 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Text Ranking in Deep Research
Feb 25, 2026Deep research has emerged as an important task that aims to address hard queries through extensive open-web exploration. To tackle it, most prior work equips large language model (LLM)-based agents with opaque web search APIs, enabling agents to iteratively issue search queries, retrieve external evidence, and reason over it. Despite search's essential role in deep research, black-box web search APIs hinder systematic analysis of search components, leaving the behaviour of established text ranking methods in deep research largely unclear. To fill this gap, we reproduce a selection of key findings and best practices for IR text ranking methods in the deep research setting. In particular, we examine their effectiveness from three perspectives: (i) retrieval units (documents vs. passages), (ii) pipeline configurations (different retrievers, re-rankers, and re-ranking depths), and (iii) query characteristics (the mismatch between agent-issued queries and the training queries of text rankers). We perform experiments on BrowseComp-Plus, a deep research dataset with a fixed corpus, evaluating 2 open-source agents, 5 retrievers, and 3 re-rankers across diverse setups. We find that agent-issued queries typically follow web-search-style syntax (e.g., quoted exact matches), favouring lexical, learned sparse, and multi-vector retrievers; passage-level units are more efficient under limited context windows, and avoid the difficulties of document length normalisation in lexical retrieval; re-ranking is highly effective; translating agent-issued queries into natural-language questions significantly bridges the query mismatch.
Uncertainty-Aware Gradient Signal-to-Noise Data Selection for Instruction Tuning
Jan 20, 2026Instruction tuning is a standard paradigm for adapting large language models (LLMs), but modern instruction datasets are large, noisy, and redundant, making full-data fine-tuning costly and often unnecessary. Existing data selection methods either build expensive gradient datastores or assign static scores from a weak proxy, largely ignoring evolving uncertainty, and thus missing a key source of LLM interpretability. We propose GRADFILTERING, an objective-agnostic, uncertainty-aware data selection framework that utilizes a small GPT-2 proxy with a LoRA ensemble and aggregates per-example gradients into a Gradient Signal-to-Noise Ratio (G-SNR) utility. Our method matches or surpasses random subsets and strong baselines in most LLM-as-a-judge evaluations as well as in human assessment. Moreover, GRADFILTERING-selected subsets converge faster than competitive filters under the same compute budget, reflecting the benefit of uncertainty-aware scoring.
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
Sep 16, 2025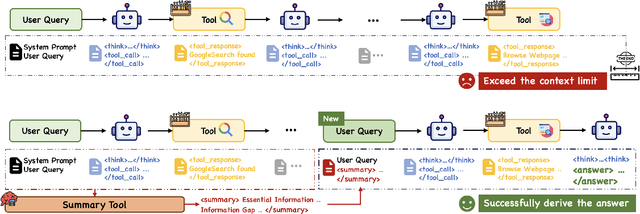
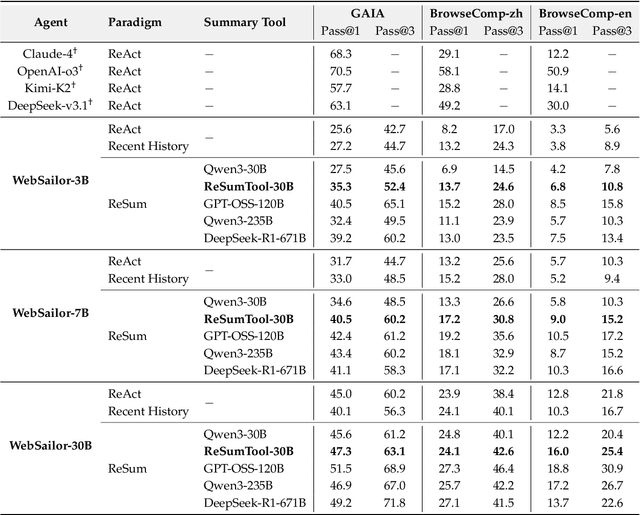
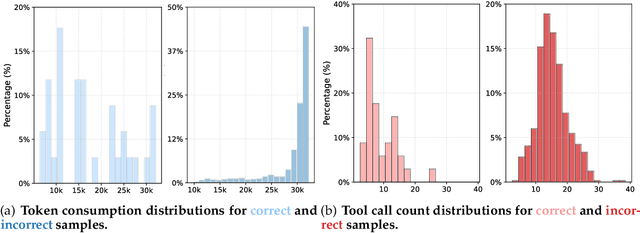
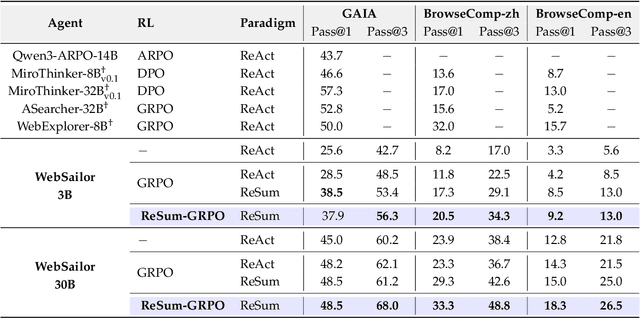
Large Language Model (LLM)-based web agents demonstrate strong performance on knowledge-intensive tasks but are hindered by context window limitations in paradigms like ReAct. Complex queries involving multiple entities, intertwined relationships, and high uncertainty demand extensive search cycles that rapidly exhaust context budgets before reaching complete solutions. To overcome this challenge, we introduce ReSum, a novel paradigm that enables indefinite exploration through periodic context summarization. ReSum converts growing interaction histories into compact reasoning states, maintaining awareness of prior discoveries while bypassing context constraints. For paradigm adaptation, we propose ReSum-GRPO, integrating GRPO with segmented trajectory training and advantage broadcasting to familiarize agents with summary-conditioned reasoning. Extensive experiments on web agents of varying scales across three benchmarks demonstrate that ReSum delivers an average absolute improvement of 4.5\% over ReAct, with further gains of up to 8.2\% following ReSum-GRPO training. Notably, with only 1K training samples, our WebResummer-30B (a ReSum-GRPO-trained version of WebSailor-30B) achieves 33.3\% Pass@1 on BrowseComp-zh and 18.3\% on BrowseComp-en, surpassing existing open-source web agents.
WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
Sep 16, 2025



Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all open-source agents in complex information-seeking tasks, matching proprietary agents' performance and closing the capability gap.
WebSailor: Navigating Super-human Reasoning for Web Agent
Jul 03, 2025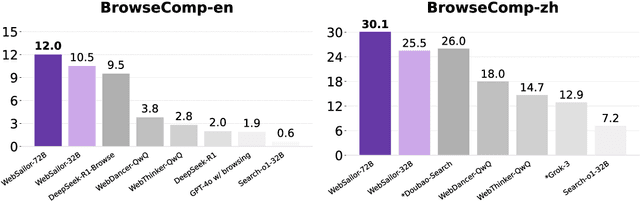
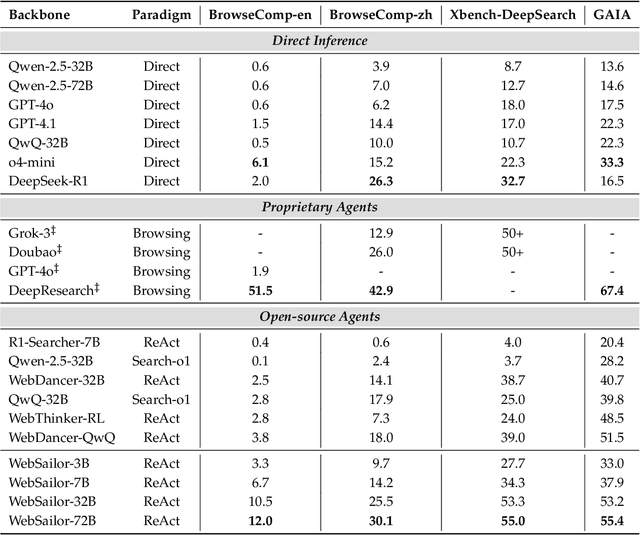
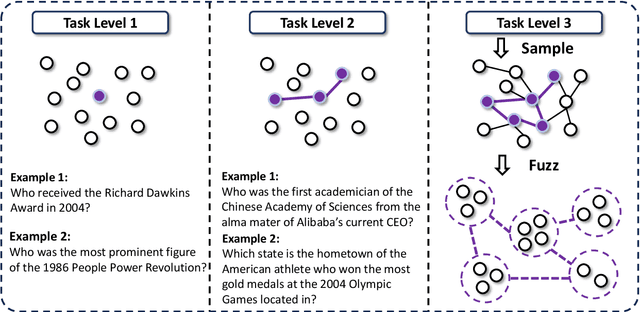

Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all opensource agents in complex information-seeking tasks, matching proprietary agents' performance and closing the capability gap.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
ToLeaP: Rethinking Development of Tool Learning with Large Language Models
May 17, 2025
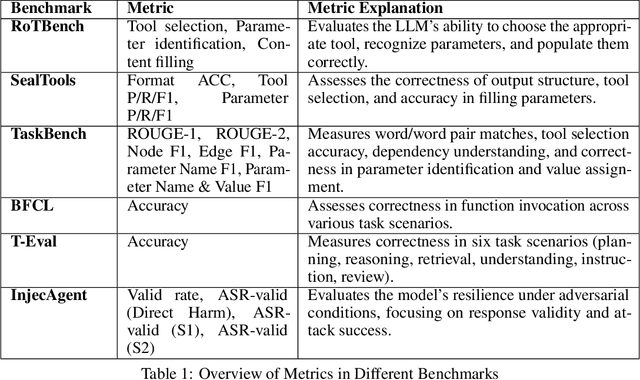
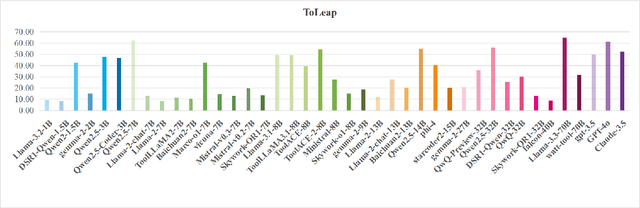
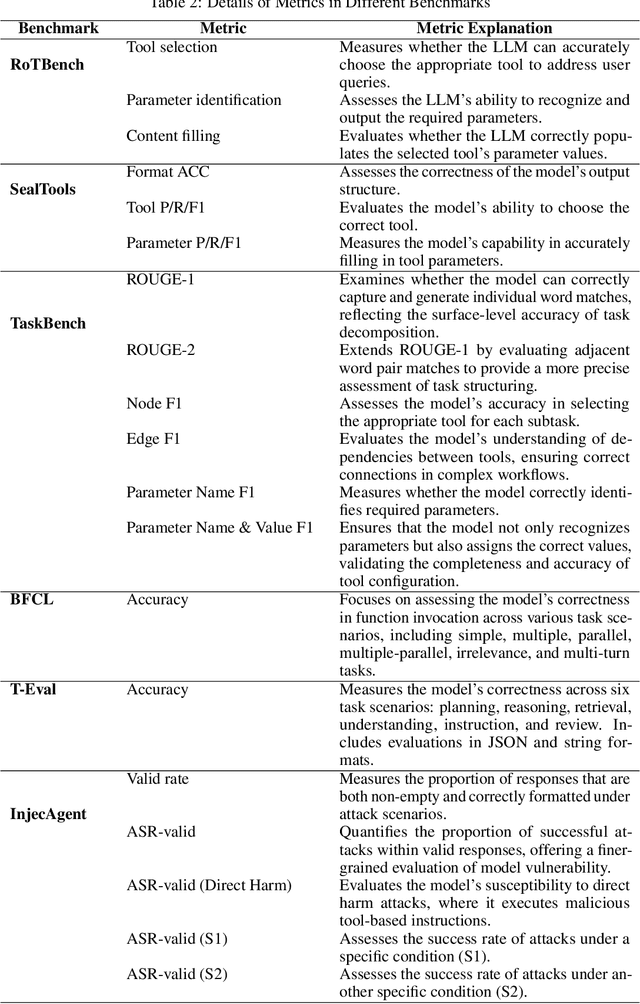
Tool learning, which enables large language models (LLMs) to utilize external tools effectively, has garnered increasing attention for its potential to revolutionize productivity across industries. Despite rapid development in tool learning, key challenges and opportunities remain understudied, limiting deeper insights and future advancements. In this paper, we investigate the tool learning ability of 41 prevalent LLMs by reproducing 33 benchmarks and enabling one-click evaluation for seven of them, forming a Tool Learning Platform named ToLeaP. We also collect 21 out of 33 potential training datasets to facilitate future exploration. After analyzing over 3,000 bad cases of 41 LLMs based on ToLeaP, we identify four main critical challenges: (1) benchmark limitations induce both the neglect and lack of (2) autonomous learning, (3) generalization, and (4) long-horizon task-solving capabilities of LLMs. To aid future advancements, we take a step further toward exploring potential directions, namely (1) real-world benchmark construction, (2) compatibility-aware autonomous learning, (3) rationale learning by thinking, and (4) identifying and recalling key clues. The preliminary experiments demonstrate their effectiveness, highlighting the need for further research and exploration.
Context-Aware Hierarchical Merging for Long Document Summarization
Feb 03, 2025



Hierarchical Merging is a technique commonly used to summarize very long texts ($>$100K tokens) by breaking down the input into smaller sections, summarizing those sections individually, and then merging or combining those summaries into a final coherent summary. Although it helps address the limitations of large language models (LLMs) with fixed input length constraints, the recursive merging process can amplify LLM hallucinations, increasing the risk of factual inaccuracies. In this paper, we seek to mitigate hallucinations by enriching hierarchical merging with context from the source document. Specifically, we propose different approaches to contextual augmentation ranging from \emph{replacing} intermediate summaries with relevant input context, to \emph{refining} them while using the context as supporting evidence, and \emph{aligning} them implicitly (via citations) to the input. Experimental results on datasets representing legal and narrative domains show that contextual augmentation consistently outperforms zero-shot and hierarchical merging baselines for the Llama 3.1 model family. Our analysis further reveals that refinement methods tend to perform best when paired with extractive summarization for identifying relevant input.
Chain-of-Thought Hub: A Continuous Effort to Measure Large Language Models' Reasoning Performance
May 26, 2023

As large language models (LLMs) are continuously being developed, their evaluation becomes increasingly important yet challenging. This work proposes Chain-of-Thought Hub, an open-source evaluation suite on the multi-step reasoning capabilities of large language models. We are interested in this setting for two reasons: (1) from the behavior of GPT and PaLM model family, we observe that complex reasoning is likely to be a key differentiator between weaker and stronger LLMs; (2) we envisage large language models to become the next-generation computational platform and foster an ecosystem of LLM-based new applications, this naturally requires the foundation models to perform complex tasks that often involve the composition of linguistic and logical operations. Our approach is to compile a suite of challenging reasoning benchmarks to track the progress of LLMs. Our current results show that: (1) model scale clearly correlates with reasoning capabilities; (2) As of May 2023, Claude-v1.3 and PaLM-2 are the only two models that are comparable with GPT-4, while open-sourced models still lag behind; (3) LLaMA-65B performs closely to code-davinci-002, indicating that with successful further development such as reinforcement learning from human feedback (RLHF), it has great potential to be close to GPT-3.5-Turbo. Our results also suggest that for the open-source efforts to catch up, the community may focus more on building better base models and exploring RLHF.
Specializing Smaller Language Models towards Multi-Step Reasoning
Jan 30, 2023The surprising ability of Large Language Models (LLMs) to perform well on complex reasoning with only few-shot chain-of-thought prompts is believed to emerge only in very large-scale models (100+ billion parameters). We show that such abilities can, in fact, be distilled down from GPT-3.5 ($\ge$ 175B) to T5 variants ($\le$ 11B). We propose model specialization, to specialize the model's ability towards a target task. The hypothesis is that large models (commonly viewed as larger than 100B) have strong modeling power, but are spread on a large spectrum of tasks. Small models (commonly viewed as smaller than 10B) have limited model capacity, but if we concentrate their capacity on a specific target task, the model can achieve a decent improved performance. We use multi-step math reasoning as our testbed because it is a very typical emergent ability. We show two important aspects of model abilities: (1). there exists a very complex balance/ tradeoff between language models' multi-dimensional abilities; (2). by paying the price of decreased generic ability, we can clearly lift up the scaling curve of models smaller than 10B towards a specialized multi-step math reasoning ability. We further give comprehensive discussions about important design choices for better generalization, including the tuning data format, the start model checkpoint, and a new model selection method. We hope our practice and discoveries can serve as an important attempt towards specialized smaller models in the new research paradigm set by LLMs.