 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Dual-Path Framework for Covert Semantic Communication
May 05, 2026This paper proposes a novel adaptive dual-path framework for covert semantic communication (SemCom), which integrates covert information transmission with task-oriented semantic coding. Unlike conventional covert communication methods that embed hidden messages through power-domain signal superposition, our framework embeds covert data within task-specific features via semantic-level intrinsic encoding. This new architecture introduces dual encoding paths with adaptive block selection: an Explicit path for public task execution and a Stego path that jointly encodes both public and covert information through contrastive representation alignment. A Gumbel-Softmax enabled adaptive path selection mechanism dynamically activates network blocks based on task require- ments. We formulate a multi-objective optimization framework that simultaneously ensures accurate semantic understanding and reliable covert transmission. We rigorously evaluate our framework's security against a powerful, independently trained attacker. Experimental results on the Cityscapes dataset demon- strate a state-of-the-art level of covertness: our method suppresses the attacker's detection accuracy to a near-random guessing level of 56.12%. This robust security is achieved while simultaneously maintaining superior performance on the primary semantic tasks compared to the baselines.
Hierarchy-Guided Multimodal Representation Learning for Taxonomic Inference
Mar 26, 2026Accurate biodiversity identification from large-scale field data is a foundational problem with direct impact on ecology, conservation, and environmental monitoring. In practice, the core task is taxonomic prediction - inferring order, family, genus, or species from imperfect inputs such as specimen images, DNA barcodes, or both. Existing multimodal methods often treat taxonomy as a flat label space and therefore fail to encode the hierarchical structure of biological classification, which is critical for robustness under noise and missing modalities. We present two end-to-end variants for hierarchy-aware multimodal learning: CLiBD-HiR, which introduces Hierarchical Information Regularization (HiR) to shape embedding geometry across taxonomic levels, yielding structured and noise-robust representations; and CLiBD-HiR-Fuse, which additionally trains a lightweight fusion predictor that supports image-only, DNA-only, or joint inference and is resilient to modality corruption. Across large-scale biodiversity benchmarks, our approach improves taxonomic classification accuracy by over 14 percent compared to strong multimodal baselines, with particularly large gains under partial and corrupted DNA conditions. These results highlight that explicitly encoding biological hierarchy, together with flexible fusion, is key for practical biodiversity foundation models.
Joint Routing and Model Pruning for Decentralized Federated Learning in Bandwidth-Constrained Multi-Hop Wireless Networks
Mar 16, 2026Decentralized federated learning (D-FL) enables privacy-preserving training without a central server, but multi-hop model exchanges and aggregation are often bottlenecked by communication resource constraints. To address this issue, we propose a joint routing-and-pruning framework that optimizes routing paths and pruning rates to maintain communication latency within prescribed limits. We analyze how the sum of model biases across all clients affects the convergence bound of D-FL and formulate an optimization problem that maximizes the model retention rate to minimize these biases under communication constraints. Further analysis reveals that each client's model retention rate is path-dependent, which reduces the original problem to a routing optimization. Leveraging this insight, we develop a routing algorithm that selects latency-efficient transmission paths, allowing more parameters to be delivered within the time budget and thereby improving D-FL convergence. Simulations demonstrate that, compared with unpruned systems, the proposed framework reduces average transmission latency by 27.8% and improves testing accuracy by approximately 12%. Furthermore, relative to standard benchmark routing algorithms, the proposed routing method improves accuracy by roughly 8%.
AutoSizer: Automatic Sizing of Analog and Mixed-Signal Circuits via Large Language Model (LLM) Agents
Feb 02, 2026The design of Analog and Mixed-Signal (AMS) integrated circuits remains heavily reliant on expert knowledge, with transistor sizing a major bottleneck due to nonlinear behavior, high-dimensional design spaces, and strict performance constraints. Existing Electronic Design Automation (EDA) methods typically frame sizing as static black-box optimization, resulting in inefficient and less robust solutions. Although Large Language Models (LLMs) exhibit strong reasoning abilities, they are not suited for precise numerical optimization in AMS sizing. To address this gap, we propose AutoSizer, a reflective LLM-driven meta-optimization framework that unifies circuit understanding, adaptive search-space construction, and optimization orchestration in a closed loop. It employs a two-loop optimization framework, with an inner loop for circuit sizing and an outer loop that analyzes optimization dynamics and constraints to iteratively refine the search space from simulation feedback. We further introduce AMS-SizingBench, an open benchmark comprising 24 diverse AMS circuits in SKY130 CMOS technology, designed to evaluate adaptive optimization policies under realistic simulator-based constraints. AutoSizer experimentally achieves higher solution quality, faster convergence, and higher success rate across varying circuit difficulties, outperforming both traditional optimization methods and existing LLM-based agents.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
Explanatory Summarization with Discourse-Driven Planning
Apr 27, 2025Lay summaries for scientific documents typically include explanations to help readers grasp sophisticated concepts or arguments. However, current automatic summarization methods do not explicitly model explanations, which makes it difficult to align the proportion of explanatory content with human-written summaries. In this paper, we present a plan-based approach that leverages discourse frameworks to organize summary generation and guide explanatory sentences by prompting responses to the plan. Specifically, we propose two discourse-driven planning strategies, where the plan is conditioned as part of the input or part of the output prefix, respectively. Empirical experiments on three lay summarization datasets show that our approach outperforms existing state-of-the-art methods in terms of summary quality, and it enhances model robustness, controllability, and mitigates hallucination.
What Is That Talk About? A Video-to-Text Summarization Dataset for Scientific Presentations
Feb 12, 2025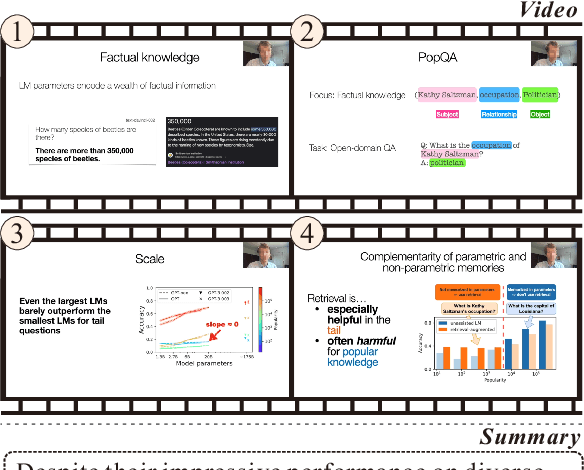
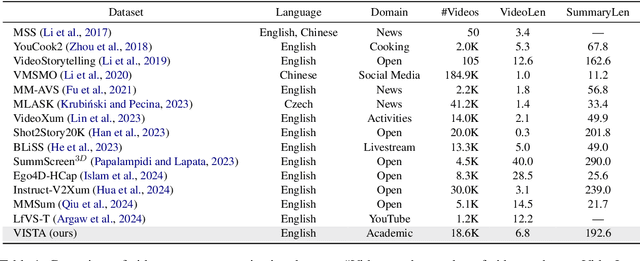

Transforming recorded videos into concise and accurate textual summaries is a growing challenge in multimodal learning. This paper introduces VISTA, a dataset specifically designed for video-to-text summarization in scientific domains. VISTA contains 18,599 recorded AI conference presentations paired with their corresponding paper abstracts. We benchmark the performance of state-of-the-art large models and apply a plan-based framework to better capture the structured nature of abstracts. Both human and automated evaluations confirm that explicit planning enhances summary quality and factual consistency. However, a considerable gap remains between models and human performance, highlighting the challenges of scientific video summarization.
Multi-Task Semantic Communication With Graph Attention-Based Feature Correlation Extraction
Jan 02, 2025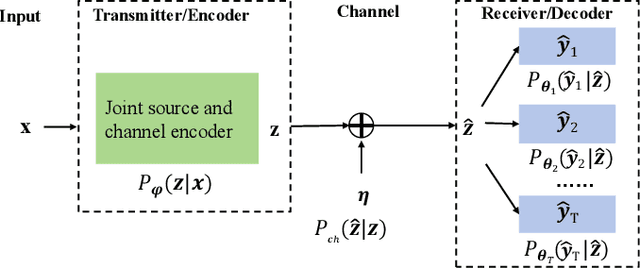
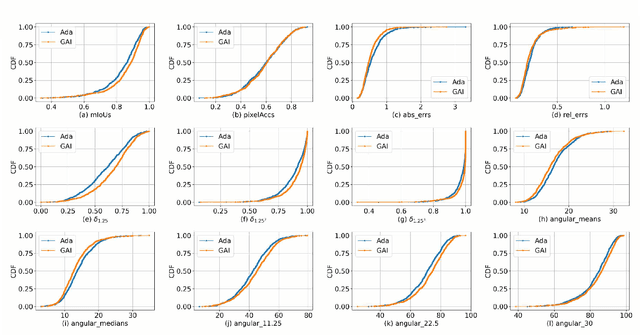
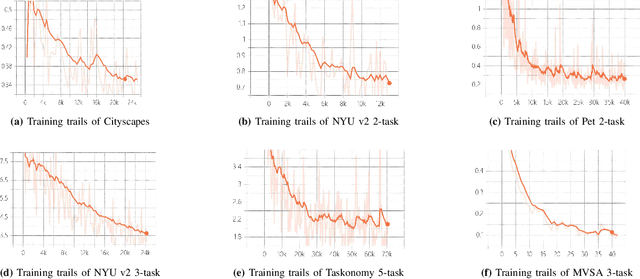
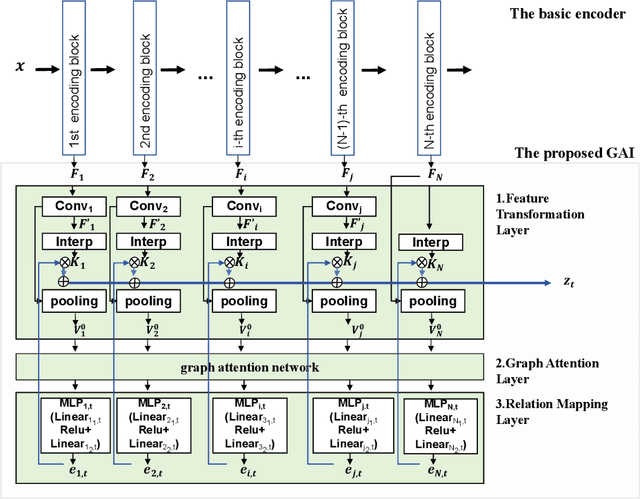
Multi-task semantic communication can serve multiple learning tasks using a shared encoder model. Existing models have overlooked the intricate relationships between features extracted during an encoding process of tasks. This paper presents a new graph attention inter-block (GAI) module to the encoder/transmitter of a multi-task semantic communication system, which enriches the features for multiple tasks by embedding the intermediate outputs of encoding in the features, compared to the existing techniques. The key idea is that we interpret the outputs of the intermediate feature extraction blocks of the encoder as the nodes of a graph to capture the correlations of the intermediate features. Another important aspect is that we refine the node representation using a graph attention mechanism to extract the correlations and a multi-layer perceptron network to associate the node representations with different tasks. Consequently, the intermediate features are weighted and embedded into the features transmitted for executing multiple tasks at the receiver. Experiments demonstrate that the proposed model surpasses the most competitive and publicly available models by 11.4% on the CityScapes 2Task dataset and outperforms the established state-of-the-art by 3.97% on the NYU V2 3Task dataset, respectively, when the bandwidth ratio of the communication channel (i.e., compression level for transmission over the channel) is as constrained as 1 12 .
Cauchy-Schwarz Divergence Information Bottleneck for Regression
Apr 27, 2024



The information bottleneck (IB) approach is popular to improve the generalization, robustness and explainability of deep neural networks. Essentially, it aims to find a minimum sufficient representation $\mathbf{t}$ by striking a trade-off between a compression term $I(\mathbf{x};\mathbf{t})$ and a prediction term $I(y;\mathbf{t})$, where $I(\cdot;\cdot)$ refers to the mutual information (MI). MI is for the IB for the most part expressed in terms of the Kullback-Leibler (KL) divergence, which in the regression case corresponds to prediction based on mean squared error (MSE) loss with Gaussian assumption and compression approximated by variational inference. In this paper, we study the IB principle for the regression problem and develop a new way to parameterize the IB with deep neural networks by exploiting favorable properties of the Cauchy-Schwarz (CS) divergence. By doing so, we move away from MSE-based regression and ease estimation by avoiding variational approximations or distributional assumptions. We investigate the improved generalization ability of our proposed CS-IB and demonstrate strong adversarial robustness guarantees. We demonstrate its superior performance on six real-world regression tasks over other popular deep IB approaches. We additionally observe that the solutions discovered by CS-IB always achieve the best trade-off between prediction accuracy and compression ratio in the information plane. The code is available at \url{https://github.com/SJYuCNEL/Cauchy-Schwarz-Information-Bottleneck}.
Adversarial Reweighting with $α$-Power Maximization for Domain Adaptation
Apr 26, 2024The practical Domain Adaptation (DA) tasks, e.g., Partial DA (PDA), open-set DA, universal DA, and test-time adaptation, have gained increasing attention in the machine learning community. In this paper, we propose a novel approach, dubbed Adversarial Reweighting with $\alpha$-Power Maximization (ARPM), for PDA where the source domain contains private classes absent in target domain. In ARPM, we propose a novel adversarial reweighting model that adversarially learns to reweight source domain data to identify source-private class samples by assigning smaller weights to them, for mitigating potential negative transfer. Based on the adversarial reweighting, we train the transferable recognition model on the reweighted source distribution to be able to classify common class data. To reduce the prediction uncertainty of the recognition model on the target domain for PDA, we present an $\alpha$-power maximization mechanism in ARPM, which enriches the family of losses for reducing the prediction uncertainty for PDA. Extensive experimental results on five PDA benchmarks, i.e., Office-31, Office-Home, VisDA-2017, ImageNet-Caltech, and DomainNet, show that our method is superior to recent PDA methods. Ablation studies also confirm the effectiveness of components in our approach. To theoretically analyze our method, we deduce an upper bound of target domain expected error for PDA, which is approximately minimized in our approach. We further extend ARPM to open-set DA, universal DA, and test time adaptation, and verify the usefulness through experiments.