 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgescDrugMap: Benchmarking Large Foundation Models for Drug Response Prediction
May 08, 2025Drug resistance presents a major challenge in cancer therapy. Single cell profiling offers insights into cellular heterogeneity, yet the application of large-scale foundation models for predicting drug response in single cell data remains underexplored. To address this, we developed scDrugMap, an integrated framework featuring both a Python command-line interface and a web server for drug response prediction. scDrugMap evaluates a wide range of foundation models, including eight single-cell models and two large language models, using a curated dataset of over 326,000 cells in the primary collection and 18,800 cells in the validation set, spanning 36 datasets and diverse tissue and cancer types. We benchmarked model performance under pooled-data and cross-data evaluation settings, employing both layer freezing and Low-Rank Adaptation (LoRA) fine-tuning strategies. In the pooled-data scenario, scFoundation achieved the best performance, with mean F1 scores of 0.971 (layer freezing) and 0.947 (fine-tuning), outperforming the lowest-performing model by over 50%. In the cross-data setting, UCE excelled post fine-tuning (mean F1: 0.774), while scGPT led in zero-shot learning (mean F1: 0.858). Overall, scDrugMap provides the first large-scale benchmark of foundation models for drug response prediction in single-cell data and serves as a user-friendly, flexible platform for advancing drug discovery and translational research.
PhenoProfiler: Advancing Phenotypic Learning for Image-based Drug Discovery
Feb 26, 2025In the field of image-based drug discovery, capturing the phenotypic response of cells to various drug treatments and perturbations is a crucial step. However, existing methods require computationally extensive and complex multi-step procedures, which can introduce inefficiencies, limit generalizability, and increase potential errors. To address these challenges, we present PhenoProfiler, an innovative model designed to efficiently and effectively extract morphological representations, enabling the elucidation of phenotypic changes induced by treatments. PhenoProfiler is designed as an end-to-end tool that processes whole-slide multi-channel images directly into low-dimensional quantitative representations, eliminating the extensive computational steps required by existing methods. It also includes a multi-objective learning module to enhance robustness, accuracy, and generalization in morphological representation learning. PhenoProfiler is rigorously evaluated on large-scale publicly available datasets, including over 230,000 whole-slide multi-channel images in end-to-end scenarios and more than 8.42 million single-cell images in non-end-to-end settings. Across these benchmarks, PhenoProfiler consistently outperforms state-of-the-art methods by up to 20%, demonstrating substantial improvements in both accuracy and robustness. Furthermore, PhenoProfiler uses a tailored phenotype correction strategy to emphasize relative phenotypic changes under treatments, facilitating the detection of biologically meaningful signals. UMAP visualizations of treatment profiles demonstrate PhenoProfiler ability to effectively cluster treatments with similar biological annotations, thereby enhancing interpretability. These findings establish PhenoProfiler as a scalable, generalizable, and robust tool for phenotypic learning.
Splitting numerical integration for matrix completion
Feb 14, 2022Low rank matrix approximation is a popular topic in machine learning. In this paper, we propose a new algorithm for this topic by minimizing the least-squares estimation over the Riemannian manifold of fixed-rank matrices. The algorithm is an adaptation of classical gradient descent within the framework of optimization on manifolds. In particular, we reformulate an unconstrained optimization problem on a low-rank manifold into a differential dynamic system. We develop a splitting numerical integration method by applying a splitting integration scheme to the dynamic system. We conduct the convergence analysis of our splitting numerical integration algorithm. It can be guaranteed that the error between the recovered matrix and true result is monotonically decreasing in the Frobenius norm. Moreover, our splitting numerical integration can be adapted into matrix completion scenarios. Experimental results show that our approach has good scalability for large-scale problems with satisfactory accuracy
Approximate Inference via Clustering
Nov 28, 2021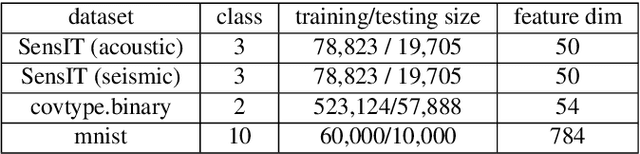
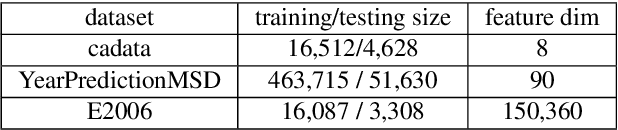
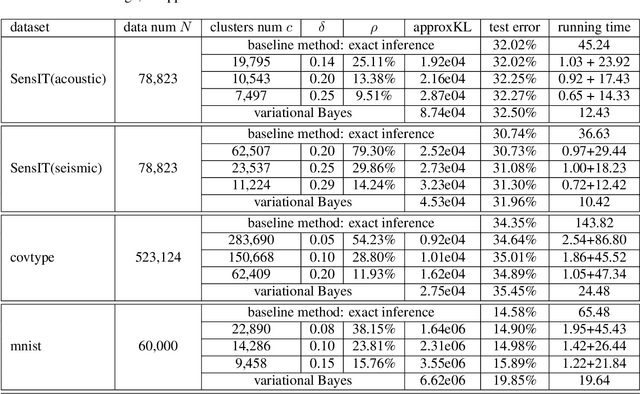
In recent years, large-scale Bayesian learning draws a great deal of attention. However, in big-data era, the amount of data we face is growing much faster than our ability to deal with it. Fortunately, it is observed that large-scale datasets usually own rich internal structure and is somewhat redundant. In this paper, we attempt to simplify the Bayesian posterior via exploiting this structure. Specifically, we restrict our interest to the so-called well-clustered datasets and construct an \emph{approximate posterior} according to the clustering information. Fortunately, the clustering structure can be efficiently obtained via a particular clustering algorithm. When constructing the approximate posterior, the data points in the same cluster are all replaced by the centroid of the cluster. As a result, the posterior can be significantly simplified. Theoretically, we show that under certain conditions the approximate posterior we construct is close (measured by KL divergence) to the exact posterior. Furthermore, thorough experiments are conducted to validate the fact that the constructed posterior is a good approximation to the true posterior and much easier to sample from.