 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Batch Normalization in Class Incremental Learning
Paper and Code
Feb 16, 2022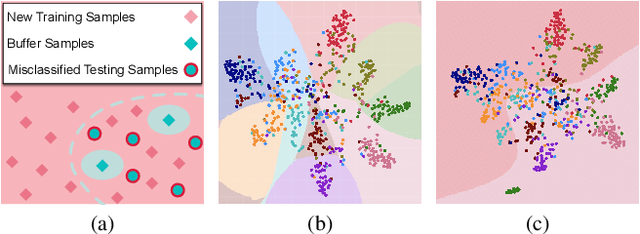
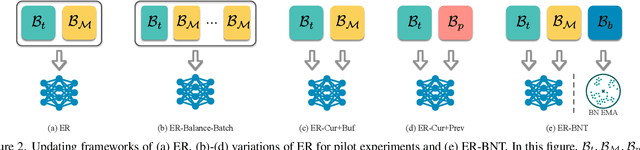
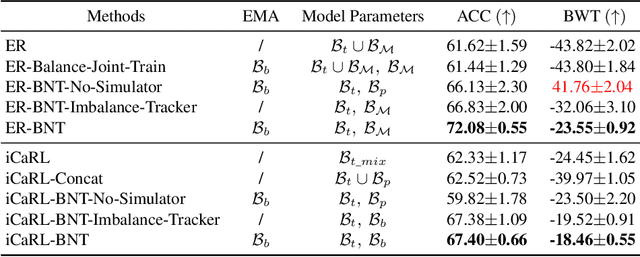
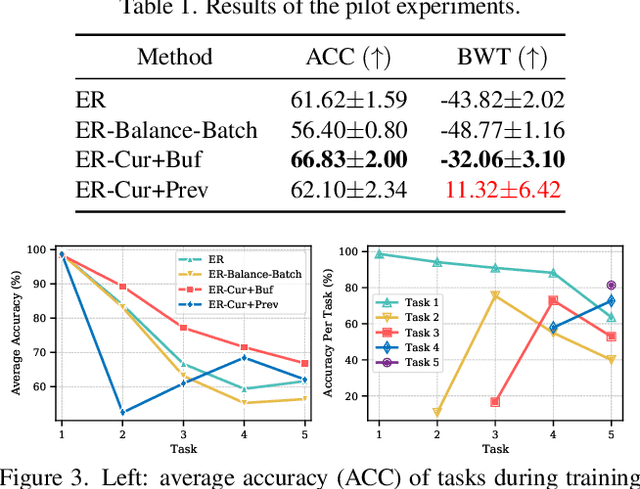
Extensive researches have applied deep neural networks (DNNs) in class incremental learning (Class-IL). As building blocks of DNNs, batch normalization (BN) standardizes intermediate feature maps and has been widely validated to improve training stability and convergence. However, we claim that the direct use of standard BN in Class-IL models is harmful to both the representation learning and the classifier training, thus exacerbating catastrophic forgetting. In this paper we investigate the influence of BN on Class-IL models by illustrating such BN dilemma. We further propose BN Tricks to address the issue by training a better feature extractor while eliminating classification bias. Without inviting extra hyperparameters, we apply BN Tricks to three baseline rehearsal-based methods, ER, DER++ and iCaRL. Through comprehensive experiments conducted on benchmark datasets of Seq-CIFAR-10, Seq-CIFAR-100 and Seq-Tiny-ImageNet, we show that BN Tricks can bring significant performance gains to all adopted baselines, revealing its potential generality along this line of research.