 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation Equivariant Arbitrary-scale Image Super-Resolution
Aug 07, 2025The arbitrary-scale image super-resolution (ASISR), a recent popular topic in computer vision, aims to achieve arbitrary-scale high-resolution recoveries from a low-resolution input image. This task is realized by representing the image as a continuous implicit function through two fundamental modules, a deep-network-based encoder and an implicit neural representation (INR) module. Despite achieving notable progress, a crucial challenge of such a highly ill-posed setting is that many common geometric patterns, such as repetitive textures, edges, or shapes, are seriously warped and deformed in the low-resolution images, naturally leading to unexpected artifacts appearing in their high-resolution recoveries. Embedding rotation equivariance into the ASISR network is thus necessary, as it has been widely demonstrated that this enhancement enables the recovery to faithfully maintain the original orientations and structural integrity of geometric patterns underlying the input image. Motivated by this, we make efforts to construct a rotation equivariant ASISR method in this study. Specifically, we elaborately redesign the basic architectures of INR and encoder modules, incorporating intrinsic rotation equivariance capabilities beyond those of conventional ASISR networks. Through such amelioration, the ASISR network can, for the first time, be implemented with end-to-end rotational equivariance maintained from input to output. We also provide a solid theoretical analysis to evaluate its intrinsic equivariance error, demonstrating its inherent nature of embedding such an equivariance structure. The superiority of the proposed method is substantiated by experiments conducted on both simulated and real datasets. We also validate that the proposed framework can be readily integrated into current ASISR methods in a plug \& play manner to further enhance their performance.
Improving Memory Efficiency for Training KANs via Meta Learning
Jun 09, 2025Inspired by the Kolmogorov-Arnold representation theorem, KANs offer a novel framework for function approximation by replacing traditional neural network weights with learnable univariate functions. This design demonstrates significant potential as an efficient and interpretable alternative to traditional MLPs. However, KANs are characterized by a substantially larger number of trainable parameters, leading to challenges in memory efficiency and higher training costs compared to MLPs. To address this limitation, we propose to generate weights for KANs via a smaller meta-learner, called MetaKANs. By training KANs and MetaKANs in an end-to-end differentiable manner, MetaKANs achieve comparable or even superior performance while significantly reducing the number of trainable parameters and maintaining promising interpretability. Extensive experiments on diverse benchmark tasks, including symbolic regression, partial differential equation solving, and image classification, demonstrate the effectiveness of MetaKANs in improving parameter efficiency and memory usage. The proposed method provides an alternative technique for training KANs, that allows for greater scalability and extensibility, and narrows the training cost gap with MLPs stated in the original paper of KANs. Our code is available at https://github.com/Murphyzc/MetaKAN.
Towards Prospective Medical Image Reconstruction via Knowledge-Informed Dynamic Optimal Transport
May 23, 2025Medical image reconstruction from measurement data is a vital but challenging inverse problem. Deep learning approaches have achieved promising results, but often requires paired measurement and high-quality images, which is typically simulated through a forward model, i.e., retrospective reconstruction. However, training on simulated pairs commonly leads to performance degradation on real prospective data due to the retrospective-to-prospective gap caused by incomplete imaging knowledge in simulation. To address this challenge, this paper introduces imaging Knowledge-Informed Dynamic Optimal Transport (KIDOT), a novel dynamic optimal transport framework with optimality in the sense of preserving consistency with imaging physics in transport, that conceptualizes reconstruction as finding a dynamic transport path. KIDOT learns from unpaired data by modeling reconstruction as a continuous evolution path from measurements to images, guided by an imaging knowledge-informed cost function and transport equation. This dynamic and knowledge-aware approach enhances robustness and better leverages unpaired data while respecting acquisition physics. Theoretically, we demonstrate that KIDOT naturally generalizes dynamic optimal transport, ensuring its mathematical rationale and solution existence. Extensive experiments on MRI and CT reconstruction demonstrate KIDOT's superior performance.
Adaptive Implicit-Based Deep Learning Channel Estimation for 6G Communications
May 23, 2025With the widespread deployment of fifth-generation (5G) wireless networks, research on sixth-generation (6G) technology is gaining momentum. Artificial Intelligence (AI) is anticipated to play a significant role in 6G, particularly through integration with the physical layer for tasks such as channel estimation. Considering resource limitations in real systems, the AI algorithm should be designed to have the ability to balance the accuracy and resource consumption according to the scenarios dynamically. However, conventional explicit multilayer-stacked Deep Learning (DL) models struggle to adapt due to their heavy reliance on the structure of deep neural networks. This article proposes an adaptive Implicit-layer DL Channel Estimation Network (ICENet) with a lightweight framework for vehicle-to-everything communications. This novel approach balances computational complexity and channel estimation accuracy by dynamically adjusting computational resources based on input data conditions, such as channel quality. Unlike explicit multilayer-stacked DL-based channel estimation models, ICENet offers a flexible framework, where specific requirements can be achieved by adaptively changing the number of iterations of the iterative layer. Meanwhile, ICENet requires less memory while maintaining high performance. The article concludes by highlighting open research challenges and promising future research directions.
GMapLatent: Geometric Mapping in Latent Space
Mar 30, 2025Cross-domain generative models based on encoder-decoder AI architectures have attracted much attention in generating realistic images, where domain alignment is crucial for generation accuracy. Domain alignment methods usually deal directly with the initial distribution; however, mismatched or mixed clusters can lead to mode collapse and mixture problems in the decoder, compromising model generalization capabilities. In this work, we innovate a cross-domain alignment and generation model that introduces a canonical latent space representation based on geometric mapping to align the cross-domain latent spaces in a rigorous and precise manner, thus avoiding mode collapse and mixture in the encoder-decoder generation architectures. We name this model GMapLatent. The core of the method is to seamlessly align latent spaces with strict cluster correspondence constraints using the canonical parameterizations of cluster-decorated latent spaces. We first (1) transform the latent space to a canonical parameter domain by composing barycenter translation, optimal transport merging and constrained harmonic mapping, and then (2) compute geometric registration with cluster constraints over the canonical parameter domains. This process realizes a bijective (one-to-one and onto) mapping between newly transformed latent spaces and generates a precise alignment of cluster pairs. Cross-domain generation is then achieved through the aligned latent spaces embedded in the encoder-decoder pipeline. Experiments on gray-scale and color images validate the efficiency, efficacy and applicability of GMapLatent, and demonstrate that the proposed model has superior performance over existing models.
TelOps: AI-driven Operations and Maintenance for Telecommunication Networks
Dec 06, 2024Telecommunication Networks (TNs) have become the most important infrastructure for data communications over the last century. Operations and maintenance (O&M) is extremely important to ensure the availability, effectiveness, and efficiency of TN communications. Different from the popular O&M technique for IT systems (e.g., the cloud), artificial intelligence for IT Operations (AIOps), O&M for TNs meets the following three fundamental challenges: topological dependence of network components, highly heterogeneous software, and restricted failure data. This article presents TelOps, the first AI-driven O&M framework for TNs, systematically enhanced with mechanism, data, and empirical knowledge. We provide a comprehensive comparison between TelOps and AIOps, and conduct a proof-of-concept case study on a typical O&M task (failure diagnosis) for a real industrial TN. As the first systematic AI-driven O&M framework for TNs, TelOps opens a new door to applying AI techniques to TN automation.
* 7 pages, 4 figures, magazine
Review of Mathematical Optimization in Federated Learning
Dec 02, 2024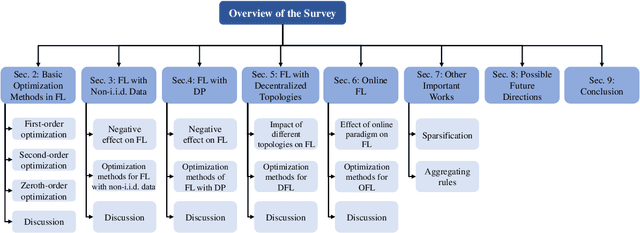
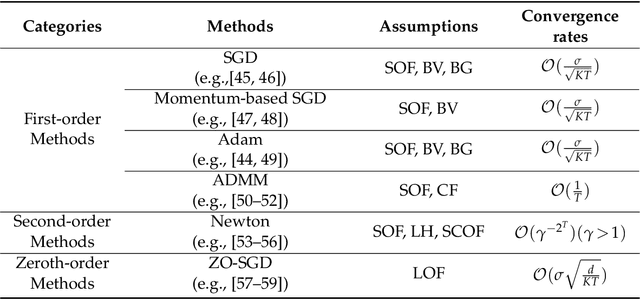
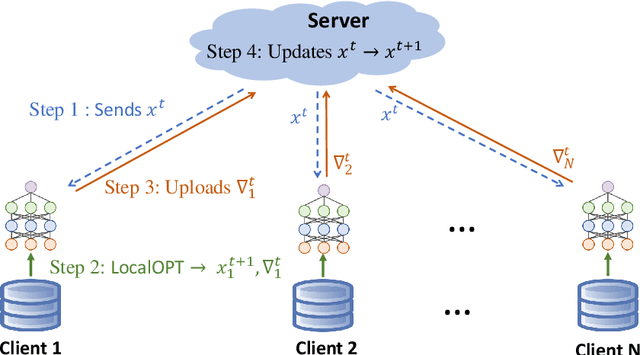

Federated Learning (FL) has been becoming a popular interdisciplinary research area in both applied mathematics and information sciences. Mathematically, FL aims to collaboratively optimize aggregate objective functions over distributed datasets while satisfying a variety of privacy and system constraints.Different from conventional distributed optimization methods, FL needs to address several specific issues (e.g., non-i.i.d. data distributions and differential private noises), which pose a set of new challenges in the problem formulation, algorithm design, and convergence analysis. In this paper, we will systematically review existing FL optimization research including their assumptions, formulations, methods, and theoretical results. Potential future directions are also discussed.
Adversarial Reweighting with $α$-Power Maximization for Domain Adaptation
Apr 26, 2024The practical Domain Adaptation (DA) tasks, e.g., Partial DA (PDA), open-set DA, universal DA, and test-time adaptation, have gained increasing attention in the machine learning community. In this paper, we propose a novel approach, dubbed Adversarial Reweighting with $\alpha$-Power Maximization (ARPM), for PDA where the source domain contains private classes absent in target domain. In ARPM, we propose a novel adversarial reweighting model that adversarially learns to reweight source domain data to identify source-private class samples by assigning smaller weights to them, for mitigating potential negative transfer. Based on the adversarial reweighting, we train the transferable recognition model on the reweighted source distribution to be able to classify common class data. To reduce the prediction uncertainty of the recognition model on the target domain for PDA, we present an $\alpha$-power maximization mechanism in ARPM, which enriches the family of losses for reducing the prediction uncertainty for PDA. Extensive experimental results on five PDA benchmarks, i.e., Office-31, Office-Home, VisDA-2017, ImageNet-Caltech, and DomainNet, show that our method is superior to recent PDA methods. Ablation studies also confirm the effectiveness of components in our approach. To theoretically analyze our method, we deduce an upper bound of target domain expected error for PDA, which is approximately minimized in our approach. We further extend ARPM to open-set DA, universal DA, and test time adaptation, and verify the usefulness through experiments.
Learning-based Multi-continuum Model for Multiscale Flow Problems
Mar 21, 2024Multiscale problems can usually be approximated through numerical homogenization by an equation with some effective parameters that can capture the macroscopic behavior of the original system on the coarse grid to speed up the simulation. However, this approach usually assumes scale separation and that the heterogeneity of the solution can be approximated by the solution average in each coarse block. For complex multiscale problems, the computed single effective properties/continuum might be inadequate. In this paper, we propose a novel learning-based multi-continuum model to enrich the homogenized equation and improve the accuracy of the single continuum model for multiscale problems with some given data. Without loss of generalization, we consider a two-continuum case. The first flow equation keeps the information of the original homogenized equation with an additional interaction term. The second continuum is newly introduced, and the effective permeability in the second flow equation is determined by a neural network. The interaction term between the two continua aligns with that used in the Dual-porosity model but with a learnable coefficient determined by another neural network. The new model with neural network terms is then optimized using trusted data. We discuss both direct back-propagation and the adjoint method for the PDE-constraint optimization problem. Our proposed learning-based multi-continuum model can resolve multiple interacted media within each coarse grid block and describe the mass transfer among them, and it has been demonstrated to significantly improve the simulation results through numerical experiments involving both linear and nonlinear flow equations.
TRG-Net: An Interpretable and Controllable Rain Generator
Mar 15, 2024Exploring and modeling rain generation mechanism is critical for augmenting paired data to ease training of rainy image processing models. Against this task, this study proposes a novel deep learning based rain generator, which fully takes the physical generation mechanism underlying rains into consideration and well encodes the learning of the fundamental rain factors (i.e., shape, orientation, length, width and sparsity) explicitly into the deep network. Its significance lies in that the generator not only elaborately design essential elements of the rain to simulate expected rains, like conventional artificial strategies, but also finely adapt to complicated and diverse practical rainy images, like deep learning methods. By rationally adopting filter parameterization technique, we first time achieve a deep network that is finely controllable with respect to rain factors and able to learn the distribution of these factors purely from data. Our unpaired generation experiments demonstrate that the rain generated by the proposed rain generator is not only of higher quality, but also more effective for deraining and downstream tasks compared to current state-of-the-art rain generation methods. Besides, the paired data augmentation experiments, including both in-distribution and out-of-distribution (OOD), further validate the diversity of samples generated by our model for in-distribution deraining and OOD generalization tasks.