 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo2Web: A Web Agent Benchmark Grounded in Egocentric Videos
Mar 23, 2026Multimodal AI agents are increasingly automating complex real-world workflows that involve online web execution. However, current web-agent benchmarks suffer from a critical limitation: they focus entirely on web-based interaction and perception, lacking grounding in the user's real-world physical surroundings. This limitation prevents evaluation in crucial scenarios, such as when an agent must use egocentric visual perception (e.g., via AR glasses) to recognize an object in the user's surroundings and then complete a related task online. To address this gap, we introduce Ego2Web, the first benchmark designed to bridge egocentric video perception and web agent execution. Ego2Web pairs real-world first-person video recordings with web tasks that require visual understanding, web task planning, and interaction in an online environment for successful completion. We utilize an automatic data-generation pipeline combined with human verification and refinement to curate well-constructed, high-quality video-task pairs across diverse web task types, including e-commerce, media retrieval, knowledge lookup, etc. To facilitate accurate and scalable evaluation for our benchmark, we also develop a novel LLM-as-a-Judge automatic evaluation method, Ego2WebJudge, which achieves approximately 84% agreement with human judgment, substantially higher than existing evaluation methods. Experiments with diverse SoTA agents on our Ego2Web show that their performance is weak, with substantial headroom across all task categories. We also conduct a comprehensive ablation study on task design, highlighting the necessity of accurate video understanding in the proposed task and the limitations of current agents. We hope Ego2Web can be a critical new resource for developing truly capable AI assistants that can seamlessly see, understand, and act across the physical and digital worlds.
Quantized but Deceptive? A Multi-Dimensional Truthfulness Evaluation of Quantized LLMs
Aug 26, 2025Quantization enables efficient deployment of large language models (LLMs) in resource-constrained environments by significantly reducing memory and computation costs. While quantized LLMs often maintain performance on perplexity and zero-shot tasks, their impact on truthfulness-whether generating truthful or deceptive responses-remains largely unexplored. In this work, we introduce TruthfulnessEval, a comprehensive evaluation framework for assessing the truthfulness of quantized LLMs across three dimensions: (1) Truthfulness on Logical Reasoning; (2) Truthfulness on Common Sense; and (3) Truthfulness on Imitative Falsehoods. Using this framework, we examine mainstream quantization techniques (ranging from 4-bit to extreme 2-bit) across several open-source LLMs. Surprisingly, we find that while quantized models retain internally truthful representations, they are more susceptible to producing false outputs under misleading prompts. To probe this vulnerability, we test 15 rephrased variants of "honest", "neutral" and "deceptive" prompts and observe that "deceptive" prompts can override truth-consistent behavior, whereas "honest" and "neutral" prompts maintain stable outputs. Further, we reveal that quantized models "know" the truth internally yet still produce false outputs when guided by "deceptive" prompts via layer-wise probing and PCA visualizations. Our findings provide insights into future designs of quantization-aware alignment and truthfulness interventions.
When Truthful Representations Flip Under Deceptive Instructions?
Jul 29, 2025Large language models (LLMs) tend to follow maliciously crafted instructions to generate deceptive responses, posing safety challenges. How deceptive instructions alter the internal representations of LLM compared to truthful ones remains poorly understood beyond output analysis. To bridge this gap, we investigate when and how these representations ``flip'', such as from truthful to deceptive, under deceptive versus truthful/neutral instructions. Analyzing the internal representations of Llama-3.1-8B-Instruct and Gemma-2-9B-Instruct on a factual verification task, we find the model's instructed True/False output is predictable via linear probes across all conditions based on the internal representation. Further, we use Sparse Autoencoders (SAEs) to show that the Deceptive instructions induce significant representational shifts compared to Truthful/Neutral representations (which are similar), concentrated in early-to-mid layers and detectable even on complex datasets. We also identify specific SAE features highly sensitive to deceptive instruction and use targeted visualizations to confirm distinct truthful/deceptive representational subspaces. % Our analysis pinpoints layer-wise and feature-level correlates of instructed dishonesty, offering insights for LLM detection and control. Our findings expose feature- and layer-level signatures of deception, offering new insights for detecting and mitigating instructed dishonesty in LLMs.
FAEDKV: Infinite-Window Fourier Transform for Unbiased KV Cache Compression
Jul 26, 2025



The efficacy of Large Language Models (LLMs) in long-context tasks is often hampered by the substantial memory footprint and computational demands of the Key-Value (KV) cache. Current compression strategies, including token eviction and learned projections, frequently lead to biased representations -- either by overemphasizing recent/high-attention tokens or by repeatedly degrading information from earlier context -- and may require costly model retraining. We present FAEDKV (Frequency-Adaptive Infinite-Window for KV cache), a novel, training-free KV cache compression framework that ensures unbiased information retention. FAEDKV operates by transforming the KV cache into the frequency domain using a proposed Infinite-Window Fourier Transform (IWDFT). This approach allows for the equalized contribution of all tokens to the compressed representation, effectively preserving both early and recent contextual information. A preliminary frequency ablation study identifies critical spectral components for layer-wise, targeted compression. Experiments on LongBench benchmark demonstrate FAEDKV's superiority over existing methods by up to 22\%. In addition, our method shows superior, position-agnostic retrieval accuracy on the Needle-In-A-Haystack task compared to compression based approaches.
HybridServe: Efficient Serving of Large AI Models with Confidence-Based Cascade Routing
May 18, 2025


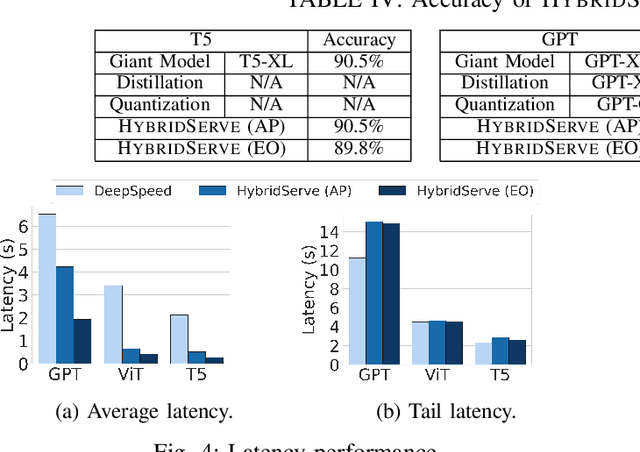
Giant Deep Neural Networks (DNNs), have become indispensable for accurate and robust support of large-scale cloud based AI services. However, serving giant DNNs is prohibitively expensive from an energy consumption viewpoint easily exceeding that of training, due to the enormous scale of GPU clusters needed to hold giant DNN model partitions and replicas. Existing approaches can either optimize energy efficiency or inference accuracy but not both. To overcome this status quo, we propose HybridServe, a novel hybrid DNN model serving system that leverages multiple sized versions (small to giant) of the model to be served in tandem. Through a confidence based hybrid model serving dataflow, HybridServe prefers to serve inference requests with energy-efficient smaller models so long as accuracy is not compromised, thereby reducing the number of replicas needed for giant DNNs. HybridServe also features a dataflow planner for efficient partitioning and replication of candidate models to maximize serving system throughput. Experimental results using a prototype implementation of HybridServe show that it reduces energy footprint by up to 19.8x compared to the state-of-the-art DNN model serving systems while matching the accuracy of serving solely with giant DNNs.
MoE-CAP: Benchmarking Cost, Accuracy and Performance of Sparse Mixture-of-Experts Systems
May 16, 2025The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently, but it depends on heterogeneous compute and memory resources. These factors jointly affect system Cost, Accuracy, and Performance (CAP), making trade-offs inevitable. Existing benchmarks often fail to capture these trade-offs accurately, complicating practical deployment decisions. To address this, we introduce MoE-CAP, a benchmark specifically designed for MoE systems. Our analysis reveals that achieving an optimal balance across CAP is difficult with current hardware; MoE systems typically optimize two of the three dimensions at the expense of the third-a dynamic we term the MoE-CAP trade-off. To visualize this, we propose the CAP Radar Diagram. We further introduce sparsity-aware performance metrics-Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU)-to enable accurate performance benchmarking of MoE systems across diverse hardware platforms and deployment scenarios.
MoE-CAP: Cost-Accuracy-Performance Benchmarking for Mixture-of-Experts Systems
Dec 10, 2024The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently; however, MoE systems rely on heterogeneous compute and memory resources. These factors collectively influence the system's Cost, Accuracy, and Performance (CAP), creating a challenging trade-off. Current benchmarks often fail to provide precise estimates of these effects, complicating practical considerations for deploying MoE systems. To bridge this gap, we introduce MoE-CAP, a benchmark specifically designed to evaluate MoE systems. Our findings highlight the difficulty of achieving an optimal balance of cost, accuracy, and performance with existing hardware capabilities. MoE systems often necessitate compromises on one factor to optimize the other two, a dynamic we term the MoE-CAP trade-off. To identify the best trade-off, we propose novel performance evaluation metrics - Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU) - and develop cost models that account for the heterogeneous compute and memory hardware integral to MoE systems. This benchmark is publicly available on HuggingFace: https://huggingface.co/spaces/sparse-generative-ai/open-moe-llm-leaderboard.
Dynamic Self-Distillation via Previous Mini-batches for Fine-tuning Small Language Models
Nov 25, 2024



Knowledge distillation (KD) has become a widely adopted approach for compressing large language models (LLMs) to reduce computational costs and memory footprints. However, the availability of complex teacher models is a prerequisite for running most KD pipelines. Thus, the traditional KD procedure can be unachievable or budget-unfriendly, particularly when relying on commercial LLMs like GPT4. In this regard, Self-distillation (SelfD) emerges as an advisable alternative, enabling student models to learn without teachers' guidance. Nonetheless, existing SelfD approaches for LMs often involve architectural modifications, assuming the models are open-source, which may not always be practical. In this work, we introduce a model-agnostic and task-agnostic method named dynamic SelfD from the previous minibatch (DynSDPB), which realizes current iterations' distillation from the last ones' generated logits. Additionally, to address prediction inaccuracies during the early iterations, we dynamically adjust the distillation influence and temperature values to enhance the adaptability of fine-tuning. Furthermore, DynSDPB is a novel fine-tuning policy that facilitates the seamless integration of existing self-correction and self-training techniques for small language models (SLMs) because they all require updating SLMs' parameters. We demonstrate the superior performance of DynSDPB on both encoder-only LMs (e.g., BERT model families) and decoder-only LMs (e.g., LLaMA model families), validating its effectiveness across natural language understanding (NLU) and natural language generation (NLG) benchmarks.
Interactive and Expressive Code-Augmented Planning with Large Language Models
Nov 21, 2024



Large Language Models (LLMs) demonstrate strong abilities in common-sense reasoning and interactive decision-making, but often struggle with complex, long-horizon planning tasks. Recent techniques have sought to structure LLM outputs using control flow and other code-adjacent techniques to improve planning performance. These techniques include using variables (to track important information) and functions (to divide complex tasks into smaller re-usable sub-tasks). However, purely code-based approaches can be error-prone and insufficient for handling ambiguous or unstructured data. To address these challenges, we propose REPL-Plan, an LLM planning approach that is fully code-expressive (it can utilize all the benefits of code) while also being dynamic (it can flexibly adapt from errors and use the LLM for fuzzy situations). In REPL-Plan, an LLM solves tasks by interacting with a Read-Eval-Print Loop (REPL), which iteratively executes and evaluates code, similar to language shells or interactive code notebooks, allowing the model to flexibly correct errors and handle tasks dynamically. We demonstrate that REPL-Plan achieves strong results across various planning domains compared to previous methods.
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Oct 14, 2024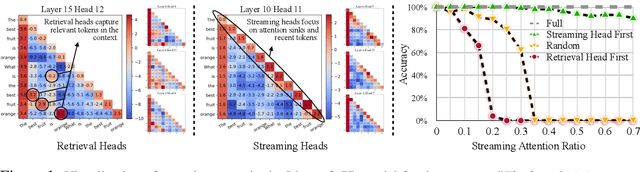
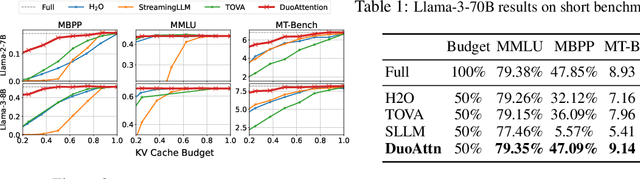
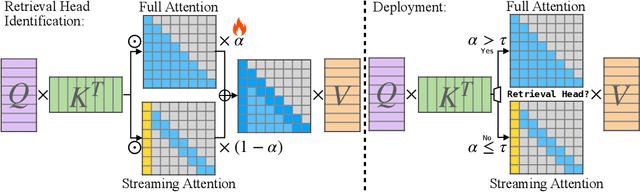

Deploying long-context large language models (LLMs) is essential but poses significant computational and memory challenges. Caching all Key and Value (KV) states across all attention heads consumes substantial memory. Existing KV cache pruning methods either damage the long-context capabilities of LLMs or offer only limited efficiency improvements. In this paper, we identify that only a fraction of attention heads, a.k.a, Retrieval Heads, are critical for processing long contexts and require full attention across all tokens. In contrast, all other heads, which primarily focus on recent tokens and attention sinks--referred to as Streaming Heads--do not require full attention. Based on this insight, we introduce DuoAttention, a framework that only applies a full KV cache to retrieval heads while using a light-weight, constant-length KV cache for streaming heads, which reduces both LLM's decoding and pre-filling memory and latency without compromising its long-context abilities. DuoAttention uses a lightweight, optimization-based algorithm with synthetic data to identify retrieval heads accurately. Our method significantly reduces long-context inference memory by up to 2.55x for MHA and 1.67x for GQA models while speeding up decoding by up to 2.18x and 1.50x and accelerating pre-filling by up to 1.73x and 1.63x for MHA and GQA models, respectively, with minimal accuracy loss compared to full attention. Notably, combined with quantization, DuoAttention enables Llama-3-8B decoding with 3.3 million context length on a single A100 GPU. Code is provided in https://github.com/mit-han-lab/duo-attention.