 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning About Intent for Ambiguous Requests
Nov 13, 2025
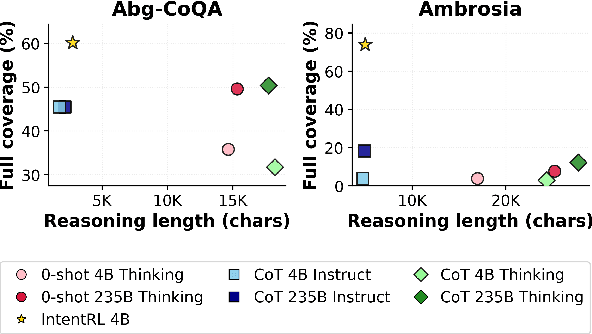


Large language models often respond to ambiguous requests by implicitly committing to one interpretation. Intent misunderstandings can frustrate users and create safety risks. To address this, we propose generating multiple interpretation-answer pairs in a single structured response to ambiguous requests. Our models are trained with reinforcement learning and customized reward functions using multiple valid answers as supervision. Experiments on conversational question answering and semantic parsing demonstrate that our method achieves higher coverage of valid answers than baseline approaches. Human evaluation confirms that predicted interpretations are highly aligned with their answers. Our approach promotes transparency with explicit interpretations, achieves efficiency by requiring only one generation step, and supports downstream applications through its structured output format.
Patient-Centered Summarization Framework for AI Clinical Summarization: A Mixed-Methods Design
Oct 31, 2025Large Language Models (LLMs) are increasingly demonstrating the potential to reach human-level performance in generating clinical summaries from patient-clinician conversations. However, these summaries often focus on patients' biology rather than their preferences, values, wishes, and concerns. To achieve patient-centered care, we propose a new standard for Artificial Intelligence (AI) clinical summarization tasks: Patient-Centered Summaries (PCS). Our objective was to develop a framework to generate PCS that capture patient values and ensure clinical utility and to assess whether current open-source LLMs can achieve human-level performance in this task. We used a mixed-methods process. Two Patient and Public Involvement groups (10 patients and 8 clinicians) in the United Kingdom participated in semi-structured interviews exploring what personal and contextual information should be included in clinical summaries and how it should be structured for clinical use. Findings informed annotation guidelines used by eight clinicians to create gold-standard PCS from 88 atrial fibrillation consultations. Sixteen consultations were used to refine a prompt aligned with the guidelines. Five open-source LLMs (Llama-3.2-3B, Llama-3.1-8B, Mistral-8B, Gemma-3-4B, and Qwen3-8B) generated summaries for 72 consultations using zero-shot and few-shot prompting, evaluated with ROUGE-L, BERTScore, and qualitative metrics. Patients emphasized lifestyle routines, social support, recent stressors, and care values. Clinicians sought concise functional, psychosocial, and emotional context. The best zero-shot performance was achieved by Mistral-8B (ROUGE-L 0.189) and Llama-3.1-8B (BERTScore 0.673); the best few-shot by Llama-3.1-8B (ROUGE-L 0.206, BERTScore 0.683). Completeness and fluency were similar between experts and models, while correctness and patient-centeredness favored human PCS.
Meta-Adaptive Prompt Distillation for Few-Shot Visual Question Answering
Jun 07, 2025Large Multimodal Models (LMMs) often rely on in-context learning (ICL) to perform new tasks with minimal supervision. However, ICL performance, especially in smaller LMMs, is inconsistent and does not always improve monotonically with increasing examples. We hypothesize that this occurs due to the LMM being overwhelmed by additional information present in the image embeddings, which is not required for the downstream task. To address this, we propose a meta-learning approach that provides an alternative for inducing few-shot capabilities in LMMs, using a fixed set of soft prompts that are distilled from task-relevant image features and can be adapted at test time using a few examples. To facilitate this distillation, we introduce an attention-mapper module that can be easily integrated with the popular LLaVA v1.5 architecture and is jointly learned with soft prompts, enabling task adaptation in LMMs under low-data regimes with just a few gradient steps. Evaluation on the VL-ICL Bench shows that our method consistently outperforms ICL and related prompt-tuning approaches, even under image perturbations, improving task induction and reasoning across visual question answering tasks.
Compositional Generalisation for Explainable Hate Speech Detection
Jun 04, 2025Hate speech detection is key to online content moderation, but current models struggle to generalise beyond their training data. This has been linked to dataset biases and the use of sentence-level labels, which fail to teach models the underlying structure of hate speech. In this work, we show that even when models are trained with more fine-grained, span-level annotations (e.g., "artists" is labeled as target and "are parasites" as dehumanising comparison), they struggle to disentangle the meaning of these labels from the surrounding context. As a result, combinations of expressions that deviate from those seen during training remain particularly difficult for models to detect. We investigate whether training on a dataset where expressions occur with equal frequency across all contexts can improve generalisation. To this end, we create U-PLEAD, a dataset of ~364,000 synthetic posts, along with a novel compositional generalisation benchmark of ~8,000 manually validated posts. Training on a combination of U-PLEAD and real data improves compositional generalisation while achieving state-of-the-art performance on the human-sourced PLEAD.
Long-Form Information Alignment Evaluation Beyond Atomic Facts
May 21, 2025Information alignment evaluators are vital for various NLG evaluation tasks and trustworthy LLM deployment, reducing hallucinations and enhancing user trust. Current fine-grained methods, like FactScore, verify facts individually but neglect inter-fact dependencies, enabling subtle vulnerabilities. In this work, we introduce MontageLie, a challenging benchmark that constructs deceptive narratives by "montaging" truthful statements without introducing explicit hallucinations. We demonstrate that both coarse-grained LLM-based evaluators and current fine-grained frameworks are susceptible to this attack, with AUC-ROC scores falling below 65%. To enable more robust fine-grained evaluation, we propose DoveScore, a novel framework that jointly verifies factual accuracy and event-order consistency. By modeling inter-fact relationships, DoveScore outperforms existing fine-grained methods by over 8%, providing a more robust solution for long-form text alignment evaluation. Our code and datasets are available at https://github.com/dannalily/DoveScore.
Debating for Better Reasoning: An Unsupervised Multimodal Approach
May 20, 2025As Large Language Models (LLMs) gain expertise across diverse domains and modalities, scalable oversight becomes increasingly challenging, particularly when their capabilities may surpass human evaluators. Debate has emerged as a promising mechanism for enabling such oversight. In this work, we extend the debate paradigm to a multimodal setting, exploring its potential for weaker models to supervise and enhance the performance of stronger models. We focus on visual question answering (VQA), where two "sighted" expert vision-language models debate an answer, while a "blind" (text-only) judge adjudicates based solely on the quality of the arguments. In our framework, the experts defend only answers aligned with their beliefs, thereby obviating the need for explicit role-playing and concentrating the debate on instances of expert disagreement. Experiments on several multimodal tasks demonstrate that the debate framework consistently outperforms individual expert models. Moreover, judgments from weaker LLMs can help instill reasoning capabilities in vision-language models through finetuning.
K*-Means: A Parameter-free Clustering Algorithm
May 17, 2025Clustering is a widely used and powerful machine learning technique, but its effectiveness is often limited by the need to specify the number of clusters, k, or by relying on thresholds that implicitly determine k. We introduce k*-means, a novel clustering algorithm that eliminates the need to set k or any other parameters. Instead, it uses the minimum description length principle to automatically determine the optimal number of clusters, k*, by splitting and merging clusters while also optimising the standard k-means objective. We prove that k*-means is guaranteed to converge and demonstrate experimentally that it significantly outperforms existing methods in scenarios where k is unknown. We also show that it is accurate in estimating k, and that empirically its runtime is competitive with existing methods, and scales well with dataset size.
Masking in Multi-hop QA: An Analysis of How Language Models Perform with Context Permutation
May 16, 2025



Multi-hop Question Answering (MHQA) adds layers of complexity to question answering, making it more challenging. When Language Models (LMs) are prompted with multiple search results, they are tasked not only with retrieving relevant information but also employing multi-hop reasoning across the information sources. Although LMs perform well on traditional question-answering tasks, the causal mask can hinder their capacity to reason across complex contexts. In this paper, we explore how LMs respond to multi-hop questions by permuting search results (retrieved documents) under various configurations. Our study reveals interesting findings as follows: 1) Encoder-decoder models, such as the ones in the Flan-T5 family, generally outperform causal decoder-only LMs in MHQA tasks, despite being significantly smaller in size; 2) altering the order of gold documents reveals distinct trends in both Flan T5 models and fine-tuned decoder-only models, with optimal performance observed when the document order aligns with the reasoning chain order; 3) enhancing causal decoder-only models with bi-directional attention by modifying the causal mask can effectively boost their end performance. In addition to the above, we conduct a thorough investigation of the distribution of LM attention weights in the context of MHQA. Our experiments reveal that attention weights tend to peak at higher values when the resulting answer is correct. We leverage this finding to heuristically improve LMs' performance on this task. Our code is publicly available at https://github.com/hwy9855/MultiHopQA-Reasoning.
Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions
May 01, 2025Memory is a fundamental component of AI systems, underpinning large language models (LLMs) based agents. While prior surveys have focused on memory applications with LLMs, they often overlook the atomic operations that underlie memory dynamics. In this survey, we first categorize memory representations into parametric, contextual structured, and contextual unstructured and then introduce six fundamental memory operations: Consolidation, Updating, Indexing, Forgetting, Retrieval, and Compression. We systematically map these operations to the most relevant research topics across long-term, long-context, parametric modification, and multi-source memory. By reframing memory systems through the lens of atomic operations and representation types, this survey provides a structured and dynamic perspective on research, benchmark datasets, and tools related to memory in AI, clarifying the functional interplay in LLMs based agents while outlining promising directions for future research\footnote{The paper list, datasets, methods and tools are available at \href{https://github.com/Elvin-Yiming-Du/Survey_Memory_in_AI}{https://github.com/Elvin-Yiming-Du/Survey\_Memory\_in\_AI}.}.
Explanatory Summarization with Discourse-Driven Planning
Apr 27, 2025Lay summaries for scientific documents typically include explanations to help readers grasp sophisticated concepts or arguments. However, current automatic summarization methods do not explicitly model explanations, which makes it difficult to align the proportion of explanatory content with human-written summaries. In this paper, we present a plan-based approach that leverages discourse frameworks to organize summary generation and guide explanatory sentences by prompting responses to the plan. Specifically, we propose two discourse-driven planning strategies, where the plan is conditioned as part of the input or part of the output prefix, respectively. Empirical experiments on three lay summarization datasets show that our approach outperforms existing state-of-the-art methods in terms of summary quality, and it enhances model robustness, controllability, and mitigates hallucination.