 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Agentic RL with Progressive Reward Shaping and Value-based Sampling Policy Optimization
Dec 08, 2025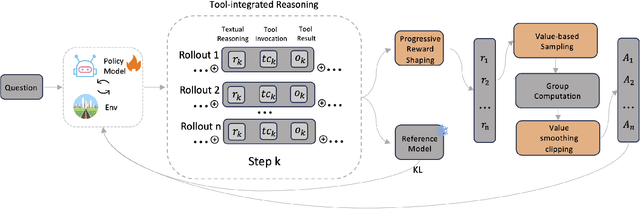
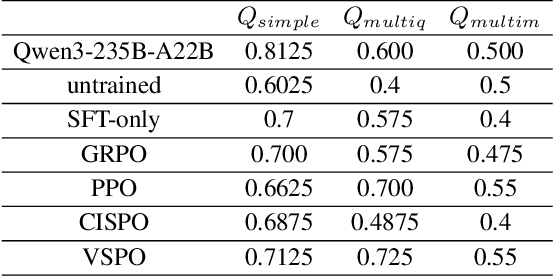
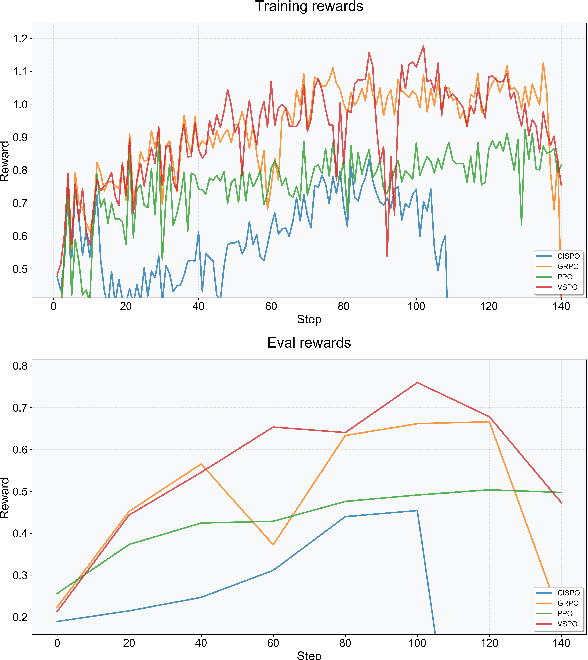
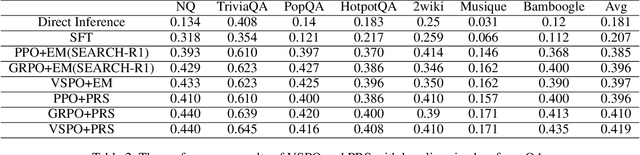
Large Language Models (LLMs) empowered with Tool-Integrated Reasoning (TIR) can iteratively plan, call external tools, and integrate returned information to solve complex, long-horizon reasoning tasks. Agentic Reinforcement Learning (Agentic RL) optimizes such models over full tool-interaction trajectories, but two key challenges hinder effectiveness: (1) Sparse, non-instructive rewards, such as binary 0-1 verifiable signals, provide limited guidance for intermediate steps and slow convergence; (2) Gradient degradation in Group Relative Policy Optimization (GRPO), where identical rewards within a rollout group yield zero advantage, reducing sample efficiency and destabilizing training. To address these challenges, we propose two complementary techniques: Progressive Reward Shaping (PRS) and Value-based Sampling Policy Optimization (VSPO). PRS is a curriculum-inspired reward design that introduces dense, stage-wise feedback - encouraging models to first master parseable and properly formatted tool calls, then optimize for factual correctness and answer quality. We instantiate PRS for short-form QA (with a length-aware BLEU to fairly score concise answers) and long-form QA (with LLM-as-a-Judge scoring to prevent reward hacking). VSPO is an enhanced GRPO variant that replaces low-value samples with prompts selected by a task-value metric balancing difficulty and uncertainty, and applies value-smoothing clipping to stabilize gradient updates. Experiments on multiple short-form and long-form QA benchmarks show that PRS consistently outperforms traditional binary rewards, and VSPO achieves superior stability, faster convergence, and higher final performance compared to PPO, GRPO, CISPO, and SFT-only baselines. Together, PRS and VSPO yield LLM-based TIR agents that generalize better across domains.
GMapLatent: Geometric Mapping in Latent Space
Mar 30, 2025Cross-domain generative models based on encoder-decoder AI architectures have attracted much attention in generating realistic images, where domain alignment is crucial for generation accuracy. Domain alignment methods usually deal directly with the initial distribution; however, mismatched or mixed clusters can lead to mode collapse and mixture problems in the decoder, compromising model generalization capabilities. In this work, we innovate a cross-domain alignment and generation model that introduces a canonical latent space representation based on geometric mapping to align the cross-domain latent spaces in a rigorous and precise manner, thus avoiding mode collapse and mixture in the encoder-decoder generation architectures. We name this model GMapLatent. The core of the method is to seamlessly align latent spaces with strict cluster correspondence constraints using the canonical parameterizations of cluster-decorated latent spaces. We first (1) transform the latent space to a canonical parameter domain by composing barycenter translation, optimal transport merging and constrained harmonic mapping, and then (2) compute geometric registration with cluster constraints over the canonical parameter domains. This process realizes a bijective (one-to-one and onto) mapping between newly transformed latent spaces and generates a precise alignment of cluster pairs. Cross-domain generation is then achieved through the aligned latent spaces embedded in the encoder-decoder pipeline. Experiments on gray-scale and color images validate the efficiency, efficacy and applicability of GMapLatent, and demonstrate that the proposed model has superior performance over existing models.