge-Intensive Programs Generator more effectively, named as KIPG. It generates knowledge-intensive programs according to the domain-specific documents. For each query, key variables are extracted, then outcomes which are dependent on domain knowledge are calculated with the programs. By iterative preference alignment, the code generator learns to improve the logic consistency with the domain knowledge. Taking legal domain as an example, we have conducted experiments to prove the effectiveness of our pipeline, and extensive analysis on the modules. We also find that the code generator is also adaptable to other domains, without training on the new knowledge.
Gold Panning in Vocabulary: An Adaptive Method for Vocabulary Expansion of Domain-Specific LLMs
Oct 02, 2024



While Large Language Models (LLMs) demonstrate impressive generation abilities, they frequently struggle when it comes to specialized domains due to their limited domain-specific knowledge. Studies on domain-specific LLMs resort to expanding the vocabulary before fine-tuning on domain-specific corpus, aiming to decrease the sequence length and enhance efficiency during decoding, without thoroughly investigating the results of vocabulary expansion to LLMs over different domains. Our pilot study reveals that expansion with only a subset of the entire vocabulary may lead to superior performance. Guided by the discovery, this paper explores how to identify a vocabulary subset to achieve the optimal results. We introduce VEGAD, an adaptive method that automatically identifies valuable words from a given domain vocabulary. Our method has been validated through experiments on three Chinese datasets, demonstrating its effectiveness. Additionally, we have undertaken comprehensive analyses of the method. The selection of a optimal subset for expansion has shown to enhance performance on both domain-specific tasks and general tasks, showcasing the potential of VEGAD.