 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniD$^3$: A Knowledge Graph-Enhanced RAG Framework for Drug-Disease Discovery and Reasoning
May 31, 2026Systematic characterization of drug-disease relationships is essential for drug discovery and repurposing, yet is hindered by the heterogeneity and rapid growth of biomedical literature. Existing datasets rely on labor-intensive curation and are often incomplete, while LLM-only approaches suffer from hallucination and weak evidence grounding. We introduce UniD$^3$, a unified framework that integrates Large Language Models with Knowledge Graph-enhanced Retrieval-Augmented Generation (KG-RAG) to extract, organize, and validate drug-disease knowledge across Drug-Disease Matching (DDM), Drug Effectiveness Assessment (DEA), and Drug-Target Analysis (DTA). UniD$^3$ processes 157,849 PubMed articles with Llama 3.3-70B and constructs knowledge graphs via a dual-stage strategy combining paper-level extraction with KG-level consolidation centered on drug and disease entities. These graphs support KG-RAG-based generation of structured datasets, evaluated through external benchmarks, fuzzy matching with curated resources, and clinician review. UniD$^3$ produces six knowledge graphs and large-scale datasets, including 28,915 DDM, 15,042 DEA, and over 4,000 DTA QA pairs. External validation shows strong performance (F1: 0.85-0.87 for DDM/DEA; 0.82 for DTA), with clinician review confirming high reliability (AUROC = 0.90). KG-RAG-augmented models outperform standalone LLMs, and the UniD$^3$ chatbot enables interpretable, citation-supported exploration of drug-disease relationships. UniD$^3$ provides a scalable, extensible framework for transforming unstructured biomedical literature into high-quality, structured drug-disease knowledge, supporting AI-driven discovery, repurposing, and precision medicine.
Hy-Facial: Hybrid Feature Extraction by Dimensionality Reduction Methods for Enhanced Facial Expression Classification
Sep 30, 2025Facial expression classification remains a challenging task due to the high dimensionality and inherent complexity of facial image data. This paper presents Hy-Facial, a hybrid feature extraction framework that integrates both deep learning and traditional image processing techniques, complemented by a systematic investigation of dimensionality reduction strategies. The proposed method fuses deep features extracted from the Visual Geometry Group 19-layer network (VGG19) with handcrafted local descriptors and the scale-invariant feature transform (SIFT) and Oriented FAST and Rotated BRIEF (ORB) algorithms, to obtain rich and diverse image representations. To mitigate feature redundancy and reduce computational complexity, we conduct a comprehensive evaluation of dimensionality reduction techniques and feature extraction. Among these, UMAP is identified as the most effective, preserving both local and global structures of the high-dimensional feature space. The Hy-Facial pipeline integrated VGG19, SIFT, and ORB for feature extraction, followed by K-means clustering and UMAP for dimensionality reduction, resulting in a classification accuracy of 83. 3\% in the facial expression recognition (FER) dataset. These findings underscore the pivotal role of dimensionality reduction not only as a pre-processing step but as an essential component in improving feature quality and overall classification performance.
Robust Diagram Reasoning: A Framework for Enhancing LVLM Performance on Visually Perturbed Scientific Diagrams
Aug 23, 2025Large Language Models (LLMs) and their multimodal variants (LVLMs) hold immense promise for scientific and engineering applications, particularly in processing visual information like scientific diagrams. However, their practical deployment is hindered by a critical lack of robustness to common visual perturbations such as noise, blur, and occlusions, which are prevalent in real-world scientific documents. Existing evaluation benchmarks largely overlook this challenge, leaving the robust reasoning capabilities of LVLMs on visually degraded scientific diagrams underexplored. To address this, we introduce the Robust Diagram Reasoning (RDR) framework, a novel approach designed to enhance and rigorously evaluate LVLMs' performance under such conditions. At its core, RDR employs an Adaptive Multi-View & Consistency Verification (AMCV) mechanism, which involves generating multiple perturbed versions of a diagram, performing parallel inference, and then applying a consistency-based self-correction loop. We also propose two new metrics, Perturbation Robustness Score (PRS) and Visual Degradation Consistency (VDC), to quantify robustness. Furthermore, we construct SciDiagram-Robust, the first large-scale scientific diagram question-answering dataset specifically augmented with diverse, programmatically generated visual perturbations. Our extensive experiments demonstrate that even state-of-the-art closed-source LVLMs like GPT-4V exhibit significant performance degradation when faced with perturbed inputs (Clean Accuracy 85.2% vs. PRS 72.1%).
scDrugMap: Benchmarking Large Foundation Models for Drug Response Prediction
May 08, 2025Drug resistance presents a major challenge in cancer therapy. Single cell profiling offers insights into cellular heterogeneity, yet the application of large-scale foundation models for predicting drug response in single cell data remains underexplored. To address this, we developed scDrugMap, an integrated framework featuring both a Python command-line interface and a web server for drug response prediction. scDrugMap evaluates a wide range of foundation models, including eight single-cell models and two large language models, using a curated dataset of over 326,000 cells in the primary collection and 18,800 cells in the validation set, spanning 36 datasets and diverse tissue and cancer types. We benchmarked model performance under pooled-data and cross-data evaluation settings, employing both layer freezing and Low-Rank Adaptation (LoRA) fine-tuning strategies. In the pooled-data scenario, scFoundation achieved the best performance, with mean F1 scores of 0.971 (layer freezing) and 0.947 (fine-tuning), outperforming the lowest-performing model by over 50%. In the cross-data setting, UCE excelled post fine-tuning (mean F1: 0.774), while scGPT led in zero-shot learning (mean F1: 0.858). Overall, scDrugMap provides the first large-scale benchmark of foundation models for drug response prediction in single-cell data and serves as a user-friendly, flexible platform for advancing drug discovery and translational research.
PhenoProfiler: Advancing Phenotypic Learning for Image-based Drug Discovery
Feb 26, 2025In the field of image-based drug discovery, capturing the phenotypic response of cells to various drug treatments and perturbations is a crucial step. However, existing methods require computationally extensive and complex multi-step procedures, which can introduce inefficiencies, limit generalizability, and increase potential errors. To address these challenges, we present PhenoProfiler, an innovative model designed to efficiently and effectively extract morphological representations, enabling the elucidation of phenotypic changes induced by treatments. PhenoProfiler is designed as an end-to-end tool that processes whole-slide multi-channel images directly into low-dimensional quantitative representations, eliminating the extensive computational steps required by existing methods. It also includes a multi-objective learning module to enhance robustness, accuracy, and generalization in morphological representation learning. PhenoProfiler is rigorously evaluated on large-scale publicly available datasets, including over 230,000 whole-slide multi-channel images in end-to-end scenarios and more than 8.42 million single-cell images in non-end-to-end settings. Across these benchmarks, PhenoProfiler consistently outperforms state-of-the-art methods by up to 20%, demonstrating substantial improvements in both accuracy and robustness. Furthermore, PhenoProfiler uses a tailored phenotype correction strategy to emphasize relative phenotypic changes under treatments, facilitating the detection of biologically meaningful signals. UMAP visualizations of treatment profiles demonstrate PhenoProfiler ability to effectively cluster treatments with similar biological annotations, thereby enhancing interpretability. These findings establish PhenoProfiler as a scalable, generalizable, and robust tool for phenotypic learning.
Dual-CBA: Improving Online Continual Learning via Dual Continual Bias Adaptors from a Bi-level Optimization Perspective
Aug 26, 2024



In online continual learning (CL), models trained on changing distributions easily forget previously learned knowledge and bias toward newly received tasks. To address this issue, we present Continual Bias Adaptor (CBA), a bi-level framework that augments the classification network to adapt to catastrophic distribution shifts during training, enabling the network to achieve a stable consolidation of all seen tasks. However, the CBA module adjusts distribution shifts in a class-specific manner, exacerbating the stability gap issue and, to some extent, fails to meet the need for continual testing in online CL. To mitigate this challenge, we further propose a novel class-agnostic CBA module that separately aggregates the posterior probabilities of classes from new and old tasks, and applies a stable adjustment to the resulting posterior probabilities. We combine the two kinds of CBA modules into a unified Dual-CBA module, which thus is capable of adapting to catastrophic distribution shifts and simultaneously meets the real-time testing requirements of online CL. Besides, we propose Incremental Batch Normalization (IBN), a tailored BN module to re-estimate its population statistics for alleviating the feature bias arising from the inner loop optimization problem of our bi-level framework. To validate the effectiveness of the proposed method, we theoretically provide some insights into how it mitigates catastrophic distribution shifts, and empirically demonstrate its superiority through extensive experiments based on four rehearsal-based baselines and three public continual learning benchmarks.
A Refreshed Similarity-based Upsampler for Direct High-Ratio Feature Upsampling
Jul 02, 2024Feature upsampling is a fundamental and indispensable ingredient of almost all current network structures for image segmentation tasks. Recently, a popular similarity-based feature upsampling pipeline has been proposed, which utilizes a high-resolution feature as guidance to help upsample the low-resolution deep feature based on their local similarity. Albeit achieving promising performance, this pipeline has specific limitations: 1) HR query and LR key features are not well aligned; 2) the similarity between query-key features is computed based on the fixed inner product form; 3) neighbor selection is coarsely operated on LR features, resulting in mosaic artifacts. These shortcomings make the existing methods along this pipeline primarily applicable to hierarchical network architectures with iterative features as guidance and they are not readily extended to a broader range of structures, especially for a direct high-ratio upsampling. Against the issues, we meticulously optimize every methodological design. Specifically, we firstly propose an explicitly controllable query-key feature alignment from both semantic-aware and detail-aware perspectives, and then construct a parameterized paired central difference convolution block for flexibly calculating the similarity between the well-aligned query-key features. Besides, we develop a fine-grained neighbor selection strategy on HR features, which is simple yet effective for alleviating mosaic artifacts. Based on these careful designs, we systematically construct a refreshed similarity-based feature upsampling framework named ReSFU. Extensive experiments substantiate that our proposed ReSFU is finely applicable to various types of architectures in a direct high-ratio upsampling manner, and consistently achieves satisfactory performance on different segmentation applications, showing superior generality and ease of deployment.
MEPNet: A Model-Driven Equivariant Proximal Network for Joint Sparse-View Reconstruction and Metal Artifact Reduction in CT Images
Jun 25, 2023Sparse-view computed tomography (CT) has been adopted as an important technique for speeding up data acquisition and decreasing radiation dose. However, due to the lack of sufficient projection data, the reconstructed CT images often present severe artifacts, which will be further amplified when patients carry metallic implants. For this joint sparse-view reconstruction and metal artifact reduction task, most of the existing methods are generally confronted with two main limitations: 1) They are almost built based on common network modules without fully embedding the physical imaging geometry constraint of this specific task into the dual-domain learning; 2) Some important prior knowledge is not deeply explored and sufficiently utilized. Against these issues, we specifically construct a dual-domain reconstruction model and propose a model-driven equivariant proximal network, called MEPNet. The main characteristics of MEPNet are: 1) It is optimization-inspired and has a clear working mechanism; 2) The involved proximal operator is modeled via a rotation equivariant convolutional neural network, which finely represents the inherent rotational prior underlying the CT scanning that the same organ can be imaged at different angles. Extensive experiments conducted on several datasets comprehensively substantiate that compared with the conventional convolution-based proximal network, such a rotation equivariance mechanism enables our proposed method to achieve better reconstruction performance with fewer network parameters. We will release the code at \url{https://github.com/hongwang01/MEPNet}.
Interactive Segmentation as Gaussian Process Classification
Feb 28, 2023Click-based interactive segmentation (IS) aims to extract the target objects under user interaction. For this task, most of the current deep learning (DL)-based methods mainly follow the general pipelines of semantic segmentation. Albeit achieving promising performance, they do not fully and explicitly utilize and propagate the click information, inevitably leading to unsatisfactory segmentation results, even at clicked points. Against this issue, in this paper, we propose to formulate the IS task as a Gaussian process (GP)-based pixel-wise binary classification model on each image. To solve this model, we utilize amortized variational inference to approximate the intractable GP posterior in a data-driven manner and then decouple the approximated GP posterior into double space forms for efficient sampling with linear complexity. Then, we correspondingly construct a GP classification framework, named GPCIS, which is integrated with the deep kernel learning mechanism for more flexibility. The main specificities of the proposed GPCIS lie in: 1) Under the explicit guidance of the derived GP posterior, the information contained in clicks can be finely propagated to the entire image and then boost the segmentation; 2) The accuracy of predictions at clicks has good theoretical support. These merits of GPCIS as well as its good generality and high efficiency are substantiated by comprehensive experiments on several benchmarks, as compared with representative methods both quantitatively and qualitatively.
Diagnosing Batch Normalization in Class Incremental Learning
Feb 16, 2022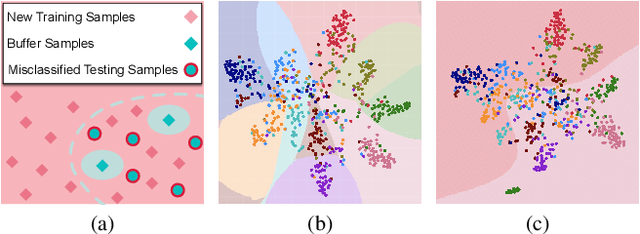
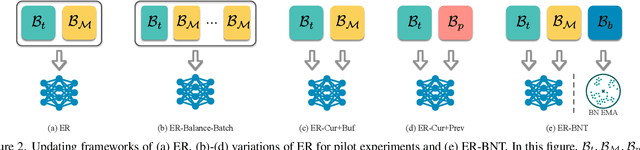
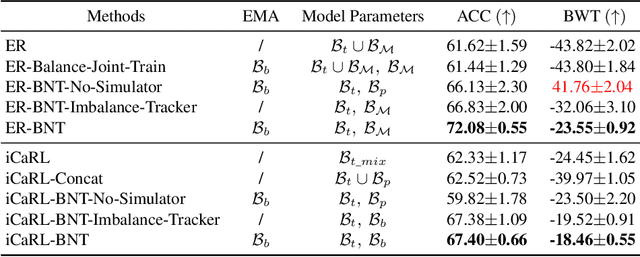
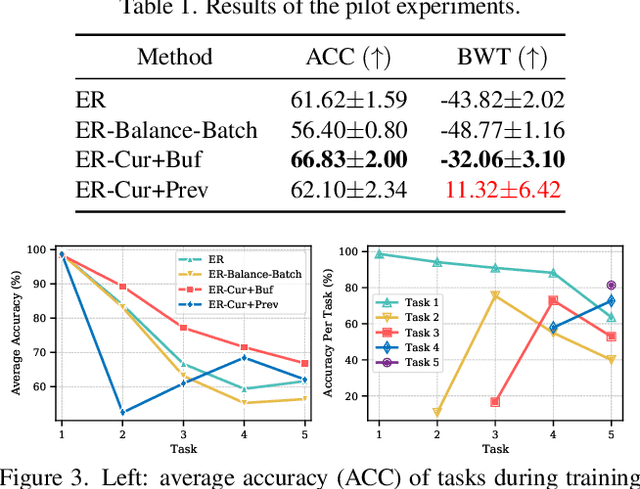
Extensive researches have applied deep neural networks (DNNs) in class incremental learning (Class-IL). As building blocks of DNNs, batch normalization (BN) standardizes intermediate feature maps and has been widely validated to improve training stability and convergence. However, we claim that the direct use of standard BN in Class-IL models is harmful to both the representation learning and the classifier training, thus exacerbating catastrophic forgetting. In this paper we investigate the influence of BN on Class-IL models by illustrating such BN dilemma. We further propose BN Tricks to address the issue by training a better feature extractor while eliminating classification bias. Without inviting extra hyperparameters, we apply BN Tricks to three baseline rehearsal-based methods, ER, DER++ and iCaRL. Through comprehensive experiments conducted on benchmark datasets of Seq-CIFAR-10, Seq-CIFAR-100 and Seq-Tiny-ImageNet, we show that BN Tricks can bring significant performance gains to all adopted baselines, revealing its potential generality along this line of research.