 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIARD: Cyclic Iterative Adversarial Robustness Distillation
Sep 16, 2025Adversarial robustness distillation (ARD) aims to transfer both performance and robustness from teacher model to lightweight student model, enabling resilient performance on resource-constrained scenarios. Though existing ARD approaches enhance student model's robustness, the inevitable by-product leads to the degraded performance on clean examples. We summarize the causes of this problem inherent in existing methods with dual-teacher framework as: 1. The divergent optimization objectives of dual-teacher models, i.e., the clean and robust teachers, impede effective knowledge transfer to the student model, and 2. The iteratively generated adversarial examples during training lead to performance deterioration of the robust teacher model. To address these challenges, we propose a novel Cyclic Iterative ARD (CIARD) method with two key innovations: a. A multi-teacher framework with contrastive push-loss alignment to resolve conflicts in dual-teacher optimization objectives, and b. Continuous adversarial retraining to maintain dynamic teacher robustness against performance degradation from the varying adversarial examples. Extensive experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet demonstrate that CIARD achieves remarkable performance with an average 3.53 improvement in adversarial defense rates across various attack scenarios and a 5.87 increase in clean sample accuracy, establishing a new benchmark for balancing model robustness and generalization. Our code is available at https://github.com/eminentgu/CIARD
BaryIR: Learning Multi-Source Unified Representation in Continuous Barycenter Space for Generalizable All-in-One Image Restoration
May 27, 2025Despite remarkable advances made in all-in-one image restoration (AIR) for handling different types of degradations simultaneously, existing methods remain vulnerable to out-of-distribution degradations and images, limiting their real-world applicability. In this paper, we propose a multi-source representation learning framework BaryIR, which decomposes the latent space of multi-source degraded images into a continuous barycenter space for unified feature encoding and source-specific subspaces for specific semantic encoding. Specifically, we seek the multi-source unified representation by introducing a multi-source latent optimal transport barycenter problem, in which a continuous barycenter map is learned to transport the latent representations to the barycenter space. The transport cost is designed such that the representations from source-specific subspaces are contrasted with each other while maintaining orthogonality to those from the barycenter space. This enables BaryIR to learn compact representations with unified degradation-agnostic information from the barycenter space, as well as degradation-specific semantics from source-specific subspaces, capturing the inherent geometry of multi-source data manifold for generalizable AIR. Extensive experiments demonstrate that BaryIR achieves competitive performance compared to state-of-the-art all-in-one methods. Particularly, BaryIR exhibits superior generalization ability to real-world data and unseen degradations. The code will be publicly available at https://github.com/xl-tang3/BaryIR.
Towards Prospective Medical Image Reconstruction via Knowledge-Informed Dynamic Optimal Transport
May 23, 2025Medical image reconstruction from measurement data is a vital but challenging inverse problem. Deep learning approaches have achieved promising results, but often requires paired measurement and high-quality images, which is typically simulated through a forward model, i.e., retrospective reconstruction. However, training on simulated pairs commonly leads to performance degradation on real prospective data due to the retrospective-to-prospective gap caused by incomplete imaging knowledge in simulation. To address this challenge, this paper introduces imaging Knowledge-Informed Dynamic Optimal Transport (KIDOT), a novel dynamic optimal transport framework with optimality in the sense of preserving consistency with imaging physics in transport, that conceptualizes reconstruction as finding a dynamic transport path. KIDOT learns from unpaired data by modeling reconstruction as a continuous evolution path from measurements to images, guided by an imaging knowledge-informed cost function and transport equation. This dynamic and knowledge-aware approach enhances robustness and better leverages unpaired data while respecting acquisition physics. Theoretically, we demonstrate that KIDOT naturally generalizes dynamic optimal transport, ensuring its mathematical rationale and solution existence. Extensive experiments on MRI and CT reconstruction demonstrate KIDOT's superior performance.
Joint Velocity-Growth Flow Matching for Single-Cell Dynamics Modeling
May 19, 2025
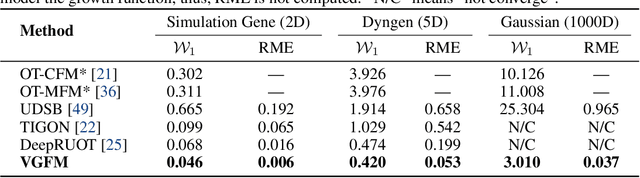


Learning the underlying dynamics of single cells from snapshot data has gained increasing attention in scientific and machine learning research. The destructive measurement technique and cell proliferation/death result in unpaired and unbalanced data between snapshots, making the learning of the underlying dynamics challenging. In this paper, we propose joint Velocity-Growth Flow Matching (VGFM), a novel paradigm that jointly learns state transition and mass growth of single-cell populations via flow matching. VGFM builds an ideal single-cell dynamics containing velocity of state and growth of mass, driven by a presented two-period dynamic understanding of the static semi-relaxed optimal transport, a mathematical tool that seeks the coupling between unpaired and unbalanced data. To enable practical usage, we approximate the ideal dynamics using neural networks, forming our joint velocity and growth matching framework. A distribution fitting loss is also employed in VGFM to further improve the fitting performance for snapshot data. Extensive experimental results on both synthetic and real datasets demonstrate that VGFM can capture the underlying biological dynamics accounting for mass and state variations over time, outperforming existing approaches for single-cell dynamics modeling.
GMapLatent: Geometric Mapping in Latent Space
Mar 30, 2025Cross-domain generative models based on encoder-decoder AI architectures have attracted much attention in generating realistic images, where domain alignment is crucial for generation accuracy. Domain alignment methods usually deal directly with the initial distribution; however, mismatched or mixed clusters can lead to mode collapse and mixture problems in the decoder, compromising model generalization capabilities. In this work, we innovate a cross-domain alignment and generation model that introduces a canonical latent space representation based on geometric mapping to align the cross-domain latent spaces in a rigorous and precise manner, thus avoiding mode collapse and mixture in the encoder-decoder generation architectures. We name this model GMapLatent. The core of the method is to seamlessly align latent spaces with strict cluster correspondence constraints using the canonical parameterizations of cluster-decorated latent spaces. We first (1) transform the latent space to a canonical parameter domain by composing barycenter translation, optimal transport merging and constrained harmonic mapping, and then (2) compute geometric registration with cluster constraints over the canonical parameter domains. This process realizes a bijective (one-to-one and onto) mapping between newly transformed latent spaces and generates a precise alignment of cluster pairs. Cross-domain generation is then achieved through the aligned latent spaces embedded in the encoder-decoder pipeline. Experiments on gray-scale and color images validate the efficiency, efficacy and applicability of GMapLatent, and demonstrate that the proposed model has superior performance over existing models.
Degradation-Aware Residual-Conditioned Optimal Transport for Unified Image Restoration
Nov 03, 2024



All-in-one image restoration has emerged as a practical and promising low-level vision task for real-world applications. In this context, the key issue lies in how to deal with different types of degraded images simultaneously. In this work, we present a Degradation-Aware Residual-Conditioned Optimal Transport (DA-RCOT) approach that models (all-in-one) image restoration as an optimal transport (OT) problem for unpaired and paired settings, introducing the transport residual as a degradation-specific cue for both the transport cost and the transport map. Specifically, we formalize image restoration with a residual-guided OT objective by exploiting the degradation-specific patterns of the Fourier residual in the transport cost. More crucially, we design the transport map for restoration as a two-pass DA-RCOT map, in which the transport residual is computed in the first pass and then encoded as multi-scale residual embeddings to condition the second-pass restoration. This conditioning process injects intrinsic degradation knowledge (e.g., degradation type and level) and structural information from the multi-scale residual embeddings into the OT map, which thereby can dynamically adjust its behaviors for all-in-one restoration. Extensive experiments across five degradations demonstrate the favorable performance of DA-RCOT as compared to state-of-the-art methods, in terms of distortion measures, perceptual quality, and image structure preservation. Notably, DA-RCOT delivers superior adaptability to real-world scenarios even with multiple degradations and shows distinctive robustness to both degradation levels and the number of degradations.
Prototypical Partial Optimal Transport for Universal Domain Adaptation
Aug 02, 2024Universal domain adaptation (UniDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain without requiring the same label sets of both domains. The existence of domain and category shift makes the task challenging and requires us to distinguish "known" samples (i.e., samples whose labels exist in both domains) and "unknown" samples (i.e., samples whose labels exist in only one domain) in both domains before reducing the domain gap. In this paper, we consider the problem from the point of view of distribution matching which we only need to align two distributions partially. A novel approach, dubbed mini-batch Prototypical Partial Optimal Transport (m-PPOT), is proposed to conduct partial distribution alignment for UniDA. In training phase, besides minimizing m-PPOT, we also leverage the transport plan of m-PPOT to reweight source prototypes and target samples, and design reweighted entropy loss and reweighted cross-entropy loss to distinguish "known" and "unknown" samples. Experiments on four benchmarks show that our method outperforms the previous state-of-the-art UniDA methods.
Residual-Conditioned Optimal Transport: Towards Structure-preserving Unpaired and Paired Image Restoration
May 05, 2024



Deep learning-based image restoration methods have achieved promising performance. However, how to faithfully preserve the structure of the original image remains challenging. To address this challenge, we propose a novel Residual-Conditioned Optimal Transport (RCOT) approach, which models the image restoration as an optimal transport (OT) problem for both unpaired and paired settings, integrating the transport residual as a unique degradation-specific cue for both the transport cost and the transport map. Specifically, we first formalize a Fourier residual-guided OT objective by incorporating the degradation-specific information of the residual into the transport cost. Based on the dual form of the OT formulation, we design the transport map as a two-pass RCOT map that comprises a base model and a refinement process, in which the transport residual is computed by the base model in the first pass and then encoded as a degradation-specific embedding to condition the second-pass restoration. By duality, the RCOT problem is transformed into a minimax optimization problem, which can be solved by adversarially training neural networks. Extensive experiments on multiple restoration tasks show the effectiveness of our approach in terms of both distortion measures and perceptual quality. Particularly, RCOT restores images with more faithful structural details compared to state-of-the-art methods.
Adversarial Reweighting with $α$-Power Maximization for Domain Adaptation
Apr 26, 2024The practical Domain Adaptation (DA) tasks, e.g., Partial DA (PDA), open-set DA, universal DA, and test-time adaptation, have gained increasing attention in the machine learning community. In this paper, we propose a novel approach, dubbed Adversarial Reweighting with $\alpha$-Power Maximization (ARPM), for PDA where the source domain contains private classes absent in target domain. In ARPM, we propose a novel adversarial reweighting model that adversarially learns to reweight source domain data to identify source-private class samples by assigning smaller weights to them, for mitigating potential negative transfer. Based on the adversarial reweighting, we train the transferable recognition model on the reweighted source distribution to be able to classify common class data. To reduce the prediction uncertainty of the recognition model on the target domain for PDA, we present an $\alpha$-power maximization mechanism in ARPM, which enriches the family of losses for reducing the prediction uncertainty for PDA. Extensive experimental results on five PDA benchmarks, i.e., Office-31, Office-Home, VisDA-2017, ImageNet-Caltech, and DomainNet, show that our method is superior to recent PDA methods. Ablation studies also confirm the effectiveness of components in our approach. To theoretically analyze our method, we deduce an upper bound of target domain expected error for PDA, which is approximately minimized in our approach. We further extend ARPM to open-set DA, universal DA, and test time adaptation, and verify the usefulness through experiments.
Optimal Transport-Guided Conditional Score-Based Diffusion Models
Nov 02, 2023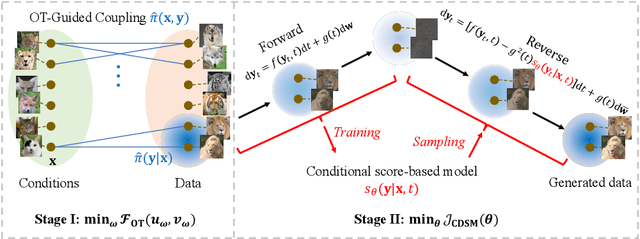
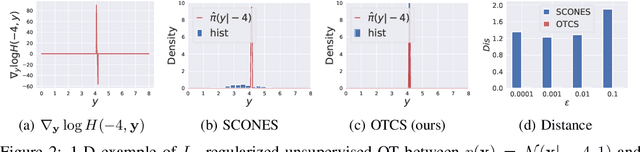


Conditional score-based diffusion model (SBDM) is for conditional generation of target data with paired data as condition, and has achieved great success in image translation. However, it requires the paired data as condition, and there would be insufficient paired data provided in real-world applications. To tackle the applications with partially paired or even unpaired dataset, we propose a novel Optimal Transport-guided Conditional Score-based diffusion model (OTCS) in this paper. We build the coupling relationship for the unpaired or partially paired dataset based on $L_2$-regularized unsupervised or semi-supervised optimal transport, respectively. Based on the coupling relationship, we develop the objective for training the conditional score-based model for unpaired or partially paired settings, which is based on a reformulation and generalization of the conditional SBDM for paired setting. With the estimated coupling relationship, we effectively train the conditional score-based model by designing a ``resampling-by-compatibility'' strategy to choose the sampled data with high compatibility as guidance. Extensive experiments on unpaired super-resolution and semi-paired image-to-image translation demonstrated the effectiveness of the proposed OTCS model. From the viewpoint of optimal transport, OTCS provides an approach to transport data across distributions, which is a challenge for OT on large-scale datasets. We theoretically prove that OTCS realizes the data transport in OT with a theoretical bound. Code is available at \url{https://github.com/XJTU-XGU/OTCS}.